↧
Azure Marketplace new offers – Volume 35
↧
See the Road Ahead with Traffic Camera Images on Bing Maps
The Bing Maps Routing and Traffic Team is constantly working to make navigation and route planning easier! Hot on the heels of our previous announcement about traffic coloring, the Bing Maps team is proud to announce that we have made it possible for users to access traffic camera images along a planned driving route! You can now see traffic camera icons along a short to moderate-length route. By clicking on a traffic camera icon, you can view the latest image from the traffic camera at that location.
Confirming Traffic Conditions
In the example below, the orange colored segment of the route indicates that traffic on I-405 South is starting to get backed up. With traffic camera images now available, you can confirm local traffic conditions with just a click of the camera icon along the route.
Checking Extreme Weather Road Conditions
Gaining access to the traffic camera imagery not only helps with checking for traffic, accidents and general navigation, but can be invaluable to users when traversing areas impacted by extreme weather conditions, such as heavy snowfall, wind storms, flooding, etc.
Getting to and from the resort for your annual ski trip can become both challenging and dangerous when the roads are covered with snow and ice. This past February, Washington state was hit with unprecedented snowfall. Many sections of road near the Snoqualmie Pass were rendered impassible because of record amounts of snow, resulting in motorists getting stuck and stranded. With traffic camera images now accessible along the route, you can quickly check for dangerous road conditions before heading out.
In the example below, it snowed throughout the day at Alpental on April 13. The traffic camera image shows that the road was clear and safe for driving at 5:48 PM despite the snowfall.
Getting a look at the road ahead can help you avoid heavy traffic and tricky road conditions, so be sure to check out the “traffic” option with camera imagery on Bing Maps when you are routing your next trip at https://www.bing.com/maps/.
- Bing Maps Team
↧
↧
What’s new in Azure DevOps Sprint 150?
Sprint 150 has just finished rolling out to all organisations today and you can check out all the cool features in the release notes. Here is just a snapshot of some of the features that you can start using today.
Dark theme general availability
Last October, we released the public preview of the dark theme as part of the new navigation. After several months in preview, listening to feedback, and tuning the experience, we’re excited to announce the general availability of the dark theme. Let us know what you think!
Task assistant for editing YAML file
We continue to receive a lot of feedback asking to make it easier to edit YAML files for pipelines. Now we are adding a task assistant to the YAML editor. With this, you will have the same familiar experience for adding a new task to a YAML file as in the classic editor. This new assistant supports most of the common task input types such as pick lists and service connections. To use the new task assistant, select Edit on a YAML-based pipeline, and then select the Task assistant.
Share you team’s board using a badge
Now, you can add a badge for your team’s board in Azure Boards to your README. The badge can be configured to show only the ‘In Progress columns’ or ‘all columns’, and even be made visible publicly if your project is open source. 
General availability of Analytics
We’re excited to announce that the following Analytics features will be included in Azure DevOps at no additional cost.
- The Analytics Widgets are configurable modules that display data on a dashboard and help you monitor the progress of your work. The widgets included are the following:
- Burndown and Burnup charts monitor the progress of a set of scoped work over a period of time.
- Cycle Time and Lead Time to visualize how work moves through your team’s development cycle
- Cumulative Flow Diagram (CFD) tracks work items as they progress through various states.
- Velocity track how a team is delivering value over multiple sprints.
- Test Results Trend to monitor test trends, detect failure and duration patterns for tests over single or multiple pipelines.
- In the product we are including the top failing test report to get insights about top failing tests in your pipeline to help improve pipeline reliability and reduce test debt.
We will also continue to offer Power BI integration through analytics views and direct access to our OData endpoint in preview for all Azure DevOps Services customers. If you are using the Analytics marketplace extension, you can continue to use Analytics as you did before and do not need to follow any additional steps. This means that we will deprecate the Analytics marketplace extension for hosted customers. The Azure DevOps Analytics offering is the future of reporting and we will continue to invest in new features driven by Analytics. You can find more information about Analytics in the links below.
- Analytics overview documentation
- Analytics widgets
- Top failing test report
- Power BI integration
- OData endpoint
- Azure DevOps Analytics
These are just the tip of the iceberg, and there is plenty more that we’ve released in Sprint 150. Check out the full list of features for this sprint in the release notes.
The post What’s new in Azure DevOps Sprint 150? appeared first on Azure DevOps Blog.
↧
Pull Requests with Rebase
 We’re excited to roll out another way to integrate your pull requests in Azure Repos. Arriving in the Sprint 150 update is an option to rebase your pull request into the target branch. This lets you keep a linear commit history in your master branch, which many people think is an elegant way to visualize history.
We’re excited to roll out another way to integrate your pull requests in Azure Repos. Arriving in the Sprint 150 update is an option to rebase your pull request into the target branch. This lets you keep a linear commit history in your master branch, which many people think is an elegant way to visualize history.
Like tabs vs spaces, the way code gets integrated is the subject of heated debates on teams. Some people prefer merges, some people prefer rebase, and some people prefer a hybrid approach or even a “squash”. Azure Repos supports each of these scenarios:
Merge (no fast-forward)
This is the default integration strategy in Azure Repos, GitHub and most other Git providers. It emulates running git merge pr from the master branch. All the individual commits in the pull request branch are preserved as-is, and a new merge commit is created to unite the master branch and the pull request branch.

This strategy is helpful because it illustrates exactly how a developer (or developers) worked on a pull request, including each individual commit along the way. It gives the most insight into how a branch evolves, but since it preserves every commit is may be very verbose.
Squash commit
Squashing will take the tree that’s produced in a merge and creates a single new commit with those repository contents. It emulates running git merge pr --squash from the master branch. The resulting commit is not a merge commit; those individual commits that made up the pull request are discarded.

When this strategy is used, history is reminiscent of a centralized version control system. Each pull request becomes a single commit in master, and there are no merges, just a simple, straight, linear history. Individual commits are lost, which is best for teams that use “fix up” commits or do not carefully craft individual commits for review before pushing them.
Rebase
Rebase will take each individual commit in the pull request and cherry-pick them onto the master branch. It emulates running git rebase master on the pull reuqest branch, followed by git merge pr --ff-only on the master branch.

When this strategy is used, history is straight and linear, like it is with the “squash” option, but each individual commit is retained. This is useful for teams that practice careful commit hygeine, where each individual commit stands on its own.
Semi-linear merge
This strategy is the most exotic – it’s a mix of rebase and a merge. First, the commits in the pull request are rebased on top of the master branch. Then those rebased pull requests are merged into master branch. It emulates running git rebase master on the pull request branch, followed by git merge pr --no-ff on the master branch.

Some people think of this as the best of both worlds: individual commits are retained, so that you can see how the work evolved, but instead of just being rebased, a “merge bubble” is shown so that you can immediately see the work in each individual pull request.
Branch Policies
Many teams want to choose a pull request integration strategy and standardize on it for the whole team. Regardless of whether you prefer the rebase approach or the merge approach, it’s often helpful to use same approach for each pull request.
 Thankfully, you can configure a branch policy to enforce your preferred integration strategy (or strategies). Selecting only one will mean that pull requests into master will always use a single strategy.
Thankfully, you can configure a branch policy to enforce your preferred integration strategy (or strategies). Selecting only one will mean that pull requests into master will always use a single strategy.
And, of course, these branch policies that limit the merge types for a pull request are the perfect companion to the other branch policies. One that’s indispensible, of course, is the build validation branch policy, where you can set up an Azure Pipelines build for your master branch, and your build and tests must succeed before a pull request can be merged (or squashed, or rebased) into master.
The post Pull Requests with Rebase appeared first on Azure DevOps Blog.
↧
Migrating SAP applications to Azure: Introduction and our partnership with SAP
↧
↧
Best practices in migrating SAP applications to Azure – part 1
↧
Customize your Azure best practice recommendations in Azure Advisor
Cloud optimization is critical to ensuring you get the most out of your Azure investment, especially in complex environments with many Azure subscriptions and resource groups. Azure Advisor helps you optimize your Azure resources for high availability, security, performance, and cost by providing free, personalized recommendations based on your Azure usage and configurations.
In addition to consolidating your Azure recommendations into a single place, Azure Advisor has a configuration feature that can help you focus exclusively on your most important resources, such as those in production, and save you remediation time. You can also configure thresholds for certain recommendations based on your business needs.
Save time by configuring Advisor to display recommendations only for resources that matter to you
You can configure Azure Advisor to provide recommendations exclusively for the subscriptions and resource groups you specify. By narrowing your Advisor recommendations down to the resources that matter the most to you, you can save time optimizing your Azure workloads. To get you started we’ve created a step-by-step guide on how to configure Advisor in the Azure portal (UI). To learn how to configure Advisor in the command line (CLI), see our documentation, “az advisor configuration.”

Please note that there’s a difference between Advisor configuration and the filtering options available in the Azure portal. Configuration is persistent and prevents recommendations from showing for the unselected scope (shown in the screenshot above). Filtering in the UI (shown in the screenshot below) temporarily displays a subset of recommendations. Available UI filters include subscription, service, and active versus postponed recommendations.

Configuring thresholds for cost recommendations to find savings
You can also customize the CPU threshold for one of our most popular recommendations, “Right-size or shutdown underutilized virtual machines,” which analyzes your usage patterns and identifies virtual machines (VMs) with low usage. While certain scenarios can result in low utilization by design, you can often save money by managing the size and number of your VMs.

You can modify the average CPU utilization threshold Advisor uses for this recommendation to a higher or lower value so you can find more savings depending on your business needs.

Get started with Azure Advisor
Review your Azure Advisor recommendations and customize your Advisor configurations now. If you need help getting started, check our Advisor documentation. We always welcome feedback. Submit your ideas or email us with any questions or comments at advisorfeedback@microsoft.com.
↧
Quantifying the value of collaboration with Microsoft Teams
What Forrester learned from studying the benefits of Microsoft Teams across more than 260 organizations.
The post Quantifying the value of collaboration with Microsoft Teams appeared first on Microsoft 365 Blog.
↧
AI for Good: Developer challenge!

Do you have an idea that could improve and empower the lives of everyone in a more accessible way? Or perhaps you have an idea that would help create a sustainable balance between modern society and the environment? Even if it’s just the kernel of an idea, it’s a concept worth exploring with the AI for Good Idea Challenge!
If you’re a developer, a data scientist, a student of AI, or even just passionate about AI and machine learning, we encourage you to take part in the AI for Good: Developer challenge and improve the world by sharing your ideas. Upload your project today and be in the running to win some truly exciting prizes!
What is the AI for Good: Idea challenge?
The challenge is to come up with an idea that uses AI for the greater good, for example improve environmental sustainability, or help to empower people with disabilities. We’re accepting submissions between now and June 26, 2019, so get your thinking cap on!
Below are some thought starters on AI for sustainability and accessibility topics.
Environmental sustainability ideas could focus around:
- Agriculture: Helping to monitor health of farms, crop protection.
- Biodiversity: Accelerating the discovery, monitoring, and protection of biodiversity across our planet.
- Climate change: Giving people more accurate climate predictions to help reduce the potential impacts.
- Water: Intelligent systems to analyze water, modelling the Earth's water supply to help us conserve and protect fresh water.
Ideas around the empowerment of people with disabilities could address:
- Employment: Helping people develop professional skills, influencing workplace culture and inclusive hiring.
- Daily life: Using AI for hearing, seeing, and reasoning with increased accuracy to help people with everyday tasks.
- Communication and connection: Ensuring equal access to information and opportunities for all people regardless of how they listen, speak, or write.
What can I win?
As well as the opportunity to have their idea fully developed and showcased on Microsoft’s AI Lab website, the winners of the contest will receive the following:
| For the 1st place, $10,000 Azure credits and a Surface Book 2. |  |
| For the 2nd place, $5,000 Azure credits and a Nvidia GPU Quadro K6000. |  |
| For the 3rd place, $2,500 Azure credits and an XBOX-One. |  |
How is it judged?
In a nutshell, the ideas you’d submit will be judged by a panel of Microsoft experts based on the originality of your idea and its potential impact on society (50 percent), the feasibility of your solution (20 percent), and the complexity to implement (30 percent).
The selection process is the following:
1. Submit your entry
Upload your project. Follow the instructions to register and submit your entry.
2. Idea review
A panel of Microsoft judges will review your submission.
3. Winner announcement
Winners will be announced within 14 days after contest closes.
4. Prizes
The top three winners of the Idea Challenge will win great prizes and a chance to present their fully developed idea on Microsoft’s AI Lab website.
How do I get started?
Don’t know where to start? Want some more ideas? Check out the AI Idea Challenge cheat sheet on AI School for some tips on what’s out there. If you already have an idea, feel free to submit it here for your chance to win.
Happy coding!
For additional details, see the contest Terms and Conditions.
↧
↧
Introducing Security Policy Advisor—a new service to manage your Office 365 security policies
Announcing the public preview of Security Policy Advisor, a new intelligent service that helps IT admins improve the security of Office 365 ProPlus clients by providing recommended security policies tailored to that specific group.
The post Introducing Security Policy Advisor—a new service to manage your Office 365 security policies appeared first on Microsoft 365 Blog.
↧
Python in Visual Studio Code – April 2019 Release
We are pleased to announce that the April 2019 release of the Python Extension for Visual Studio Code is now available. You can download the Python extension from the Marketplace, or install it directly from the extension gallery in Visual Studio Code. You can learn more about Python support in Visual Studio Code in the documentation.
In this release we made a series of improvements that are listed in our changelog, closing a total of 84 issues including:
- Variable Explorer and Data Viewer
- Enhancements to debug configuration
- Additional improvements to the Python Language Server
Keep on reading to learn more!
Variable Explorer and Data Viewer
The Python Interactive experience now comes with a built-in variable explorer along with a data viewer, a highly requested feature from our users. Now you can easily view, inspect and filter the variables in your application, including lists, NumPy arrays, pandas data frames, and more!
A variables section will now be shown when running code and cells in the Python Interactive window. Once you expand it, you’ll see the list of the variables in the current Jupyter session. More variables will show up automatically as they get used in the code. Clicking on each column header will sort the variables in the table.

You can also double-click on each row or use the “Show variable in data viewer” button to view full data of each variable in the newly-added Data Viewer, as well as perform simple search over its values:

The Data Viewer requires pandas package 0.20 or later, and you will get a message to install or upgrade if it’s not available.
The Variable Explore is enabled by default. You can turn it off through File > Preferences > Settings and looking for the Python > Data Science: Show Jupyter Variable Explorer setting.
Enhancements to debug configuration
We simplified the process of configuring the debugger for your workspace. When you start debugging (through the Debug Panel, F5 or Debug > Start Debugging) and no debug configuration exists, you now will be prompted to create a debug configuration for your application. Creating a debug configuration is accomplished through a set of menus, instead of manually configuring the launch.json file.

This prompt will also be displayed when adding another debug configuration through the launch.json file:

Additional improvements to the Python Language Server
This release includes several fixes and improvements to the Python Language Server. We added back features that were removed in the 0.2 release: “Rename Symbol”, “Go to Definition” and “Find All References”, and made improvements to loading time and memory usage when importing scientific libraries such as pandas, Plotly, PyQt5 , especially when running in full Anaconda environments.
To opt-in to the Language Server, change the python.jediEnabled setting to false in File > Preferences > User Settings. We are working towards making the language server the default in the next few releases, so if you run into problems, please file an issue on the Python Language Server GitHub page.
Other Changes and Enhancements
We have also added small enhancements and fixed issues requested by users that should improve your experience working with Python in Visual Studio Code. Some notable changes include:
- Change default behavior of debugger to display return values. (#3754)
- Change “Unit Test” phrasing to “Test” or “Testing”. (#4384)
- Replace setting debugStdLib with justMyCode. (#4032)
- Add setting to just enable/disable the data science codelens. (#5211)
- Improved reliability of test discovery when using pytest. (#4795)
- Updates to README file.
Be sure to download the Python extension for Visual Studio Code now to try out the above improvements. If you run into any problems, please file an issue on the Python VS Code GitHub page.
The post Python in Visual Studio Code – April 2019 Release appeared first on Python.
↧
Visual Studio C++ Template IntelliSense Populates Based on Instantiations in Your Code
Ever since we announced Template IntelliSense, you all have given us great suggestions. One very popular suggestion was to have the Template Bar auto-populate candidates based on instantiations in your code. In Visual Studio 2019 version 16.1 Preview 2, we’ve added this functionality via an “Add All Existing Instantiations” option in the Template Bar dropdown menu. The following examples are from the SuperTux codebase.

The Template Bar dropdown menu now contains a new entry, “Add All Existing Instantiations”.

Clicking the “Add All Existing Instantiations” option will populate the dropdown, so you no longer need to manually type entries.

Additionally, similar to Find All References, a window at the bottom of the editor shows you where each instantiation was found, and what its arguments were.

Talk to Us!
We hope this update addresses the popular customer feedback we received on Template IntelliSense! We’d love for you to download Visual Studio 2019 version 16.1 Preview 2 and let us know what you think. We can be reached via the comments below or via email (visualcpp@microsoft.com). If you encounter other problems with Visual Studio or have other suggestions you can use the Report a Problem tool in Visual Studio or head over to the Visual Studio Developer Community. You can also find us on Twitter (@VisualC).
The post Visual Studio C++ Template IntelliSense Populates Based on Instantiations in Your Code appeared first on C++ Team Blog.
↧
Dear Spark developers: Welcome to Azure Cognitive Services

This post was co-authored by Mark Hamilton, Sudarshan Raghunathan, Chris Hoder, and the MMLSpark contributors.
Integrating the power of Azure Cognitive Services into your big data workflows on Apache Spark™
Today at Spark AI Summit 2019, we're excited to introduce a new set of models in the SparkML ecosystem that make it easy to leverage the Azure Cognitive Services at terabyte scales. With only a few lines of code, developers can embed cognitive services within your existing distributed machine learning pipelines in Spark ML. Additionally, these contributions allow Spark users to chain or Pipeline services together with deep networks, gradient boosted trees, and any SparkML model and apply these hybrid models in elastic and serverless distributed systems.
From image recognition to object detection using speech recognition, translation, and text-to-speech, Azure Cognitive Services makes it easy for developers to add intelligent capabilities to their applications in any scenario. To this date, more than a million developers have already discovered and tried Cognitive Services to accelerate breakthrough experiences in their application.
Azure Cognitive Services on Apache Spark™
Cognitive Services on Spark enable working with Azure’s Intelligent Services at massive scales with the Apache Spark™ distributed computing ecosystem. The Cognitive Services on Spark are compatible with any Spark 2.4 cluster such as Azure Databricks, Azure Distributed Data Engineering Toolkit (AZTK) on Azure Batch, Spark in SQL Server, and Spark clusters on Azure Kubernetes Service. Furthermore, we provide idiomatic bindings in PySpark, Scala, Java, and R (Beta).
Cognitive Services on Spark allows users to embed general purpose and continuously improve intelligent models directly into their Apache Spark™ and SQL computations. This contribution aims to liberate developers from low-level networking details, so they can focus on creating intelligent, distributed applications. Each Cognitive Service is a SparkML transformer, so users can add services to existing SparkML pipelines. We also introduce a new type of API to the SparkML framework that allows users to parameterize models by either a single scalar, or a column of a distributed spark DataFrame. This API yields a succinct, yet powerful fluent query language that offers a full distributed parameterization without clutter. For more information, check out our session.
Use Azure Cognitive Services on Spark in these 3 simple steps:
- Create an Azure Cognitive Services Account
- Install MMLSpark on your Spark Cluster
- Try our example notebook
Low-latency, high-throughput workloads with the cognitive service containers

The cognitive services on Spark are compatible with services from any region of the globe, however many scenarios require low or no-connectivity and ultra-low latency. To tackle these with the cognitive services on Spark, we have recently released several cognitive services as docker containers. These containers enable running cognitive services locally or directly on the worker nodes of your cluster for ultra-low latency workloads. To make it easy to create Spark Clusters with embedded cognitive services, we have created a Helm Chart for deploying a Spark clusters onto the popular container orchestration platform Kubernetes. Simply point the Cognitive Services on Spark at your container’s URL to go local!
Add any web service to Apache Spark™ with HTTP on Spark

The Cognitive Services are just one example of using networking to share software across ecosystems. The web is full of HTTP(S) web services that provide useful tools and serve as one of the standard patterns for making your code accessible in any language. Our goal is to allow Spark developers to tap into this richness from within their existing Spark pipelines.
To this end, we present HTTP on Spark, an integration between the entire HTTP communication protocol and Spark SQL. HTTP on Spark allows Spark users to leverage the parallel networking capabilities of their cluster to integrate any local, docker, or web service. At a high level, HTTP on Spark provides a simple and principled way to integrate any framework into the Spark ecosystem.
With HTTP on Spark, users can create and manipulate their requests and responses using SQL operations, maps, reduces, filters, and any tools from the Spark ecosystem. When combined with SparkML, users can chain services together and use Spark as a distributed micro-service orchestrator. HTTP on Spark provides asynchronous parallelism, batching, throttling, and exponential back-offs for failed requests so that you can focus on the core application logic.
Real world examples
The Metropolitan Museum of Art

At Microsoft, we use HTTP on Spark to power a variety of projects and customers. Our latest project uses the Computer Vision APIs on Spark and Azure Search on Spark to create a searchable database of Art for The Metropolitan Museum of Art (The MET). More Specifically, we load The MET’s Open Access catalog of images, and use the Computer Vision APIs to annotate these images with searchable descriptions in parallel. We also used CNTK on Spark, and SparkML’s Locality Sensitive Hash implementation to futurize these images and create a custom reverse image search engine. For more information on this work, check out our AI Lab or our Github.

The Snow Leopard Trust
We partnered with the Snow Leopard Trust to help track and understand the endangered Snow Leopard population using the Cognitive Services on Spark. We began by creating a fully labelled training dataset for leopard classification by pulling snow leopard images from Bing on Spark. We then used CNTK and Tensorflow on Spark to train a deep classification system. Finally, we interpreted our model using LIME on Spark to refine our leopard classifier into a leopard detector without drawing a single bounding box by hand! For more information, you can check out our blog post.

Conclusion
With only a few lines of code you can start integrating the power of Azure Cognitive Services into your big data workflows on Apache Spark™. The Spark bindings offer high throughput and run anywhere you run Spark. The Cognitive Services on Spark fully integrate with containers for high performance, on premises, or low connectivity scenarios. Finally, we have provided a general framework for working with any web service on Spark. You can start leveraging the Cognitive Services for your project
with our open source initiative MMLSpark on Azure Databricks.
Learn more
Email: mmlspark-support@microsoft.com
↧
↧
Azure Notification Hubs and Google’s Firebase Cloud Messaging Migration
When Google announced its migration from Google Cloud Messaging (GCM) to Firebase Cloud Messaging (FCM), push services like Azure Notification Hubs had to adjust how we send notifications to Android devices to accommodate the change.
We updated our service backend, then published updates to our API and SDKs as needed. With our implementation, we made the decision to maintain compatibility with existing GCM notification schemas to minimize customer impact. This means that we currently send notifications to Android devices using FCM in FCM Legacy Mode. Ultimately, we want to add true support for FCM, including the new features and payload format. That is a longer-term change and the current migration is focused on maintaining compatibility with existing applications and SDKs. You can use either the GCM or FCM libraries in your app (along with our SDK) and we make sure the notification is sent correctly.
Some customers recently received an email from Google warning about apps using a GCM endpoint for notifications. This was just a warning, and nothing is broken – your app’s Android notifications are still sent to Google for processing and Google still processes them. Some customers who specified the GCM endpoint explicitly in their service configuration were still using the deprecated endpoint. We had already identified this gap and were working on fixing the issue when Google sent the email.
We replaced that deprecated endpoint and the fix is deployed.
If your app uses the GCM library, go ahead and follow Google’s instructions to upgrade to the FCM library in your app. Our SDK is compatible with either, so you won’t have to update anything in your app on our side (as long as you’re up to date with our SDK version).
Now, this isn’t how we want things to stay; so over the next year you’ll see API and SDK updates from us implementing full support for FCM (and likely deprecate GCM support). In the meantime, here’s some answers to common questions we’ve heard from customers:
Q: What do I need to do to be compatible by the cutoff date (Google’s current cutoff date is May 29th and may change)?
A: Nothing. We will maintain compatibility with existing GCM notification schema. Your GCM key will continue to work as normal as will any GCM SDKs and libraries used by your application.
If/when you decide to upgrade to the FCM SDKs and libraries to take advantage of new features, your GCM key will still work. You may switch to using an FCM key if you wish, but ensure you are adding Firebase to your existing GCM project when creating the new Firebase project. This will guarantee backward compatibility with your customers that are running older versions of the app that still use GCM SDKs and libraries.
If you are creating a new FCM project and not attaching to the existing GCM project, once you update Notification Hubs with the new FCM secret you will lose the ability to push notifications to your current app installations, since the new FCM key has no link to the old GCM project.
Q: Why am I getting this email about old GCM endpoints being used? What do I have to do?
A: Nothing. We have been migrating to the new endpoints and will be finished soon, so no change is necessary. Nothing is broken, our one missed endpoint simply caused warning messages from Google.
Q: How can I transition to the new FCM SDKs and libraries without breaking existing users?
A: Upgrade at any time. Google has not yet announced any deprecation of existing GCM SDKs and libraries. To ensure you don't break push notifications to your existing users, make sure when you create the new Firebase project you are associating with your existing GCM project. This will ensure new Firebase secrets will work for users running the older versions of your app with GCM SDKs and libraries, as well as new users of your app with FCM SDKs and libraries.
Q: When can I use new FCM features and schemas for my notifications?
A: Once we publish an update to our API and SDKs, stay tuned – we expect to have something for you in the coming months.
Learn more about Azure Notification Hubs and get started today.
↧
5 tips to get more out of Azure Stream Analytics Visual Studio Tools
Azure Stream Analytics is an on-demand real-time analytics service to power intelligent action. Azure Stream Analytics tools for Visual Studio make it easier for you to develop, manage, and test Stream Analytics jobs. This year we provided two major updates in January and March, unleashing new useful features. In this blog we’ll introduce some of these capabilities and features to help you improve productivity.
Test partial scripts locally
In the latest March update we enhanced local testing capability. Besides running the whole script, now you can select part of the script and run it locally against the local file or live input stream. Click Run Locally or press F5/Ctrl+F5 to trigger the execution. Note that the selected portion of the larger script file must be a logically complete query to execute successfully.

Share inputs, outputs, and functions across multiple scripts
It is very common for multiple Stream Analytics queries to use the same inputs, outputs, or functions. Since these configurations and code are managed as files in Stream Analytics projects, you can define them only once and then use them across multiple projects. Right-click on the project name or folder node (inputs, outputs, functions, etc.) and then choose Add Existing Item to specify the input file you already defined. You can organize the inputs, outputs, and functions in a standalone folder outside your Stream Analytics projects to make it easy to reference in various projects.

Duplicate a job to other regions
All Stream Analytics jobs running in the cloud are listed in Server Explorer under the Stream Analytics node. You can open Server Explorer by choosing from the View menu.

If you want to duplicate a job to another region, just right-click on the job name and export it to a local Stream Analytics project. Since the credentials cannot be downloaded to local environment, you must specify the correct credentials in the job inputs and outputs files. After that, you are ready to submit the job to another region by clicking Submit to Azure in the script editor.


Local input schema auto-completion
If you have specified a local file for an input to your script, the IntelliSense feature will suggest input column names based on the actual schema of your data file.

Testing queries against SQL database as reference data
Azure Stream Analytics supports Azure SQL Database as an input source for reference data. When you add a reference input using SQL Database, two SQL files are generated as code, behind files under your input configuration file.

In Visual Studio 2017 or 2019, if you have already installed SQL Server Data tools, you can directly write the SQL query and test by clicking Execute in the query editor. A wizard window will pop up to help you connect to the SQL database and show the query result in the window at the bottom.

Providing feedback and ideas
The Azure Stream Analytics team is committed to listening to your feedback. We welcome you to join the conversation and make your voice heard via our UserVoice. For tools feedback, you can also reach out to ASAToolsFeedback@microsoft.com.
Also, follow us @AzureStreaming to stay updated on the latest features.
↧
Spark + AI Summit – Developing for the intelligent cloud and intelligent edge
We are truly at a unique tipping point in the history of technology. The pace of growth is more rapid than ever before, with estimates of more than 150B connected devices and data growth up to 175 Zettabytes by 20251. With the dramatic acceleration of digitization, the primary question we now face is how to take advantage of the data and capabilities at our fingertips to help our companies and communities transform.
We see a massive opportunity powered by the intelligent cloud and intelligent edge. The intelligent cloud is ubiquitous computing at massive scale, enabled by the public cloud and powered by AI, for every type of application one can envision. The intelligent edge is a continually expanding set of connected systems and devices that gather and analyze data—close to your users, the data, or both.
Enabling intelligent cloud and intelligent edge solutions requires a new class of distributed, connected applications. Fundamentally, a cloud/edge application must be developed and run as a single environment. Azure provides a unified, comprehensive platform from the cloud to the edge, with a consistent app platform, holistic security, single identity controls, and simplified cloud and edge management.
We are also bringing the latest innovations in machine learning and artificial intelligence to the intelligent cloud and intelligent edge. Azure enables you to combine data in the cloud and at the edge to develop ML models and distribute them across a massive set of certified devices. Tapping into contextual insights from the edge provides ML models more robust data and thus better results.

Investing in open source to fuel innovation
Today, at the Spark + AI Summit in San Francisco, I had the opportunity to share several exciting announcements on how we are building upon these cloud/edge capabilities and are deeply investing in the open source community.
Azure Machine Learning support for MLflow
First, we are excited to join the open source MLflow project as an active contributor. Azure Machine Learning—a popular machine learning service enabling Azure customers to build, train, and deploy machine learning models—will support open source MLflow to provide customers with maximum flexibility. This means that developers can use the standard MLflow tracking API to track runs and deploy models directly into Azure Machine Learning service.
Managed MLflow and Managed Delta Lake in Azure Databricks
Furthermore, we are excited to announce that managed MLflow is generally available on Azure Databricks and will use Azure Machine Learning to track the full ML lifecycle. This approach enables organizations to develop and maintain their machine learning lifecycle using a single model registry on Azure. The combination of Azure Databricks and Azure Machine Learning makes Azure the best cloud for machine learning. In addition to being able to deploy models from the cloud to the edge, customers benefit from an optimized, autoscaling Apache Spark based environment, collaborative workspace, automated machine learning, and end-to-end Machine Learning Lifecycle management.
Additionally, today, Databricks open sourced Databricks Delta, now known as Delta Lake. Delta Lake is an engine built on top of Apache Spark for optimizing data pipelines. With Delta Lake, Azure Databricks customers get greater reliability, improved performance, and the ability to simplify their data pipelines.
Azure Databricks customers have been experiencing the benefits of the Delta engine in general availability since February, and they will continue to enjoy the innovations from the community going forward with the open source Delta Lake project.
.NET for Apache Spark™
We are excited to be making Apache Spark accessible to the .NET developer ecosystem with .NET for Apache Spark. We’re seeing incredible growth with .NET, which is actively used by millions of developers, with over 1 million new developers coming to the platform in the last year. .NET for Apache Spark is free, open source, and .NET Standard compliant, which means you can use it anywhere you write .NET code.
.NET for Apache Spark provides high performance DataFrame-level APIs for using Apache Spark from C# and F#. With these .NET APIs, you can access all aspects of Apache Spark including Spark SQL, for working with structured data, and Spark Streaming. Additionally, .NET for Apache Spark allows you to register and call user-defined functions written in .NET at scale. With .NET for Apache Spark, you can reuse all the knowledge, skills, code, and libraries you already have as a .NET developer.
Microsoft is committed to engaging closely with the Apache Spark community to grow this project and enable more developers to use Apache Spark.
Bringing the intelligent cloud and the intelligent edge to life
Many of our customers are already bringing the power of the intelligent cloud and the intelligent edge to life in innovative new ways.
Anheuser-Busch InBev is brewing up game-changing business solutions with Azure IoT and AI services. With its RFID program, AB InBev tracks pallets of beer from the brewery to the wholesaler to the retailer in order to optimize inventory, reduce out-of-stock scenarios, and better forecast future retailer consumption trends.
“With the Azure platform and services, we’re transforming how we do business, interact with our suppliers, and connect with our customers.”
— Chetan Kundavaram, Global Director, Anheuser-Busch InBev
Schneider Electric is breaking new ground with new methods for proactively identifying pump problems in real-time through predictive edge analytics. By deploying predictive models to edge devices with Azure Machine Learning and Azure IoT Edge, they can shut down pumps before damages occur, protecting machinery and preventing potential environmental damage.
“In some critical systems—whether at an oil pump or in a manufacturing plant—you may have to make a decision in a matter of milliseconds. By building machine learning algorithms into our applications and deploying analytics at the edge, we reduce any communication latency to the cloud or a central system, and that critical decision can happen right away.”
— Matt Boujonnier, Analytics Application Architect, Schneider Electric
AccuWeather, a leading global provider of weather forecasts, leverages Azure AI services to create custom weather-impact predictions to help people plan their lives, protect their businesses, and stay safe. To develop highly accurate forecasts, AccuWeather depends on Azure’s machine learning tools, customizable with R and Python code.
“Azure really stands out from other clouds by providing out-of-the-box machine learning capabilities that are powerful yet customizable using R and Python. It’s very important to our data scientists to have a cloud platform that plays well with open source, and that was one of the things that attracted us to Azure.”
— Rosemary Yeilding Radich, Director of Data Science, AccuWeather
It has been incredible to see our customers leverage AI to drive digital transformation across industries. But even beyond transforming businesses, what has truly inspired us is determining how the power of AI can be used toward creating a more sustainable and accessible world. We developed a program called AI for Accessibility focused on leveraging the power of AI to amplify human capability for the more than one billion people globally who are differently abled. Today at the Spark + AI Summit, we were excited to showcase Seeing AI, a Microsoft research project designed for the low vision community that harnesses the power of AI to describe people, text, and objects. We truly believe that technology can empower everyone to achieve more, and look forward to the new wave of possibilities that AI brings to life.
We are committed to delivering the latest innovations across cloud and edge into the hands of every developer and data scientist to enable new possibilities with data. We can’t wait to see what you build next.
1IDC White Paper, Data Age 2025. The Digitization of the World: From Edge to Core.
↧
Governance setting for cache refreshes from Azure Analysis Services
↧
↧
Introducing .NET for Apache® Spark™ Preview
Today at Spark + AI summit we are excited to announce .NET for Apache Spark. Spark is a popular open source distributed processing engine for analytics over large data sets. Spark can be used for processing batches of data, real-time streams, machine learning, and ad-hoc query.
.NET for Apache Spark is aimed at making Apache® Spark accessible to .NET developers across all Spark APIs. So far Spark has been accessible through Scala, Java, Python and R but not .NET.
accessible to .NET developers across all Spark APIs. So far Spark has been accessible through Scala, Java, Python and R but not .NET.
We plan to develop .NET for Apache Spark in the open along with the Spark and .NET community to ensure that developers get the best of both worlds.

https://github.com/dotnet/spark Star
The remainder of this post provides more specifics on the following topics:
- What is .NET For Apache Spark?
- Getting Started with .NET for Apache Spark
- .NET for Apache Spark performance
- What’s next with .NET For Apache Spark
- Wrap Up
What is .NET for Apache Spark?
.NET for Apache Spark provides high performance APIs for using Spark from C# and F#. With this .NET APIs, you can access all aspects of Apache Spark including Spark SQL, DataFrames, Streaming, MLLib etc. .NET for Apache Spark lets you reuse all the knowledge, skills, code, and libraries you already have as a .NET developer.
The C#/ F# language binding to Spark will be written on a new Spark interop layer which offers easier extensibility. This new layer of Spark interop was written keeping in mind best practices for language extension and optimizes for interop and performance. Long term this extensibility can be used for adding support for other languages in Spark.
You can learn more details about this work through this proposal.
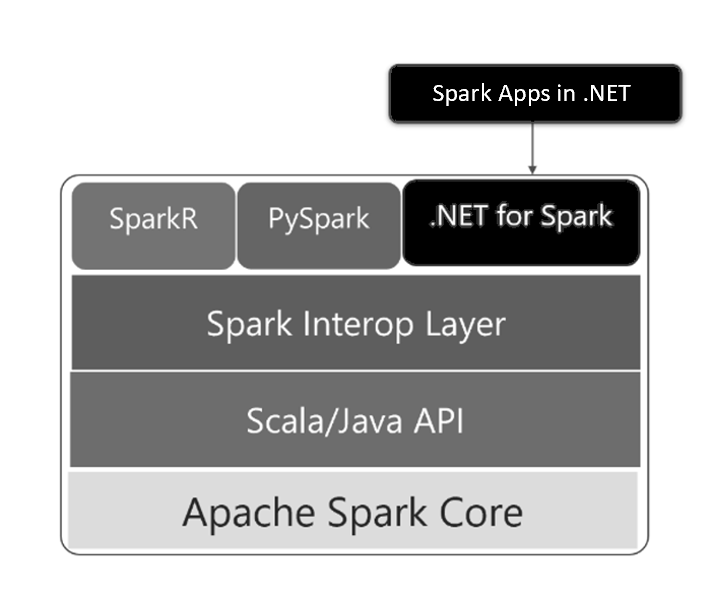
.NET for Apache Spark is compliant with .NET Standard 2.0 and can be used on Linux, macOS, and Windows, just like the rest of .NET. .NET for Apache Spark is available by default in Azure HDInsight, and can be installed in Azure Databricks and more.
Getting Started with .NET for Apache Spark
Before you can get started with .NET for Apache Spark, you do need to install a few things. Follow these steps to get started with .NET for Apache Spark
Once setup, you can start programming Spark applications in .NET with three easy steps.
In our first .NET Spark application we will write a basic Spark pipeline which counts the occurrence of each word in a text segment.
// 1. Create a Spark session
var spark = SparkSession
.Builder()
.AppName("word_count_sample")
.GetOrCreate();
// 2. Create a DataFrame
DataFrame dataFrame = spark.Read().Text("input.txt");
// 3. Manipulate and view data
var words = dataFrame.Select(Split(dataFrame["value"], " ").Alias("words"));
words.Select(Explode(words["words"])
.Alias("word"))
.GroupBy("word")
.Count()
.Show();
.NET for Apache Spark performance
We are pleased to say that the first preview version of .NET for Apache Spark performs well on the popular TPC-H benchmark. The TPC-H benchmark consists of a suite of business oriented queries. The chart below illustrates the performance of .NET Core versus Python and Scala on the TPC-H query set.
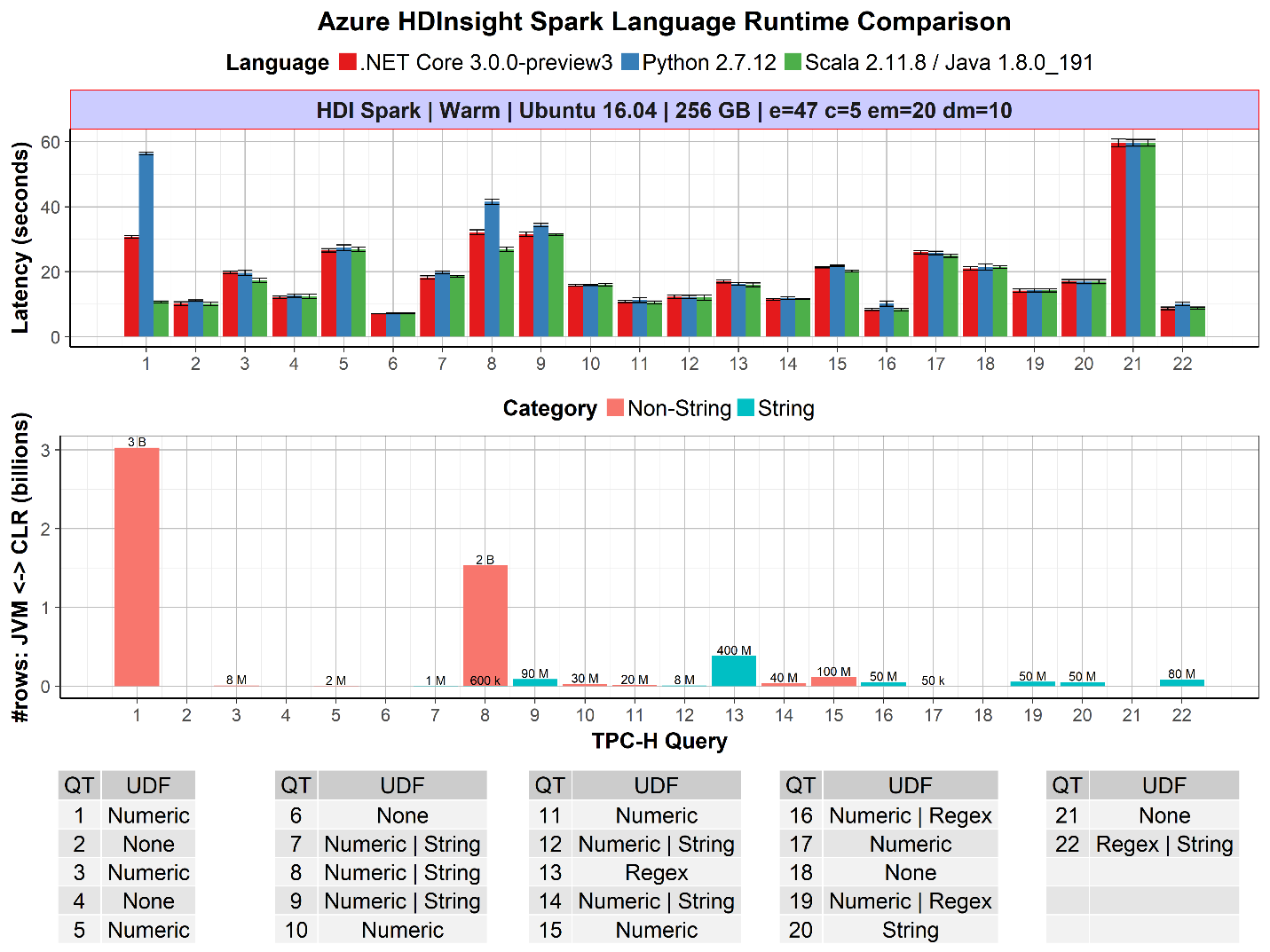
The chart above shows the per query performance of .NET for Apache Spark versus Python and Scala. .NET for Apache Spark performs well against Python and Scala . Furthermore, in cases where UDF performance is critical such as query 1 where 3B rows of non-string data is passed between the JVM and the CLR .NET for Apache Spark is 2x faster than Python.
It’s also important to call out that this is our first preview of .NET for Apache Spark and we aim to further invest in improving performance. You can follow our instructions to benchmark this on our GitHub repo.
What’s next with .NET For Apache Spark
Today marks the first step in our journey. Following are some features on our near-term roadmap. Please follow the full roadmap on our GitHub repo.
- Simplified getting started experience, documentation and samples
- Native integration with developer tools such as Visual Studio, Visual Studio Code, Jupyter notebooks
- .NET support for user-defined aggregate functions
- .NET idiomatic APIs for C# and F# (e.g., using LINQ for writing queries)
- Out of the box support with Azure Databricks, Kubernetes etc.
- Make .NET for Apache Spark part of Spark Core. You can follow this
progress here.
See something missing on this list, please drop us a comment below
Wrap Up
.NET for Apache Spark is our first step in making .NET a great tech stack for building Big Data applications.
We need your help to shape the future of .NET for Apache Spark, we look forward to seeing what you build with .NET for Apache Spark. You can provide reach out to us through our GitHub repo.
https://github.com/dotnet/spark Star
This blog is authored by Rahul Potharaju, Ankit Asthana, Tyson Condie, Terry Kim, Dan Moseley, Michael Rys and the rest of the .NET for Apache Spark team.
The post Introducing .NET for Apache® Spark™ Preview appeared first on .NET Blog.
↧
Improved C++ IntelliCode now Ships with Visual Studio 2019
IntelliCode support for C++ previously shipped as an extension, but it is now an in-box component that installs with the “Desktop Development with C++” workload in Visual Studio 2019 16.1 Preview 2. Make sure that IntelliCode is active for C++ by enabling the “C++ base model” under Tools > Options > IntelliCode > General: 
This version of C++ IntelliCode also supports free-functions and has better accuracy. You can see the IntelliCode results starred at the top of the member list:

Talk to Us!
We’d love for you to download Visual Studio 2019 version 16.1 Preview 2 and enable IntelliCode for C++. We can be reached via the comments below or via email (visualcpp@microsoft.com). If you encounter other problems with Visual Studio or have other suggestions you can use the Report a Problem tool in Visual Studio or head over to the Visual Studio Developer Community. You can also find us on Twitter (@VisualC).
The post Improved C++ IntelliCode now Ships with Visual Studio 2019 appeared first on C++ Team Blog.
↧
Visual Studio 2019 version 16.1 Preview 2
The second preview of Visual Studio 2019 version 16.1 is now available. You can download it from VisualStudio.com, or, if you already have installed Preview, just click the notification bell inside Visual Studio to update. This latest preview contains additional performance and reliability fixes as well as enhancements for debugging, NuGet, extensibility, and C++ development. We’ve highlighted some notable features below. You can see a list of all the changes in the Preview release notes.
Improvements for C++ developers
CMake integration
In-editor helpers: We’ve added in-editor documentation for CMake commands, variables, and properties. You can now leverage IntelliSense autocompletion and quick info tooltips when editing a CMakeLists.txt file, which will save you time spent outside of the IDE referencing documentation and make the process less error-prone. See the C++ Team blog post on in-editor documentation for CMake in Visual Studio for more information.
In addition, Preview 2 adds lightbulbs for missing #includes that can be installed by vcpkg, and provides package autocompletion for the CMake find_package directive.


Clang/LLVM support: CMake integration now supports the Clang/LLVM toolchain for projects targeting Windows and/or Linux, so you can build, edit, and debug CMake projects that use Clang, MSVC, or GCC. The CMake version that ships with Visual Studio has been upgraded to 3.14 as well. This version adds built-in support for MSBuild generators targeting Visual Studio 2019 projects as well as file-based IDE integration APIs.
To learn more about these and other CMake improvements, see the C++ Team blog post Visual Studio 2019 version 16.1 Preview 2 CMake improvements.
C++ productivity improvements
C++ Template IntelliSense: The Template Bar dropdown menu is populated based on the instantiations of that template in your codebase. More details on this feature can be found in the post “C++ Template IntelliSense: Auto-populate instantiations in template bar” on the C++ Team blog.

Progress on C++20 conformance
Conformance improvements: New C++20 preview features have been added to the compiler and are available under /std:c++latest. Per P0846R0, the compiler has increased ability to find function templates via argument-dependent lookup for function call expressions with explicit template arguments. Also supported is designated initialization (P0329R4), which allows specific members to be selected in aggregate initialization, e.g. using the Type t { .member = expr } syntax.
We have also added new C++20 features to our implementation of the C++ Standard Library, including starts_with() and ends_with() for basic_string/basic_string_view, and contains() for associative containers. For more information, see the Preview 2 release notes.
Improved NuGet package debugging
Last year, we announced improved package debugging support with NuGet.org Symbol Server. Starting with Visual Studio version 16.1 Preview 2, debugging NuGet packages just became a whole lot simpler now that you can enable NuGet.org Symbol Server from the DebuggingSymbols option.

Source Link Improvements
Source Link now supports Windows authentication scenarios. Ultimately, using Windows authentication will allow you to use Source Link for on-premises Azure DevOps Servers (formerly, Team Foundation Server).
Visual Studio Search
Based on user feedback, Visual Studio Search will now display the three most recently used actions on focus. This makes it even easier to find previously searched-for items.

Solution view selector
The button for switching the Solution Explorer view will now consistently show you a dropdown menu of all possible views. Per your feedback, this solution removes the confusion of having the button default to toggling between Folder View and Solution View and not being clear on which solution it would open.

We have also improved the loading time for very large solutions, where the amount of improvement varies based on the size of the solution.
Extensibility
A number of updates to Visual Studio extensibility are included in this release, including Shared Project support and per-monitor awareness for dialogs. We’ve also eliminated the need for a .resx file and disabled synchronous auto-load. Additionally, the Visual Studio 2019 version of Microsoft.VisualStudio.SDK is now available as a NuGet package. Read all about these changes in the New features for extension authors in Visual Studio 2019 version 16.1 blog post.
Another notable extensibility update in this Preview is that project templates, project templates now support custom tags which allow them to show up in the New Project Dialog. See how to add tags in the blog post Build Visual Studio templates with tags, for efficient user search and grouping.
App Installer Templates
Over the last few releases, Visual Studio has improved the sideload packaging distribution experience for developers by introducing the App Installer file which specifies where an application is located and how it should be updated. Users who choose this method of application distribution simply share the App Installer file with their users rather than the actual app container.
The options available for use in the App Installer file are different based upon the Windows version the user is targeting. To enable maximum flexibility, Visual Studio 2019 version 16.1 allows users to define and configure the App Installer Update settings from a template Package.appinstaller.
Activate this template by right-clicking the project and selecting Add > New Item > App Installer Template.

The Package.appinstaller template file is available to edit and customize the update settings you want to use.

Note that once the template is added to the project, the user will no longer be able to customize update settings in the packaging wizard. All customizations must thus be edited in the template.
Use the latest features; give us feedback
To try out this preview of the latest features, either download Visual Studio 2019 version 16.1 Preview 2, update your existing preview channel installation by using the notification bell inside Visual Studio, or click Update from within the Visual Studio Installer.
We continue to value your feedback. As always, let us know of any issues you run into by using the Report a Problem tool in Visual Studio. You can also head over to the Visual Studio Developer Community to track your issues, suggest a feature, ask questions, and find answers from others. We use your feedback to continue to improve Visual Studio 2019, so thank you again on behalf of our entire team.
The post Visual Studio 2019 version 16.1 Preview 2 appeared first on The Visual Studio Blog.
↧