Coinciding with the Microsoft Ignite 2019 conference, we are thrilled to announce the GA release of ML.NET 1.4 and updates to Model Builder in Visual Studio, with exciting new machine learning features that will allow you to innovate your .NET applications.
ML.NET is an open-source and cross-platform machine learning framework for .NET developers. ML.NET also includes Model Builder (easy to use UI tool in Visual Studio) and CLI (Command-Line Interface) to make it super easy to build custom Machine Learning (ML) models using Automated Machine Learning (AutoML).
Using ML.NET, developers can leverage their existing tools and skillsets to develop and infuse custom ML into their applications by creating custom machine learning models for common scenarios like Sentiment Analysis, Price Prediction, Sales Forecast prediction, Customer segmentation, Image Classification and more!
Following are some of the key highlights in this update:
ML.NET Updates
In ML.NET 1.4 GA we have released many exciting improvements and new features that are described in the following sections.
Image classification based on deep neural network retraining with GPU support (GA release)
![ML.NET, TensorFlow, NVIDIA-CUDA]()
This feature enables native DNN (Deep Neural Network) transfer learning with ML.NET targeting image classification.
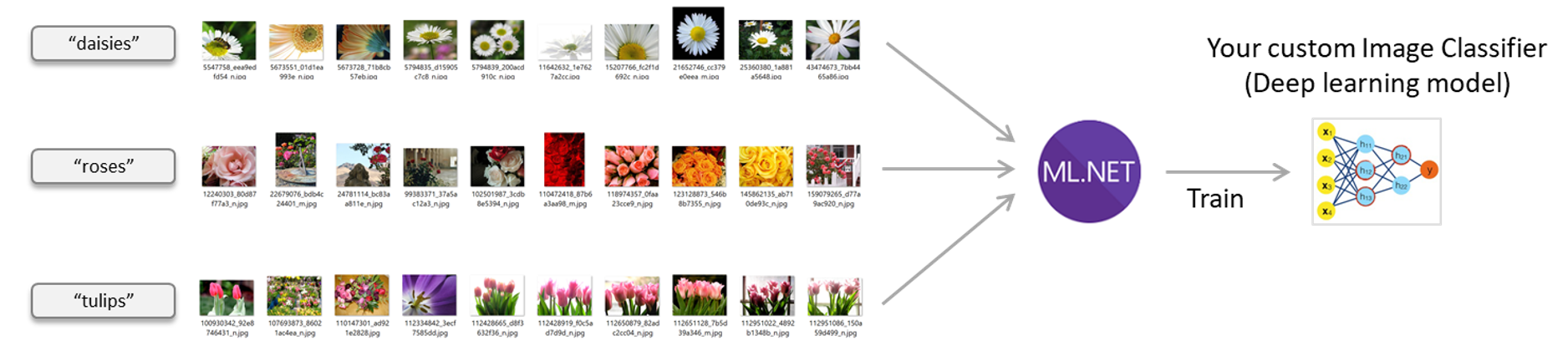
For instance, with this feature you can create your own custom image classifier model by natively training a TensorFlow model from ML.NET API with your own images.
Image classifier scenario – Train your own custom deep learning model with ML.NET
![Image Classification Training diagram]()
ML.NET uses TensorFlow through the low-level bindings provided by the Tensorflow.NET library. The advantage provided by ML.NET is that you use a high level API very simple to use so with just a couple of lines of C# code you define and train an image classification model. A comparable action when using the low level Tensorflow.NET library would need hundreds of lines of code.
The Tensorflow.NET library is an open source and low-level API library that provides the .NET Standard bindings for TensorFlow. That library is part of the open source SciSharp stack libraries.
The below stack diagram shows how ML.NET is implementing these new features on DNN training.
![DNN stack diagram]()
As the first main scenario for high level APIs, we are currently providing image classification, but the goal in the future for this new API is to allow easy to use DNN training for additional scenarios such as object detection and other DNN scenarios in addition to image classification, by providing a powerful yet simple API very easy to use.
This Image-Classification feature was initially released in v1.4-preview. Now, we’re releasing it as a GA release plus we’ve added the following new capabilities for this GA release:
Improvements in v1.4 GA for Image Classification
The main new capabilities in this feature added since v1.4-preview are:
-
GPU support on Windows and Linux. GPU support is based on NVIDIA CUDA. Check hardware/software requisites and GPU requisites installation procedure here. You can also train on CPU if you cannot meet the requirements for GPU.
- SciSharp TensorFlow redistributable supported for CPU or GPU: ML.NET is compatible with
SciSharp.TensorFlow.Redist (CPU training), SciSharp.TensorFlow.Redist-Windows-GPU (GPU training on Windows) and SciSharp.TensorFlow.Redist-Linux-GPU (GPU training on Linux).
-
Predictions on in-memory images: You make predictions with in-memory images instead of file-paths, so you have better flexibility in your app. See sample web app using in-memory images here.
-
Training early stopping: It stops the training when optimal accuracy is reached and is not improving any further with additional training cycles (epochs).
-
Added additional supported DNN architectures to the Image Classifier: The supported DNN architectures (pre-trained TensorFlow model) used internally as the base for ‘transfer learning’ has grown to the following list:
- Inception V3 (Was available in Preview)
- ResNet V2 101 (Was available in Preview)
- Resnet V2 50 (Added in GA)
- Mobilenet V2 (Added in GA)
Those pre-trained TensorFlow models (DNN architectures) are widely used image recognition models trained on very large image-sets such as the ImageNet dataset and are the culmination of many ideas developed by multiple researchers over the years. You can now take advantage of it now by using our easy to use API in .NET.
Example code using the new ImageClassification trainer
The below API code example shows how easily you can train a new TensorFlow model.
Image classifier high level API code example:
// Define model's pipeline with ImageClassification defaults (simplest way)
var pipeline = mlContext.MulticlassClassification.Trainers
.ImageClassification(featureColumnName: "Image",
labelColumnName: "LabelAsKey",
validationSet: testDataView)
.Append(mlContext.Transforms.Conversion.MapKeyToValue(outputColumnName: "PredictedLabel",
inputColumnName: "PredictedLabel"));
// Train the model
ITransformer trainedModel = pipeline.Fit(trainDataView);
The important line in the above code is the line using the ImageClassification classifier trainer which as you can see is a high level API where you just need to provide which column has the images, the column with the labels (column to predict) and a validation dataset to calculate quality metrics while training so the model can tune itself (change internal hyper-parameters) while training.
There’s another overloaded method for advanced users where you can also specify those optional hyper-parameters such as epochs, batchSize, learningRate and other typical DNN parameters, but most users can get started with the simplified API.
Under the covers this model training is based on a native TensorFlow DNN transfer learning from a default architecture (pre-trained model) such as Resnet V2 50. You can also select the one you want to derive from by configuring the optional hyper-parameters.
For further learning read the following resources:
Database Loader (GA Release)
![Database Loader diagram]()
This feature was previously introduced as preview and now is released as general availability in v1.4.
The database loader enables to load data from databases into the IDataView and therefore enables model training directly against relational databases. This loader supports any relational database provider supported by System.Data in .NET Core or .NET Framework, meaning that you can use any RDBMS such as SQL Server, Azure SQL Database, Oracle, SQLite, PostgreSQL, MySQL, Progress, etc.
In previous ML.NET releases, you could also train against a relational database by providing data through an IEnumerable collection by using the LoadFromEnumerable() API where the data could be coming from a relational database or any other source. However, when using that approach, you as a developer are responsible for the code reading from the relational database (such as using Entity Framework or any other approach) which needs to be implemented properly so you are streaming data while training the ML model, as in this previous sample using LoadFromEnumerable().
However, this new Database Loader provides a much simpler code implementation for you since the way it reads from the database and makes data available through the IDataView is provided out-of-the-box by the ML.NET framework so you just need to specify your database connection string, what’s the SQL statement for the dataset columns and what’s the data-class to use when loading the data. It is that simple!
Here’s example code on how easily you can now configure your code to load data directly from a relational database into an IDataView which will be used later on when training your model.
//Lines of code for loading data from a database into an IDataView for a later model training
//...
string connectionString = @"Data Source=YOUR_SERVER;Initial Catalog= YOUR_DATABASE;Integrated Security=True";
string commandText = "SELECT * from SentimentDataset";
DatabaseLoader loader = mlContext.Data.CreateDatabaseLoader();
DbProviderFactory providerFactory = DbProviderFactories.GetFactory("System.Data.SqlClient");
DatabaseSource dbSource = new DatabaseSource(providerFactory, connectionString, commandText);
IDataView trainingDataView = loader.Load(dbSource);
// ML.NET model training code using the training IDataView
//...
public class SentimentData
{
public string FeedbackText;
public string Label;
}
It is important to highlight that in the same way as when training from files, when training with a database ML.NET also supports data streaming, meaning that the whole database doesn’t need to fit into memory, it’ll be reading from the database as it needs so you can handle very large databases (i.e. 50GB, 100GB or larger).
Resources for the DatabaseLoader:
PredictionEnginePool for scalable deployments released as GA
![WebApp icon]()
![Azure Function icon]()
When deploying an ML model into multithreaded and scalable .NET Core web applications and services (such as ASP.NET Core web apps, WebAPIs or an Azure Function) it is recommended to use the PredictionEnginePool instead of directly creating the PredictionEngine object on every request due to performance and scalability reasons.
The PredictionEnginePool comes as part of the Microsoft.Extensions.ML NuGet package which is being released as GA as part of the ML.NET 1.4 release.
For further details on how to deploy a model with the PredictionEnginePool, read the following resources:
For further background information on why the PredictionEnginePool is recommended, read this blog post.
Enhanced for .NET Core 3.0 – Released as GA
![.NET Core 3.0 icon]()
ML.NET is now building for .NET Core 3.0 (optional). This feature was previosly released as preview but it is now released as GA.
This means ML.NET can take advantage of the new features when running in a .NET Core 3.0 application. The first new feature we are using is the new hardware intrinsics feature, which allows .NET code to accelerate math operations by using processor specific instructions.
Of course, you can still run ML.NET on older versions, but when running on .NET Framework, or .NET Core 2.2 and below, ML.NET uses C++ code that is hard-coded to x86-based SSE instructions. SSE instructions allow for four 32-bit floating-point numbers to be processed in a single instruction.
Modern x86-based processors also support AVX instructions, which allow for processing eight 32-bit floating-point numbers in one instruction. ML.NET’s C# hardware intrinsics code supports both AVX and SSE instructions and will use the best one available. This means when training on a modern processor, ML.NET will now train faster because it can do more concurrent floating-point operations than it could with the existing C++ code that only supported SSE instructions.
Another advantage the C# hardware intrinsics code brings is that when neither SSE nor AVX are supported by the processor, for example on an ARM chip, ML.NET will fall back to doing the math operations one number at a time. This means more processor architectures are now supported by the core ML.NET components. (Note: There are still some components that don’t work on ARM processors, for example FastTree, LightGBM, and OnnxTransformer. These components are written in C++ code that is not currently compiled for ARM processors).
For more information on how ML.NET uses the new hardware intrinsics APIs in .NET Core 3.0, please check out Brian Lui’s blog post Using .NET Hardware Intrinsics API to accelerate machine learning scenarios.
Use ML.NET in Jupyter notebooks
![Jupyter and MLNET logos]()
Coinciding with Microsoft Ignite 2019 Microsoft is also announcing the new .NET support on Jupyter notebooks, so you can now run any .NET code (C# / F#) in Jupyter notebooks and therefore run ML.NET code in it as well! – Under the covers, this is enabled by the new .NET kernel for Jupyter.
The Jupyter Notebook is an open-source web application that allows you to create and share documents that contain live code, visualizations and narrative text.
In terms of ML.NET this is awesome for many scenarios like exploring and documenting model training experiments, data distribution exploration, data cleaning, plotting data charts, learning scenarios such as ML.NET courses, hands-on-labs and quizzes, etc.
You can simply start exploring what kind of data is loaded in an IDataView:
![Exploring data in Jupyter]()
Then you can continue by plotting data distribution in the Jupyter notebook following an Exploratory Data Analysis (EDA) approach:
![Plotting in Jupyter]()
You can also train an ML.NET model and have its training time documented:
![Training in Jupyter]()
Right afterwards you can see the model’s quality metrics in the notebook, and have it documented for later review:
![Metrics in Jupyter]()
Additional examples are ‘plotting the results of predictions vs. actual data’ and ‘plotting a regression line along with the predictions vs. actual data’ for a better and visual analysis:
![Jupyter additional]()
For additional explanation details, check out this detailed blog post:
For a direct “try it out experience”, please go to this Jupyter notebook hosted at MyBinder and simply run the ML.NET code:
Updates for Model Builder in Visual Studio
The Model Builder tool for Visual Studio has been updated to use the latest ML.NET GA version (1.4 GA) plus it includes new exciting features such the visual experience in Visual Studio for local Image Classification model training.
Release date. Note that at the time of this blog post publication this version of Model Builder is still not released but will be released very soon in just a few days after Microsoft Ignite and the release of ML.NET 1.4 GA.
Model Builder updated to latest ML.NET GA version
Model Builder was updated to use latest GA version of ML.NET (1.4) and therefore the generated C# code also references ML.NET 1.4 NuGet packages.
Visual and local Image Classification model training in VS
As introduced at the begining of this blog post you can locally train an Image Classification model with the ML.NET API. However, when dealing with image files and image folders, the easiesnt way to do it is with a visual interface like the one provided by Model Builder in Visual Studio, as you can see in the image below:
![Model Builder in VS]()
When using Model Builder for training an Image Classifier model you simply need to visually select the folder (with a structure based on one sub-folder per image class) where you have the images to use for training and evaluation and simply start training the model. Then, when finished training you will get the C# code generated for inference/predictions and even for training if you want to use C# code for training from other environments like CI pipelines. Is that easy!
Try ML.NET and Model Builder today!
![ML.NET logo]()
We are excited to release these updates for you and we look forward to seeing what you will build with ML.NET. If you have any questions or feedback, you can ask here at this blog post or at the ML.NET repo at GitHub.
Happy coding!
The ML.NET team.
This blog was authored by Cesar de la Torre plus additional contributions of the ML.NET team.
The post Announcing ML.NET 1.4 general availability (Machine Learning for .NET) appeared first on .NET Blog.
























































.")



















