This week, Microsoft Ignite brought our team to sunny Orlando, Florida, along with thousands of professionals leveraging Microsoft technologies around the globe. To give you a taste of the event, this week’s post features some of the recordings of the community-driven Microsoft Ignite sessions dedicated to Azure DevOps.
How to run the Global DevOps Bootcamp community event (with 10.000 participants) on Azure
Community is tremendously important to all of us. Technical communities allow professionals from around the globe to share their experiences and collaborate, making the world a better place. But communities rarely simply emerge and sustain themselves, they require a lot of volunteer effort and support. In this 20-minute session, Marcel de Vries shares the experience of running a global community event with 10,000 participants, delivering training on Azure DevOps and Azure solutions. Marcel walks us through the architecture, logistics, setup, and learnings from the event. As an event-organizer myself, I am in awe of the success of a technical event at such a tremendous scale!
Azure DevOps for Power Platform ISVs
Software development comes in many shapes, but automation has been slower to arrive in some fields compared to others. Many of our Dynamics 365 customers and partners are building custom applications, but it used to be difficult to follow the CI/CD practices for app deployments in this space. In this 20-minute session, Mohamed Mostafa walks us through how to set up automated deployments for Dynamics 365 applications using the new Azure DevOps Power Apps build tools.
Azure Pipelines: Evolving from designer to YAML
There are many benefits to YAML pipelines, including the fact that your pipeline can be versioned and checked into source control along with your code, and the easier customization of your pipeline tasks. However, if you are used to building pipelines in the UI, the new experience may be confusing and even discouraging. In this 45-minuite session, Ernesto Cardenas Cangahuala teaches us how to leverage your existing experience with the UI pipeline designer in the new YAML pipeline world.
H&M’s quest of bringing world-class developer experience with Azure and DevOps
I absolutely love to hear the real-world stories of success from customers using our tools. Knowing that we help improve people’s experience with delivering software is what brings us to work every day! In this 20-minute session, Jakob Knutsson and Mikael Sjödin from H&M share their experience of the enterprise-wide adoption of Azure DevOps in the span of just three months. The session covers the learnings, the challenges, and the outcomes of the onboarding. Thank you Jakob and Mikael!
Exam Prep | AZ-400: Microsoft Azure DevOps Solutions
This 75-minute session by Dwight Goins covers the exam preparation for the certification exam Az-400: Microsoft Azure DevOps Solutions. The session is an overview of the topics covered in the exam, including managing development teams, managing source code, automating builds, tests, packaging, versioning, and deployments. If you are looking to take the exam, this session will give you a very useful start.
If you’ve written an article about Azure DevOps or find some great content about DevOps on Azure, please share it with the #AzureDevOps hashtag on Twitter!
Today, more and more organizations are focused on delivering new digital solutions to customers and finding that the need for increased agility, improved processes, and collaboration between development and operation teams is becoming business-critical. For over a decade, DevOps has been the answer to these challenges. Understanding the need for DevOps is one thing, but the actual adoption of DevOps in the real world is a whole other challenge. How can an organization with multiple teams and projects, with deeply rooted existing processes, and with considerable legacy software change its ways and embrace DevOps?
At Microsoft, we know something about these challenges. As a company that has been building software for decades, Microsoft consists of thousands of engineers around the world that deliver many different products. From Office, to Azure, to Xbox we also found we needed to adapt to a new way of delivering software. The new era of the cloud unlocks tremendous potential for innovation to meet our customers’ growing demand for richer and better experiences—while our competition is not slowing down. The need to accelerate innovation and to transform how we work is real and urgent.
The road to transformation is not easy and we believe that the best way to navigate this challenging path is by following the footsteps of those who have already walked it. This is why we are excited to share our own DevOps journey at Microsoft with learnings from teams across the company who have transformed through the adoption of DevOps.
More than just tools
An organization’s success is achieved by providing engineers with the best tools and latest practices. At Microsoft, the One Engineering System (1ES) team drives various efforts to help teams across the company become high performing. The team initially focused on tool standardization and saw some good results—source control issues decreased, build times and build reliability improved. But over time it became clear that the focus on tooling is not enough, to help teams, 1ES had to focus on culture change as well. Approaching culture change can be tricky, do you start with quick wins, or try to make a fundamental change at scale? What is the right engagement model for teams of different sizes and maturity levels? Learn more about the experimental journey of the One Engineering System team.
Redefining IT roles and responsibilities
The move to the cloud can challenge the definitions of responsibilities in an organization. As development teams embrace cloud innovation, IT operations teams find that the traditional models of ownership over infrastructure no longer apply. The Manageability Platforms team in the Microsoft Core Service group (previously Microsoft IT), found that the move to Azure required rethinking the way IT and development teams work together. How can the centralized IT model be decentralized so the team can move away from mundane, day-to-day work while improving the relationship with development teams? Explore the transformation of the Manageability Platforms team.
Streamlining developer collaboration
Developer collaboration is a key component of innovation. With that in mind, Microsoft open-sourced the .NET framework to invite the community to collaborate and innovate on .NET. As the project was open-sourced over time, its scale and complexity became apparent. The project spanned over many repositories, each with its own structure using multiple different continuous integration (CI) systems, making it hard for developers to move between repositories. The .NET infrastructure team at Microsoft decided to invest in streamlining developer processes. That challenge was approached by focusing on standardizing repo structure, shared tooling, and converging on a single CI system so both internal and external contributors to the project would benefit. Learn more about the investments made by the .NET infrastructure team.
A journey of continuous learning
DevOps at Microsoft is a journey, not a destination. Teams adapt, try new things, and continue to learn how to change and improve. As there is always more to learn, we will continue to share the transformation stories of additional teams at Microsoft in the coming months. As an extension of this continuous internal learning journey, we invite you to join us on the journey and learn how to embrace DevOps and empower your teams to build better solutions, faster and deliver them to happier customers.
Azure Artifacts, part of Azure DevOps, is a package and binary management service supporting .NET (NuGet), Java (Maven), Python (PyPi) and JavaScript (npm) packages. We undertook a lot of impactful work in the past couple of months, spanning from completely new features to performance improvements to our main UX. We are excited to announce the general availability of two key features: Public Feeds, and the Feed Recycle Bin.
Share your packages publicly with Public Feeds
You can now create and store your packages inside public feeds. Packages stored within public feeds are publicly available to anyone on the Internet, without requiring authentication with any Azure DevOps account. Learn more about public feeds in our feeds documentation, or jump right into our tutorial for sharing packages publicly.
Project-Scoped Feeds
We released Project-Scoped Feeds together with Public Feeds; you can read more about feed scoping in the documentation. Until now, all feeds were scoped to an organization and were visible from any project, and we heard feedback that this was sometimes counter-intuitive given how users like to organize their accounts. You can see which feeds are project-scoped and which are organization-scoped in the feed picker.
Feed Recycle Bin
We recently introduced the Feed Recycle Bin, which stores deleted feeds for up to 30 days, allowing users to restore or permanently delete them. The concept of a package recycle bin already exists and the feed recycle bin will help prevent issues or downtime due to an accidental deletion of an entire feed.
Performance improvements
We made some performance improvements to our backend that resulted in significantly shorter load times for feeds, especially large ones. We saw a 300% improvement in load time for our biggest (99th percentile) feeds from 4 seconds to 1 second, with an average decrease of around 50ms for all feeds.
Get started with Azure Artifacts
If you haven’t already, you can sign up for Azure Artifacts as part of Azure DevOps Services.
We look forward to hearing what you think and continue to work on making package and binary management as effortless as can be. If you have feedback, please let us know on Developer Community or via Twitter @AzureDevOps.
For an industry that started 12,000 years ago, there is a lot of unpredictability and imprecision in agriculture. To be predictable and precise, we need to align our actions with insights gathered from data. Last week at Microsoft Ignite, we launched the preview of Azure FarmBeats, a purpose-built, industry-specific solution accelerator built on top of Azure to enable actionable insights from data.
With AgriTechnica 2019 starting today, more than 450,000 attendees from 130 countries are gathering to experience innovations in the global agriculture industry. We wanted to take this opportunity to share more details about Azure FarmBeats.
Azure FarmBeats is a business-to-business offering available in Azure Marketplace. It enables aggregation of agriculture datasets across providers and generation of actionable insights by building artificial intelligence (AI) or machine learning (ML) models based on fused datasets. So, agribusinesses can focus on their core value-add rather than the undifferentiated heavy lifting of data engineering.
Figure 1: Overview of Azure FarmBeats
With the preview of Azure FarmBeats you can:
Assess farm health using vegetation index and water index based on satellite imagery.
Get recommendations on how many sensors to use and where to place them.
Track farm conditions by visualizing ground data collected by sensors from various vendors.
Scout farms using drone imagery from various vendors.
Get soil moisture maps based on the fusion of satellite and sensor data.
Gain actionable insights by building AI or ML models on top of fused datasets.
Build or augment your digital agriculture solution by providing farm health advisories.
As an example, here is how a farm populated with data appears in Azure FarmBeats:
Figure 2: Boundary, sensor locations, and sensor readings for a farm
For a real-world example of how it works, take a look at our partnership with the United States Department of Agriculture (USDA). In a pilot, USDA is using Azure FarmBeats to collect data from multiple sources, such as sensors, drones, and satellites, and feeding it into cloud-based AI models to get a detailed picture of conditions on the farm.
Azure FarmBeats includes the following components:
Datahub: An API layer thatenables aggregation, normalization, and contextualization of various agriculture datasets across providers. You can leverage the following data providers:
Datahub is designed as an API platform and we are working with many more providers – sensor, satellite, drone, weather, farm equipment – to integrate with FarmBeats, so you have more choice while building your solution.
Accelerator: A sample solution, built on top of Datahub, that jumpstarts your user interface (UI) and model development. This web application leverages APIs to demonstrate visualization of ingested sensor data as charts and visualization of model output as maps. For example, you can use this to quickly create a farm and easily get a vegetation index map or a sensor placement map for that farm.
While this preview is the culmination of years of research work and working closely with more than a dozen agriculture majors, it is just the beginning. It would not have been possible without the early feedback and validation from these organizations, and we take this opportunity to extend our sincere gratitude.
Azure FarmBeats is offered at no additional charge and you pay only for the Azure resources you use. You can get started by installing it from Azure Marketplace in Azure Portal. In addition, you can:
Seek help by posting a question on our support forum.
Provide feedback by posting or voting for an idea on our feedback forum.
With Azure FarmBeats preview, we are pioneering a cloud platform to empower every person and every organization in agriculture to achieve more, by harnessing the power of IoT, cloud, and AI. We are delighted to have you with us on this global transformational journey and look forward to your feedback on the preview.
If data-access challenges have been keeping you from running high-performance computing (HPC) jobs in Azure, we’ve got great news to report! The now-available Microsoft Azure HPC Cache service lets you run your most demanding workloads in Azure without the time and cost of rewriting applications and while storing data where you want to—in Azure or on your on-premises storage. By minimizing latency between compute and storage, the HPC Cache service seamlessly delivers the high-speed data access required to run your HPC applications in Azure.
Use Azure to expand analytic capacity—without worrying about data access
Most HPC teams recognize the potential for cloud bursting to expand analytic capacity. While many organizations would benefit from the capacity and scale advantages of running compute jobs in the cloud, users have been held back by the size of their datasets and the complexity of providing access to those datasets, typically stored on long-deployed network-attached storage (NAS) assets. These NAS environments often hold petabytes of data collected over a long period of time and represent significant infrastructure investment.
Here’s where the HPC Cache service can help. Think of the service as an edge cache that provides low-latency access to POSIX file data sourced from one or more locations, including on-premises NAS and data archived to Azure Blob storage. The HPC Cache makes it easy to use Azure to increase analytic throughput, even as the size and scope of your actionable data expands.
Keep up with the expanding size and scope of actionable data
The rate of new data acquisition in certain industries such as life sciences continues to drive up the size and scope of actionable data. Actionable data, in this case, could be datasets that require post-collection analysis and interpretation that in turn drive upstream activity. A sequenced genome can approach hundreds of gigabytes, for example. As the rate of sequencing activity increases and becomes more parallel, the amount of data to store and interpret also increases—and your infrastructure has to keep up. Your power to collect, process, and interpret actionable data—your analytic capacity—directly impacts your organization’s ability to meet the needs of customers and to take advantage of new business opportunities.
Some organizations address expanding analytic throughput requirements by continuing to deploy more robust on-premises HPC environment with high-speed networking and performant storage. But for many companies, expanding on-premises environments presents increasingly daunting and costly challenges. For example, how can you accurately forecast and more economically address new capacity requirements? How do you best juggle equipment lifecycles with bursts in demand? How can you ensure that storage keeps up (in terms of latency and throughput) with compute demands? And how can you manage all of it with limited budget and staffing resources?
Azure services can help you more easily and cost-effectively expand your analytic throughput beyond the capacity of existing HPC infrastructure. You can use tools like Azure CycleCloud and Azure Batch to orchestrate and schedule compute jobs on Azure virtual machines (VMs). More effectively manage cost and scale by using low-priority VMs, as well as Azure Virtual Machine Scale Sets. Use Azure’s latest H- and N-series Virtual Machines to meet performance requirements for your most complex workloads.
So how do you start? It’s straightforward. Connect your network to Azure via ExpressRoute, determine which VMs you will use, and coordinate processes using CycleCloud or Batch—voila, your burstable HPC environment is ready to go. All you need to do is feed it data. Ok, that’s the stickler. This is where you need the HPC Cache service.
Use HPC Cache to ensure fast, consistent data access
Most organizations recognize the benefits of using cloud: a burstable HPC environment can give you more analytic capacity without forcing new capital investments. And Azure offers additional pluses, letting you take advantage of your current schedulers and other toolsets to ensure deployment consistency with your on-premises environment.
But here’s the catch when it comes to data. Your libraries, applications, and location of data may require the same consistency. In some circumstances, a local analytic pipeline may rely on POSIX paths that must be the same whether running in Azure or locally. Data may be linked between directories, and those links may need to be deployed in the same way in the cloud. The data itself may reside in multiple locations and must be aggregated. Above all else, the latency of access must be consistent with what can be realized in the local HPC environment.
To understand how the HPC Cache works to address these requirements, consider it an edge cache that provides low-latency access to POSIX file data sourced from one or more locations. For example, a local environment may contain a large HPC cluster connected to a commercial NAS solution. HPC Cache enables access from that NAS solution to Azure Virtual Machines, containers, or machine learning routines operating across a WAN link. The service accomplishes this by caching client requests (including from the virtual machines), and ensuring that subsequent accesses of that data are serviced by the cache rather than by re-accessing the on-premises NAS environment. This lets you run your HPC jobs at a similar performance level as you could in your own data center. HPC Cache also lets you build a namespace consisting of data located in multiple exports across multiple sources while displaying a single directory structure to client machines.
HPC Cache provides a Blob-backed cache (we call it Blob-as-POSIX) in Azure as well, facilitating migration of file-based pipelines without requiring that you rewrite applications. For example, a genetic research team can load reference genome data into the Blob environment to further optimize the performance of secondary-analysis workflows. This helps mitigate any latency concerns when you launch new jobs that rely on a static set of reference libraries or tools.
Azure HPC Cache Architecture
HPC Cache Benefits
Caching throughput to match workload requirements
HPC Cache offers three SKUs: up to 2 gigabytes per second (GB/s), up to 4 GB/s, and up to 8 GB/s throughput. Each of these SKUs can service requests from tens to thousands of VMs, containers, and more. Furthermore, you choose the size of your cache disks to control your costs while ensuring the right capacity is available for caching.
Data bursting from your datacenter
HPC Cache fetches data from your NAS, wherever it is. Run your HPC workload today and figure out your data storage policies over the longer term.
High-availability connectivity
HPC Cache provides high-availability (HA) connectivity to clients, a key requirement for running compute jobs at larger scales.
Aggregated namespace
The HPC Cache aggregated namespace functionality lets you build a namespace out of various sources of data. This abstraction of sources makes it possible to run multiple HPC Cache environments with a consistent view of data.
Lower-cost storage, full POSIX compliance with Blob-as-POSIX
HPC Cache supports Blob-based, fully POSIX-compliant storage. HPC Cache, using the Blob-as-POSIX format, maintains full POSIX support including hard links. If you need this level of compliance, you’ll be able to get full POSIX at Blob price points.
Start here
The Azure HPC Cache Service is available today and can be accessed now. For the very best results, contact your Microsoft team or related partners—they’ll help you build a comprehensive architecture that optimally meets your specific business objectives and desired outcomes.
Our experts will be attending at SC19 in Denver, Colorado, the conference on high-performance computing, ready and eager to help you accelerate your file-based workloads in Azure!
This is a guest post from the Pulumi team. Pulumi is an open source infrastructure as code tool that helps developers and infrastructure teams work better together to create, deploy, and manage cloud applications using their favorite languages. For more information, see https://pulumi.com/dotnet.
We are excited to announce .NET Core support for Pulumi! This announcement means you can declare cloud infrastructure — including all of Azure, such as Kubernetes, Functions, AppService, Virtual Machines, CosmosDB, and more — using your favorite .NET language, including C#, VB.NET, and F#. This brings the entire cloud to your fingertips without ever having to leave your code editor, while using production-ready “infrastructure as code” techniques.
Infrastructure has become more relevant these days as modern cloud capabilities such as microservices, containers, serverless, and data stores permeate your application’s architecture. The term “infrastructure” covers all of the cloud resources your application needs to run. Modern architectures require thinking deeply about infrastructure while building your application, instead of waiting until afterwards. Pulumi’s approach helps developers and infrastructure teams work together to deliver innovative new functionality that leverages everything the modern cloud has to offer.
Pulumi launched a little over a year ago and recently reached a stable 1.0 milestone. After working with hundreds of companies to get cloud applications into production, .NET has quickly risen to one of Pulumi’s most frequently community requested features. Especially since many of us on the Pulumi team are early .NET ex-pats, we are thrilled today to make Pulumi available on .NET Core for your cloud engineering needs.
What is Pulumi?
Pulumi lets you use real languages to express your application’s infrastructure needs, using a powerful technique called “infrastructure as code.” Using infrastructure as code, you declare desired infrastructure, and an engine provisions it for you, so that it’s automated, easy to replicate, and robust enough for demanding production requirements. Pulumi takes this approach a step further by leveraging real languages and making modern cloud infrastructure patterns, such as containers and serverless programs, first class and easy.
With Pulumi for .NET you can:
Declare infrastructure using C#, VB.NET, or F#.
Automatically create, update, or delete cloud resources using Pulumi’s infrastructure as code engine, removing manual point-and-clicking in the Azure UI and ad-hoc scripts.
Use your favorite IDEs and tools, including Visual Studio and Visual Studio Code, taking advantage of features like auto-completion, refactoring, and interactive documentation.
Catch mistakes early on with standard compiler errors, Roslyn analyzers, and an infrastructure-specific policy engine for enforcing security, compliance, and best practices.
Reuse any existing NuGet library, or distribute your own, whether that’s for infrastructure best practices, productivity, or just general programming patterns.
Deploy continuously, predictably, and reliably using Azure DevOps Pipelines, GitHub Actions, or one of over a dozen integrations.
Build scalable cloud applications using classic infrastructure cloud native technologies like Kubernetes, Docker containers, serverless functions, and highly scalable databases such as CosmosDB into your core development experience, bringing them closer to your application code.
Pulumi’s free open source SDK, which includes a CLI and assortment of libraries, enables these capabilities. Pulumi also offers premium features for teams wanting to use Pulumi in production, such as Azure ActiveDirectory integration for identity and advanced policies.
An example: global database with serverless app
Let’s say we want to build a new application that uses Azure CosmosDB for global distribution of data so that performance is great for customers no matter where in the world they are, with a C# serverless application that automatically scales alongside our database. Normally we’d use some other tools to create the infrastructure, such as JSON, YAML, a DSL, or manually point-and-click in the Azure console. This approach is par for the course, but also daunting — it’s complex, unrepeatable, and means we need an infrastructure expert just to even get started.!
The Pulumi approach is to just write code in our favorite .NET language and the Pulumi tool will handle the rest. For example, this C# code creates an Azure CosmosDB databases with a serverless Azure AppService FunctionApp that automatically scales alongside the database:
After writing this code, you run the Pulumi CLI with the pulumi up command and it will first show you a preview of the infrastructure resources it plans on creating. After confirming, it will deploy your whole application and its required infrastructure in just a few minutes.
Later on, if you need to make any changes, you just edit your program, rerun the CLI, and it will make the necessary incremental changes to update your infrastructure accordingly. A full history of your deployments is recorded so you can easily see what changes have been made.
Why is .NET great for infrastructure too?
Many of us love using .NET to author our applications, so why not use it for infrastructure as code too? We’ve in fact already seen above some of the advantages above to doing so. Many of these are probably evident if you already know and love .NET, however, let’s briefly recap.
By using any .NET language, you get many helpful features for your infrastructure code:
Familiarity: No need to learn DSLs or markup templating languages.
Expressiveness: Use loops, conditionals, pattern matching, LINQ, async code, and more, to dynamically create infrastructure that meets the target environment’s needs.
Abstraction: Encapsulate common patterns into classes and functions to hide complexity and avoid copy-and-pasting the same boilerplate repeatedly.
Sharing and reuse: Tap into a community of cloud applications and infrastructure experts, by sharing and reusing NuGet libraries with your team or the global community.
Productivity: Use your favorite IDE and get statement completion, go to definition, live error checking, refactoring, static analysis, and interactive documentation.
Project organization: Use common code structuring techniques such as assemblies and namespaces to manage your infrastructure across one or more projects.
Application lifecycle: Use existing ALM systems and techniques to manage and deploy your infrastructure projects, including source control, code review, testing, and continuous integration (CI) and delivery (CD).
Pulumi unlocks access to the entire .NET ecosystem — something that’s easy to take for granted but is missing from other solutions based on JSON, YAML, DSLs, or CLI scripts. Having access to a full language was essential to enabling the CosmosApp example above, which is a custom component that internally uses classes, loops, lambdas, and even LINQ. This approach also helps developers and operators work better together using a shared foundation. Add all of the above together, and you get things done faster and more reliably.
Join the community and get started
Today we’ve released the first preview of Pulumi for .NET, including support for the entire Azure breath of services. To give Pulumi a try, visit the Pulumi for .NET homepage.
There you will find several instructions on installing and getting started with Pulumi for .NET. The following resources provide additional useful information:
Although Pulumi for .NET is listed in “preview” status, it supports all of the most essential Pulumi programming model features (and the rest is on its way). Our goal is to gather feedback and over the next few weeks, and we will be working hard to improve the .NET experience across the board, including more examples and better documentation.
This is an exciting day for the Pulumi team and our community. Pulumi was started by some of .NET’s earliest people and so it’s great to get back to our roots and connect with the .NET community, helping developers, infrastructure teams, and operators build better cloud software together.
We look forward to seeing the new and amazing cloud applications you build with Pulumi for .NET!
Today, we are announcing an update to .NET Framework Repair tool.
In case you are not familiar with previous releases of this tool, here is a bit of background. Occasionally, some customers will run into issues when deploying a .NET Framework release or its updates and the issue may not be fixed from within the setup itself.
In such cases, the .NET Framework Repair Tool can help with detecting and fixing some of the common causes of install failures. This version (v1.4) of the repair tool supports all versions of .NET Framework from 3.5 SP1 to 4.8. The latest update adds support for .NET Framework 4.6.2, 4.7, 4.7.1, 4.7.2 and 4.8.
If you had previously downloaded an older version of the tool, we recommend you get the latest version from the following location:
The tool supports both command line mode for power users as well as a setup wizard interface familiar to most users. You can find more information about how to use the repair tool and its capabilities by visiting the knowledge base article 2698555.
In a previous blog series, we announced that Git has a new commit-graph feature, and described some future directions. Since then, the commit-graph feature has grown and evolved. In the recently released Git version 2.24.0, the commit-graph is enabled by default! Today, we discuss what you should know about the feature, and what you can expect when you upgrade.
What is the commit-graph, and what is it good for?
The commit-graph file is a binary file format that creates a structured representation of Git’s commit history. At minimum, the commit-graph file format is faster to parse than decompressing commit files and parsing them to find their parents and root trees. This faster parsing can lead to 10x performance improvements.
To get even more performance benefits, Git does not just use the commit-graph file to parse commits faster, but the commit-graph includes extra information to help avoid parsing some commits altogether. The critical idea is that an extra value, the generation number of a commit, can significantly reduce the number of commits we need to walk. Since Git 2.19.0, the commit-graph stores generation numbers.
Finally, the most immediately-visible improvement is the time it takes to sort commits by topological order. This algorithm is the critical path for git log --graph. Before the commit-graph, Git needed to walk every reachable commit before returning a single result.
Example output for git log --graph
For example, here is a run of git log --graph in the Linux repository without the commit-graph feature, timing how long it takes to return ten results:
$ time git -c core.commitGraph=false log --graph --oneline -10 >/dev/null
real 0m6.103s
user 0m5.803s
sys 0m0.300s
The reason it took so long is because Kahn’s algorithm computes the “in-degrees” of every reachable commit before it can start to select commits of in-degree zero for output. When the commit-graph is present with generation numbers, Git now uses an iterative version of Kahn’s algorithm to avoid walking too far before knowing that some of the commits have in-degree zero and can be sent to output.
Here is that same command again, this time with the commit-graph feature enabled:
$ time git -c core.commitGraph=true log --graph --oneline -10 >/dev/null
real 0m0.009s
user 0m0.000s
sys 0m0.008s
Six seconds to nine milliseconds is a 650x speedup! Since most users asking for git log --graph actually see the result in a paged terminal window, this allows Git to load the first page of results almost instantaneously, and the next pages are available as you scroll through the history.
Sounds Great! What do I need to do?
If you are using Git 2.23.0 or later, then you have all of these benefits available to you! You just need to enable the following config settings:
git config --global core.commitGraph true: this enables every Git repo to use the commit-graph file, if present.
git config --global gc.writeCommitGraph true: this setting tells the git gc command to write the commit-graph file whenever you do non-trivial garbage collection. Rewriting the commit-graph file is a relatively small operation compared to a full GC operation.
git commit-graph write --reachable: this command will update your commit-graph file to contain all reachable commits. You can run this to create the commit-graph file immediately, instead of waiting for your first GC operation.
In the recently-released Git version 2.24.0, core.commitGraph and gc.writeCommitGraph are on by default, so you don’t need to set the config manually. If you don’t want commit-graph files, then explicitly disable these settings and tell us why this isn’t working for you. We’d love to hear your feedback!
Write during fetch
The point of the gc.writeCommitGraph is to keep your commit-graph updated with some frequency. As you add commits to your repo, the commit-graph gets further and further behind. That means your commit walks will parse more commits the old-fashioned way until finally reaching the commits in the commit-graph file.
When working in a Git repo with many collaborators, the primary source of commits is not your own git commit calls, but your git fetch and git pull calls. However, if your repo is large enough, writing the commit-graph after each fetch may make your git fetch command unacceptably slow. Perhaps you downloaded a thousand new commits, but your repo has a million total commits. Writing the full commit-graph operates on the size of your repo, not on the size of your fetch, so writing those million commits is costly relative to the runtime of the fetch.
During garbage collection, you are already paying for a full repack of all of your Git objects. That operation is already on the scale of your entire repository, so adding a full commit-graph write on top of that is not a problem.
There is a solution: don’t write the whole commit-graph every time! We’ll go into how this works in more detail in the next section, but first you can enable the fetch.writeCommitGraph config setting to write the commit-graph after every git fetch command:
git config --global fetch.writeCommitGraph true
This ensures that your commit-graph is updated on every fetch and your Git commands are always as fast as possible.
Incremental Commit-Graph Format
Before getting too far into the incremental file format, we need to refresh some details about the commit-graph file itself.
One table is a sorted list of commit IDs. This row number of a commit ID in this table defines the lexicographical position (lex position for short) of a commit in the file.
Another table contains metadata about the commits. The nth row of the metadata table corresponds to the commit with lex position n. This table contains the root tree ID, commit time, generation number, and information on the first two parents of the commit. We use special constants to say “this commit does not have a second parent”, and use a pointer to a third “extra edges” table in the case of octopus merges.
The two parent columns are stored as integers, and this is very important! If we store parents as commit IDs, then we waste a lot of space. Further, if we only have a commit ID, then we need to perform a binary search on the commit list to find the lex position. By storing the position of a parent, we can navigate to the metadata row for that parent as a random-access lookup.
For that reason, the commit-graph file is closed under reachability, meaning that if a commit is in the file, then so is its parent. Otherwise, we could not refer to the parent using an integer.
Before incremental writes, Git stored the commit-graph file as .git/objects/info/commit-graph. Git looks for that file, and parses it if it exists.
Multiple Commit-Graph Files
Instead of having just one commit-graph file, now Git can have multiple! The important idea is that these files are ordered carefully such that they form a chain. The figure below shows three sections of a graph. The bottom layer is completely self-contained: if a commit is in the bottom layer, then so is its parents and every other commit it can reach. The middle layer allows parents to span between that layer and the bottom layer. The top layer is the same.
Three layers of a commit graph, shown as a directed graph
The important feature is that the top layer is smaller than the other layers. If those commits are new to the repo, then writing that top layer is much faster than rewriting the entire graph.
Keep this model in mind as we dig into the concrete details of how Git creates this chain of commit-graph files.
If the single .git/objects/info/commit-graph file does not exist, Git looks for a file called .git/objects/info/commit-graphs/commit-graph-chain. This file contains a list of SHA-1 hashes separated by newlines. To demonstrate, we will use this list of placeholders:
{hash0}
{hash1}
{hash2}
These hashes correspond to files named .git/objects/info/commit-graphs/graph-{hash0}.graph. The chain of the three files combine to describe a set of commits.
The first graph file, graph-{hash0}.graph, is a normal commit-graph file. It does not refer to any other commit-graph and is closed under reachability.
The second graph file, graph-{hash1}.graph is no longer a normal commit-graph file. To start, it contains a pointer to graph-{hash0}.graph by storing an extra “base graphs” table containing only “{hash0}”. Second, the parents of the commits in graph-{hash1}.graph may exist in that file or in graph-{hash0}.graph. Each graph file stores the commits in lexicographic order, but we now need a second term for the position of a commit in the combined order.
We say the graph position of a commit in the commit-graph chain is the lex position of a commit in the sorted list plus the number of commits in the base commmit-graph files. We now modify our definition of a parent position to use the graph position. This allows the graph-{hash1}.graph file to not be closed under reachability: the parents can exist in either file.
Extending to graph-{hash2}.graph, the parents of those commits can be in any of the three commit-graph files. The figure below shows this stack of files and how one commit row in graph-{hash2}.graph can have parents in graph-{hash1}.graph and graph-{hash0}.graph.
The file layout for a commit-graph chain
If you enable fetch.writeCommitGraph, then Git will write a commit-graph chain after every git fetch command. This is much faster than rewriting the entire file, since the top layer of the chain can consist of only the new commits. At least, it will usually be faster.
Do it Yourself!
To create your own commit-graph chain, you can start with an existing commit-graph file then create new commits and create an incremental file:
‐‐split option enables creating a chain of commit-graph files. If you ever run the command without the ‐‐split option, then the chain will merge into a single file.
The figure above hints at the sizes of the commit-graph files in a chain. The base file is large and contains most of the commits. As we look higher in the chain, the sizes should shrink.
There is a problem, though. What happens when we fetch 100 times? Will we get a chain of 100 commit-graph files? Will our commit lookups suddenly get much slower? The way to avoid this is to occasionally merge layers of the chain. This results in better amortized time, but will sometimes result in a full rewrite of the entire commit-graph file.
Merging Commit-Graph Files
To ensure that the commit-graph chain does not get too long, Git will occasionally merge layers of the chain. This merge operation is always due to some number of incoming commits causing the “top” of the chain to be too large. There are two reasons Git would merge layers, given by these options to git commit-graph write --split:
--size-multiple=<X>: Ensure that a commit-graph file is X times larger than any commit-graph file “above” it. X defaults to 2.
--max-commits=<M>: When specified, make sure that only the base layer has more than M commits.
The size-multiple option ensures that the commit-graph chain never has more than log(N) layers, where N is total number of commits in the repo. If those chains seem to be too long, the max-commits setting (in conjunction with size-multiple) guarantees that there are a constant number of possible layers.
In all, you should not see the incremental commit-graph taking very long during a fetch. You are more likely to see the automatic garbage collection trigger, and that will cause your commit-graph chain to collapse to a single layer.
Try it Yourself!
We would love your feedback on the feature! Please test out the --split option for writing commit-graphs in Git 2.23.0 or later, and the fetch.writeCommitGraph option in Git 2.24.0. Git 2.24.0 is out now, so go upgrade and test!
We’ve just released our newest Azure Blueprints for the important US Federal Risk and Authorization Management Program (FedRAMP) certification at the moderate level. FedRAMP is a key certification because cloud providers seeking to sell services to US federal government agencies must first demonstrate FedRAMP compliance. Azure and Azure Government are both approved for FedRAMP at the high impact level, and we’re planning that a future Azure Blueprints will provide control mappings for high impact.
Azure Blueprints is a free service that helps enable customers to define a repeatable set of Azure resources that implement and adhere to standards, patterns, and requirements. Azure Blueprints allow customers to set up compliant environments matched to common internal scenarios and external standards like ISO 27001, Payment Card Industry data security standard (PCI DSS), and Center for Internet Security (CIS) Benchmarks.
Compliance with standards such as FedRAMP is increasingly important for all types of organizations, making control mappings to compliance standards a natural application for Azure Blueprints. Azure customers, particularly those in regulated industries, have expressed a strong interest in compliance blueprints to help ease the burden of their compliance obligations.
FedRAMP was established to provide a standardized approach for assessing, monitoring, and authorizing cloud computing services under the Federal Information Security Management Act (FISMA), and to help accelerate the adoption of secure cloud solutions by federal agencies.
The Office of Management and Budget now requires all executive federal agencies to use FedRAMP to validate the security of cloud services. The National Institute of Standards and Technology (NIST) 800-53 sets the standard, and FedRAMP is the program that certifies that a Cloud Solution Provider (CSP) meets that standard. Azure is also compliant with NIST 800-53, and we already offer an Azure Blueprints for NIST SP 800-53 Rev4.
The new blueprint provides partial control mappings to important portions of FedRAMP Security Controls Baseline at the moderate level, including:
Access control (AC)
AC-2 account management (AC-2). Assigns Azure Policy definitions that audit external accounts with read, write, and owner permissions on a subscription and deprecated accounts, implement role-based access control (RBAC) to help you manage who has access to resources in Azure, and monitor virtual machines that can support just-in-time access but haven't yet been configured.
Information flow enforcement (AC-4).Assigns an Azure Policy definition to help you monitor Cross-Origin Resource Sharing (CORS) resources access restrictions.
Separation of duties (AC-5). Assigns Azure Policy definitions that help you control membership of the administrators group on Windows virtual machines.
Remote access (AC-17). Assigns an Azure Policy definition that helps you with monitoring and control of remote access.
Audit and accountability (AU)
Response to audit processing failures (AU-5). Assigns Azure Policy definitions that monitor audit and event logging configurations.
Audit generation(AU-12). Assigns Azure Policy definitions that audit log settings on Azure resources.
Configuration management (CM)
Least functionality (CM-7). Assigns an Azure Policy definition that helps you monitor virtual machines where an application whitelist is recommended but has not yet been configured.
User-installed software (CM-11). Assigns an Azure Policy definition that helps you monitor virtual machines where an application whitelist is recommended but has not yet been configured.
Contingency planning (CP)
Alternate processing site (CP-7). Assigns an Azure Policy definition that audits virtual machines without disaster recovery configured.
Identification and authentication (IA)
Network access to privileged accounts (IA-2). Assigns Azure Policy definitions to audit accounts with the owner and write permissions that don't have multi-factor authentication enabled.
Authenticator management (IA-5). Assigns policy definitions that audit the configuration of the password encryption type for Windows virtual machines.
Risk assessment (RA)
RA-5 Vulnerability scanning (RA-5). Assigns policy definitions that audit and enforce Advanced Data Security on SQL servers as well as help with the management of other information system vulnerabilities.
Systems and communications protection (SC)
Denial of service protection (SC-5). Assigns an Azure Policy definition that audits if the distributed denial-of-service (DDoS) standard tier is enabled.
Boundary protection (SC-7). Assigns Azure Policy definitions that monitor for network security group hardening recommendations as well as monitor virtual machines that can support just-in-time access but haven't yet been configured.
Transmission confidentiality and integrity (SC-8). Assigns Azure Policy definitions that help you monitor cryptographic mechanisms implemented for communications protocols.
Protection of information at rest (SC-28). Assigns Azure Policy definitions that enforce specific cryptograph controls and audit the use of weak cryptographic settings.
System and information integrity (SI)
Flaw remediation (SI-2). Assigns Azure Policy definitions that monitor missing system updates, operating system vulnerabilities, SQL vulnerabilities, and virtual machine vulnerabilities.
Malicious code protection (SI-3). Assigns Azure Policy definitions that monitor for missing endpoint protection on virtual machines and enforces the Microsoft antimalware solution on Windows virtual machines.
Information system monitoring (SI-4). Assigns policies that audit and enforce deployment of the Log Analytics agent, and enhanced security settings for SQL databases, storage accounts, and network resources.
Azure tenants seeking to comply with FedRAMP should note that although the FedRAMP Blueprints controls may help customers assess compliance with particular controls, they do not ensure full compliance with all requirements of a control. In addition, controls are associated with one or more Azure Policy definitions, and the compliance standard includes controls that aren't addressed by any Azure Policy definitions in blueprints at this time. Therefore, compliance in Azure Policy will only consist of a partial view of your overall compliance status.
Customers are ultimately responsible for meeting the compliance requirements applicable to their environments and must determine for themselves whether particular information helps meet their compliance needs.
What should we do this weekend? Whether you are visiting a new city or just at home, it's a question many of us ask ourselves as the weekend approaches. Without exciting plans in mind, we could be stuck, wondering, "Are there any local events going on? What bands are in town? Where can I go for a good brunch?"
Wonder no more.
Seeingit.com is a website built with the community in mind. Founder, Randall Harmon, describes it as a place to "share your community", empowering locals, businesses, and event coordinators to share what’s going on.
“Have you ever missed out? On many occasions, a person in their lifetime could have missed out on activities and events that otherwise would have enriched their lives. Being crowd-sourced and location based, Seeingit.com was devised to enhance accessibility to special offers from local businesses, community events, and fun things to see and do in real-time,” explains Harmon.
Say goodbye to FOMO (Fear of Missing Out).
To achieve this, Harmon worked with Microsoft Gold Partner, Fullestop, to build an interactive, self-serve publishing website for businesses to post promotions and for locals to alert residents of community events and fun things to see and do. The process is enabled by using a form-based system on a Microsoft ASP.NET MVC platform with all location-based capabilities powered by the Bing Maps Platform.
"The whole suite of Bing Maps products like geocoding, entities, and subcategories fit perfectly with our business model. Married with the content users were providing, it put it all into the context." Harmon says.
Our team had a chance to connect with the Harmon and the Fullestop team to talk about what Bing Maps services they are using, some of the technical details around the implementation, and how Bing Maps is helping their users find out what’s going locally and never miss out. Below is that Q&A:
Q: What Bing Maps services are you using with seeingit.com?
SeeingIt.com is using Bing Maps Locations API to get the address of a user's current location. The required parameters are latitude and longitude, which we fetched using Bing Maps REST Toolkit as well as HTML5 based "navigator.geolocation" property.
Q: Why is mapping so important for seeingit.com and your user’s experience on the website?
With Bing Maps Locations API, Seeingit.com can offer immediate, real-time promotion access and provide accurate directions (driving, walking or via public transit) to event locations or businesses. Users can easily determine transportation method with consideration of travel time.
Q: How were Bing Entities being used in the solution?
Without Bing Entities, Seeingit.com would be reliant on expensive business database services to provide business listings in a format that could be displayed on our local page. Otherwise a business owner would have to manually input their business information through our forms. This is still an option, but with Bing Entities when a business is displayed, they can claim their listing and begin to self-promote immediately. For website users, Bing Entities provides a more straightforward website utilization experience.
From a more technical perspective, we have used Point of Interest (POI) Entities from Bing Spatial Data Services to get the information (Entity Properties) and display the list of records in Listing Section of the website based on the user's Current Location with the help of Bing Maps Locations API.
Q: How did geocoding (and reverse geocoding), entities, and subcategories fit into the website’s business model?
Seeingit.com is reliant on an accurate user location service, it is requested immediately upon website use. We therefore can handle and deliver nearby businesses and event locations, serving directions, mileage and transportation modality information instantly. Our categories and subcategories are in-line with the top-level type IDs used by the Bing Maps APIs. For a user, Seeingit.com is a resource of information for where we as consumers spend time and money and the provided categories and subcategories are most common.
Q: Why did you choose Bing Maps for that solution? Was performance a factor?
It was the ease of integration, reliable and quick service for our users.
Q: How does using the Bing Maps services help differentiate seeingit.com from other websites? Do the technologies provide a competitive advantage?
Bing Maps services are essential for any Community and Consumer based website. Seeingit.com, with its Geolocation feature, removes the need to input a starting address location to a destination, simplifying and speeding up access to it.
Seeingit.com serves businesses as a one-stop, real-time marketing solution that helps connect them with their community by publishing to social media, Amazon Alexa voice service, to their website and ours. With Bing entities being automatically displayed, millions of businesses can now claim their listing and start with promotions and connect with their local audience immediately.
Q: What other benefits are you seeing? Did you save time and/or cut costs with the implementation?
Yes, as Microsoft has very detailed explanation for APIs on its site, which makes the APIs easy to understand and implement for developers. In line with industry standards, most of the APIs return JSON format data, which can be easily integrated in any application. We faced an issue with one API, but Microsoft support helped us solve the issue and integrations.
With Bing Maps and Bing Entities it was an obvious single source solution that helped our website become published earlier and accessible to a national audience more rapidly. Our developers being well trained and Microsoft Certified, had the tools, resources and support that enabled them and proceed without any delays.
To learn more about the Bing Maps Platform and the technologies Seeingit.com is using, go to https://www.microsoft.com/maps. Also, check out our documentation for even more technical details.
How much time do you think you spend looking for things at work? Because our files and information are stored in so many places it’s probably quite a bit. In fact, according to McKinsey, we spend 20% of our work week just searching for internal information, tracking down colleagues, and trying to pick up where we left off. That’s one whole day a week.
That’s why we’re excited for you to try a new way to manage your work with the new Microsoft Edge, now available in Microsoft Edge Insider preview builds. When signed in with an Azure Active Directory work account, opening a new tab in Microsoft Edge delivers a dynamic and personalized set of your most relevant Office documents, internal web sites, company resources, and other Microsoft 365 content.
Each new tab layout is populated by features that leverage the intelligence of the Office 365 graph to find what you need, right when you need it.
Microsoft Search in Bing: Search bar for the web and the intranet; find people, documents, and internal sites, just by searching.
Dynamic Site Tiles: Below the search bar you’ll find a set of tiles populated with your most commonly used websites or important internal sites configured by a company admin.
Recommended Content: Easy access to recently shared or often accessed files that are most important to you and your team.
Recent files & sites: Immediately below Recommended documents are lists of recent Office files (on the left) and frequently used SharePoint sites (on the right).
Content and Layout Selection: An easy toggle allows navigation between content feeds (‘Office 365’ and ‘Microsoft News’)
Please check out the additional details on the capabilities below, then try it yourself by downloading a Microsoft Edge Insider build. Tell us what you like, what doesn’t work for you, and anything else you think could help you find your flow on the Enterprise new tab experience.
Microsoft Search in Bing
If you’re looking for something you haven’t used in a while, just perform a search. Artificial intelligence technology from Bing and personalized insights from the Microsoft Graph connect you to the best of the web and work in a single experience. Whether you’re working in SharePoint, OneDrive, Office, or Bing, and communicating with Microsoft Teams or Yammer, you can search all of your files and conversations in one place, giving you the information you need, right when you need it most. Try searching for a document, conversation, colleague, or even yourself. Click here to explore Microsoft Search in Bing. You can also click here to read documentation on how to get set up and running with Microsoft Search in Bing in your organization.
Dynamic Site Tiles
Eight tiles provide visual links back to the sites you use most; the algorithm to compute these is run locally on your device, based on your browsing history, also stored locally. No data needs to leave your machine for these to work. We’re also introducing a new policy enabling IT Administrators to program up to 3 of these tiles. These can be enabled via enforced policy, which pins the tile permanently or recommended policy, which allows more frequently used sites to replace that tile. Administrators will also specify the URL, title. Click here to learn more about this policy. To learn about all Microsoft Edge policies, click here.
Recommended Content
In the face of ever-expanding file, email, and discussion traffic, the Recommended Documents feature is the ‘magic’ that surfaces what you need most. It is the intelligence that monitors all file activity and uses machine learning to produce a short list of files, saving you time and allowing you to pick up right where you left off.
The Office Graph provides brains behind the Recommended content module. The Office Graph continuously collects and analyses signals that you and your colleagues send when you work in Office 365. For example, when you and a colleague modify or view the same document, it’s a signal that you’re likely to be working together. Other signals include who you communicate with through e-mail, and who you’ve shared documents with, who your manager is, and who has the same manager as you.
With Recommended content, you’ll be served a series of cards that provide information about the content and collaboration status of a few documents that we believe you should pay attention to. For example, a Microsoft Word file that has had 3 different edits in the last day, an Excel file where you’ve been @mentioned with a couple of questions, and an important presentation your team is working on with 5 unread comments.
Each card contains easily scannable information so you can quickly prioritize what to work on next without breaking your flow.
The center of the card: features a thumbnail so you can quickly recognize the file.
The top: features an icon to indicate what type of activity is most significant and who it was associated with and when the activity occurred.
At the bottom: of the card, you’ll find the file name as well as the location of the file for reference.
Another way to stay focused and in your workflow is to organize the work you’ve been doing most recently. That’s why, immediately below Recommended documents, you’ll see lists of recent files (on the left) and frequent SharePoint sites (on the right). Organized into 4 helpful views:
Recent: Your recently accessed files. Hovering over an item allows additional actions like pinning, sharing, and opening in browser or desktop.
Pinned: Filters your recent documents down to only those you’ve pinned.
Shared with me: A list of files that have been shared with you, whether you’ve recently opened them or not.
Discover: In discover, you’ll see a mix of both your own documents, and documents your colleagues are working on so you have additional awareness about team projects. These are documents that are stored in OneDrive for Business or SharePoint in Office 365, or that have been shared with you as attachments in emails. These documents aren’t organized according to a timeline, for example last modified, or in alphabetical order. Instead, these documents are organized according to what’s likely to be most relevant to you right now.
Settings Flyout
In the upper right is a quick way for you to switch back to the Microsoft News content & layout choices, and coming soon, the ability to choose various layouts that best suit your flow.
The Enterprise new tab experience integrates compliant M365 services and is architected so that your data stays within your organization’s boundaries.
Microsoft Search in Bing: Address bar and in-page search is supported by Microsoft Search in Bing. Explore the links in the “Microsoft Search in Bing” section to learn more about how your data is protected.
Dynamic Site Tiles: computed locally using local device data. For these, nothing leaves your device.
Office content: This content is powered by existing compliant M365 services like the Recommended Content service, recent file service, and recent SharePoint sites service.
We are looking forward for you to download the new Microsoft Edge and experience these new workflows to collect your feedback. Providing feedback is easy. Just click the smiley face in the top-right corner of the browser to let us know what you like or want to see improved:
In the meantime, we’re working on adding support for new and compliant ways for enterprise end users to and IT admins to personalize, configure, and use the Enterprise New Tab Page for productivity in their day-to-day workflows.
Thank you for trying out the new Microsoft Edge. We welcome your comments below!
– Chad Rothschiller, Senior Program Manager, Microsoft Edge
– Matt Betz, Product Marketing Manager, Microsoft Edge
At last week's Microsoft Ignite conference in Orlando, our team delivered a series of 6 talks about AI and machine learning applications with Azure. The videos from each talk are linked below, and you can watch every talk from the conference online (no registration necessary). Each of our talks also comes with a companion Github repository, where you can find all of the code and scripts behind the demonstrations, so you can deploy and run them yourself.
If you'd like to see these talks live, they will also be presented in 31 cities around the world over the next six months, starting with Paris this week. Check the website for Microsoft Ignite the Tour for event dates and further information.
AIML10 Making sense of your unstructured data with AI
Tailwind Traders has a lot of legacy data that they’d like their developers to leverage in their apps – from various sources, both structured and unstructured, and including images, forms, and several others. In this session, learn how the team used Azure Cognitive Search to make sense of this data in a short amount of time and with amazing success. We discuss tons of AI concepts, like the ingest-enrich-explore pattern, search skillsets, cognitive skills, natural language processing, computer vision, and beyond.
AIML20 Using pre-built AI to solve business challenges
As a data-driven company, Tailwind Traders understands the importance of using artificial intelligence to improve business processes and delight customers. Before investing in an AI team, their existing developers were able to demonstrate some quick wins using pre-built AI technologies.
In this session, we show how you can use Azure Cognitive Services to extract insights from retail data and go into the neural networks behind computer vision. Learn how it works and how to augment the pre-built AI with your own images for custom image recognition applications.
In this theater session, we show the data science process and how to apply it. From exploration of datasets to deployment of services - all applied to an interesting data story. We also take you on a very brief tour of the Azure AI platform.
AIML30: Start building machine learning models faster than you think
Tailwind Traders uses custom machine learning models to fix their inventory issues – without changing their software development life cycle! How? Azure Machine Learning Visual Interface.
In this session, learn the data science process that Tailwind Traders’ uses and get an introduction to Azure Machine Learning Visual Interface. See how to find, import, and prepare data, select a machine learning algorithm, train and test the model, and deploy a complete model to an API. Get the tips, best practices, and resources you and your development team need to continue your machine learning journey, build your first model, and more.
AIML40 Taking models to the next level with Azure Machine Learning best practices
Tailwind Traders’ data science team uses natural language processing (NLP), and recently discovered how to fine tune and build a baseline models with Automated ML.
In this session, learn what Automated ML is and why it’s so powerful, then dive into how to improve upon baseline models using examples from the NLP best practices repository. We highlight Azure Machine Learning key features and how you can apply them to your organization, including: low priority compute instances, distributed training with auto scale, hyperparameter optimization, collaboration, logging, and deployment.
AIML50 Machine learning operations: Applying DevOps to data science
Many companies have adopted DevOps practices to improve their software delivery, but these same techniques are rarely applied to machine learning projects. Collaboration between developers and data scientists can be limited and deploying models to production in a consistent, trustworthy way is often a pipe dream.
In this session, learn how Tailwind Traders applied DevOps practices to their machine learning projects using Azure DevOps and Azure Machine Learning Service. We show automated training, scoring, and storage of versioned models, wrap the models in Docker containers, and deploy them to Azure Container Instances or Azure Kubernetes Service. We even collect continuous feedback on model behavior so we know when to retrain.
There are substantial enhancements to multiple-file transfers (up and down). You can supply a vector of pathnames to storage_upload/download as the source and destination arguments. Alternatively if you specify a wildcard source, there is now the ability to recurse through subdirectories; the directory structure in the source will be reproduced at the destination.
There are revamped methods for getting storage properties and (user-defined) metadata for storage objects.
You can now use Azurite with AzureStor, by creating a service_specific endpoint (file_endpoint, blob_endpoint, adls_endpoint) with the Azurite URL. AzureStor will print a warning, but create the endpoint anyway.
For other changes, see the NEWS.md file.
AzureVM 2.1.0
You can now create VM scalesets with attached data disks. In addition, you can specify the disk type (Standard_LRS, StandardSSD_LRS, or Premium_LRS) for the OS disk and, for a Linux Data Science Virtual Machine, the supplied data disk. This enables using VM sizes that don't support Premium storage.
AzureGraph 1.1.0 and AzureContainers 1.1.2
These packages have been updated to use the new Microsoft Graph operations, introduced last week, for managing app passwords. As a security measure, app passwords can no longer be manually specified; instead they are auto-generated on the server using a cryptographically secure PRNG.
In AzureGraph, the az_app$update_password() method is defunct; in its place are add_password() and remove_password(). Similarly, in AzureContainers the aks$update_service_password() and aks$update_aad_password() methods no longer accept a manual password as an input.
If you use Graph, and in particular if you use AzureContainers to deploy Azure Kubernetes Service clusters, you should update as soon as possible, as the old versions are incompatible with the new Graph API.
If you run into any problems, please open an issue at the GitHub repo in question.
ML.NET is a cross-platform, machine learning framework for .NET developers, and Model Builder is the UI tooling in Visual Studio that uses Automated Machine Learning (AutoML) to easily allow you to train and consume custom ML.NET models. With ML.NET and Model Builder, you can create custom machine learning models for scenarios like sentiment analysis, price prediction, and more without any machine learning experience!
ML.NET Model Builder
This release of Model Builder comes with bug fixes and two exciting new features:
Image classification scenario – locally train image classification models with your own images
Try your model – make predictions on sample input data right in the UI
Image Classification Scenario
We showed off this feature in .NET Conf to classify the weather in images as either sunny, cloudy, or rainy, and now you can locally train image classification models in Model Builder with your own images!
For example, say you have a dataset of images of dogs and cats, and you want to use those images to train an ML.NET model that classifies new images as “dog” or “cat.”
Your dataset must contain a parent folder with labelled subfolders for each category (e.g. a folder called Animals that contains two sub-folders: one named Dog, which contains training images of dogs, and one named Cat, which contains training images of cats):
You can use the Next Steps code and projects generated by Model Builder to easily consume the trained image classification model in your end-user application, just like with text scenarios.
Try Your Model
After training a model in Model Builder, you can use the model to make predictions on sample input right in the UI for both text and image scenarios.
For instance, for the dog vs. cat image classification example, you could input an image and see the results in the Evaluate step of Model Builder:
If you have a text scenario, like price prediction for taxi fare, you can also input sample data in the Try your model section:
Give Us Your Feedback
If you run into any issues, feel that something is missing, or really love something about ML.NET Model Builder, let us know by creating an issue in our GitHub repo.
Model Builder is still in Preview, and your feedback is super important in driving the direction we take with this tool!
Get Started with Model Builder
You can download ML.NET Model Builder in the VS Marketplace (or in the Extensions menu of Visual Studio).
Today, we released a new Windows 10 Preview Build of the SDK to be used in conjunction with Windows 10 Insider Preview (Build 19018 or greater). The Preview SDK Build 19018 contains bug fixes and under development changes to the API surface area.
This build works in conjunction with previously released SDKs and Visual Studio 2017 and 2019. You can install this SDK and still also continue to submit your apps that target Windows 10 build 1903 or earlier to the Microsoft Store.
The Windows SDK will now formally only be supported by Visual Studio 2017 and greater. You can download the Visual Studio 2019 here.
Now detects the Unicode byte order mark (BOM) in .mc files. If the If the .mc file starts with a UTF-8 BOM, it will be read as a UTF-8 file. Otherwise, if it starts with a UTF-16LE BOM, it will be read as a UTF-16LE file. If the -u parameter was specified, it will be read as a UTF-16LE file. Otherwise, it will be read using the current code page (CP_ACP).
Now avoids one-definition-rule (ODR) problems in MC-generated C/C++ ETW helpers caused by conflicting configuration macros (e.g. when two .cpp files with conflicting definitions of MCGEN_EVENTWRITETRANSFER are linked into the same binary, the MC-generated ETW helpers will now respect the definition of MCGEN_EVENTWRITETRANSFER in each .cpp file instead of arbitrarily picking one or the other).
Windows Trace Preprocessor (tracewpp.exe)
Now supports Unicode input (.ini, .tpl, and source code) files. Input files starting with a UTF-8 or UTF-16 byte order mark (BOM) will be read as Unicode. Input files that do not start with a BOM will be read using the current code page (CP_ACP). For backwards-compatibility, if the -UnicodeIgnore command-line parameter is specified, files starting with a UTF-16 BOM will be treated as empty.
Now supports Unicode output (.tmh) files. By default, output files will be encoded using the current code page (CP_ACP). Use command-line parameters -cp:UTF-8 or -cp:UTF-16 to generate Unicode output files.
Behavior change: tracewpp now converts all input text to Unicode, performs processing in Unicode, and converts output text to the specified output encoding. Earlier versions of tracewpp avoided Unicode conversions and performed text processing assuming a single-byte character set. This may lead to behavior changes in cases where the input files do not conform to the current code page. In cases where this is a problem, consider converting the input files to UTF-8 (with BOM) and/or using the -cp:UTF-8 command-line parameter to avoid encoding ambiguity.
TraceLoggingProvider.h
Now avoids one-definition-rule (ODR) problems caused by conflicting configuration macros (e.g. when two .cpp files with conflicting definitions of TLG_EVENT_WRITE_TRANSFER are linked into the same binary, the TraceLoggingProvider.h helpers will now respect the definition of TLG_EVENT_WRITE_TRANSFER in each .cpp file instead of arbitrarily picking one or the other).
In C++ code, the TraceLoggingWrite macro has been updated to enable better code sharing between similar events using variadic templates.
Signing your apps with Device Guard Signing
We are making it easier for you to sign your app. Device Guard signing is a Device Guard feature that is available in Microsoft Store for Business and Education. Signing allows enterprises to guarantee every app comes from a trusted source. Our goal is to make signing your MSIX package easier. Documentation on Device Guard Signing can be found here: https://docs.microsoft.com/en-us/windows/msix/package/signing-package-device-guard-signing
Windows SDK Flight NuGet Feed
We have stood up a NuGet feed for the flighted builds of the SDK. You can now test preliminary builds of the Windows 10 WinRT API Pack, as well as a microsoft.windows.sdk.headless.contracts NuGet package.
We use the following feed to flight our NuGet packages.
Microsoft.Windows.SDK.Contracts which can be used with to add the latest Windows Runtime APIs support to your .NET Framework 4.5+ and .NET Core 3.0+ libraries and apps.
The Windows 10 WinRT API Pack enables you to add the latest Windows Runtime APIs support to your .NET Framework 4.5+ and .NET Core 3.0+ libraries and apps.
Microsoft.Windows.SDK.Headless.Contracts provides a subset of the Windows Runtime APIs for console apps excludes the APIs associated with a graphical user interface. This NuGet is used in conjunction with Windows ML container development. Check out the Getting Started Guide for more information.
Breaking Changes
Removal of api-ms-win-net-isolation-l1-1-0.lib
In this release api-ms-win-net-isolation-l1-1-0.lib has been removed from the Windows SDK. Apps that were linking against api-ms-win-net-isolation-l1-1-0.lib can switch to OneCoreUAP.lib as a replacement.
Removal of IRPROPS.LIB
In this release irprops.lib has been removed from the Windows SDK. Apps that were linking against irprops.lib can switch to bthprops.lib as a drop-in replacement.
Removal of WUAPICommon.H and WUAPICommon.IDL
In this release we have moved ENUM tagServerSelection from WUAPICommon.H to wupai.h and removed the header. If you would like to use the ENUM tagServerSelection, you will need to include wuapi.h or wuapi.idl.
Thank you webmasters for effectively using Adaptive URL solution to notify bingbot about your website’s most fresh and relevant content. But, did you know you don’t have to use the Bing webmaster tools portal to submit URLs?
Bing webmaster tools exposes programmatic access to its APIs for webmasters to integrate their workflows. Here is an example using the popular command line utility cURL that shows how easy it is to integrate the Submit URL single and Submit URL batch API end points. You can use Get url submission quota API to check remaining daily quota for your account.
Bing API can be integrated and called by all modern languages (C#, Python, PHP…), however, cURL can help you to prototype and test the API in minutes and also build complete solutions with minimal effort. cURL is considered as one of the most versatile tools for command-line API calls and is supported by all major Linux shells – simply run the below commands in a terminal window. If you're a Windows user, you can run cURL commands in Git Bash, the popular git client for Windows" (no need to install curl separately, Git Bash comes with curl). If you are a Mac user, you can install cURL using a package manager such as Homebrew.
When you try the examples below, be sure to replace API_KEY with your API key string obtained from Bing webmaster tools > Webmaster API > Generate. Refer easy set-up guide for Bing’s Adaptive URL submission API for more details.
ACR already supports several authentication options using identities that have role-based access to an entire registry. However, for multi-team scenarios, you might want to consolidate multiple teams into a single registry, limiting each team’s access to their specific repositories. Repository scoped RBAC now enables this functionality.
Here are some of the scenarios where repository scoped permissions might come in handy:
Limit repository access to specific user groups within your organization. For example, provide write access to developers who build images that target specific repositories, and read access to teams that deploy from those repositories.
Provide millions of IoT devices with individual access to pull images from specific repositories.
Provide an external organization with permissions to specific repositories.
In this release, we have introduced tokens as a mechanism to implement repository scoped RBAC permissions. A token is a credential used to authenticate with the registry. It can be backed by username and password or Azure Active Directory(AAD) objects like Azure Active Directory users, service principals, and managed identities. For this release, we have provided tokens backed by username and password. Future releases will support tokens backed by Azure Active Directory objects like Azure Active Directory users, service principals, and managed identities. See Figure 1.
*Support for Azure Active Directory (AAD) backed token will be available in a future release.
Figure 1
Figure 2 below describes the relationship between tokens and scope-maps.
A token is a credential used to authenticate with the registry. It has a permitted set of actions which are scoped to one or more repositories. Once you have generated a token, you can use it to authenticate with your registry. You can do a docker login using the following command:
A scope map is a registry object that groups repository permissions you apply to a token. It provides a graph of access to one or more repositories. You can apply scoped repository permissions to a token or reapply them to other tokens. If you don't apply a scope map when creating a token, a scope map is automatically created for you, to save the permission settings.
A scope map helps you configure multiple users with identical access to a set of repositories.
Figure 2
As customers use containers and other artifacts for their IoT deployment, the number of devices can grow into the millions. In order to support the scale of IoT, Azure Container Registry has implemented repository based RBAC, using tokens (figure 3). Tokens are not a replacement for service principals or managed identities. You can add tokens as an additional option providing scalability of IoT deployment scenarios.
This article shows how to create a token with permissions restricted to a specific repository within a registry. With the introduction of token-based repository permissions, you can now provide users or services with scoped and time-limited access to repositories without requiring an Azure Active Directory identity. In the future, we will support tokens backed by Azure Active Directory objects. Check out this new feature and let us know your feedback on GitHub.
Figure 3
Availability and feedback
Azure CLI experience is now in preview. As always, we love to hear your feedback on existing features as well as ideas for our product roadmap.
GitHub Actions make it possible to create simple yet powerful workflows to automate software compilation and delivery integrated with GitHub. These actions, defined in YAML files, allow you to trigger an automated workflow process on any GitHub event, such as code commits, creation of Pull Requests or new GitHub Releases, and more.
As GitHub just announced the public availability of their Actions feature today, we’re announcing that the GitHub Actions for Azure are now generally available.
You can find all the GitHub Actions for Azure and their repositories listed on GitHub with documentation and sample templates to help you easily create workflows to build, test, package, release and deploy to Azure, following a push or pull request.
You can also use Azure starter templates to easily create GitHub CI/CD workflows targeting Azure to deploy your apps created with popular languages and frameworks including .NET, Node.js, Java, PHP, Ruby, or Python, in containers or running on any operating system.
Connect to Azure
Authenticate your Azure subscription using the Azure login(azure/login) action and a service principal. You can then run Azure CLI scripts to create and manage any Azure resource using the Azure CLI(azure/cli) action, which sets up the GitHub Action runner environment with the latest (or any user-specified) version of the Azure CLI.
Deploy a Web app
Azure App Service is a managed platform for deploying and scaling web applications. You can easily deploy your web app to Azure App Service with the Azure WebApp(azure/webapps-deploy)and Azure Web App for Containers(azure/webapps-container-deploy) actions. You could also configure App settings and Connection Strings using the Azure App Service Settings(azure/appservice-settings) action.
Streamline the deployment of your serverless applications to Azure Functions, an event-driven serverless compute platform, by bringing either your code using the Azure Functions action(azure/functions-action) or your custom container image using the Azure Functions for containers action(azure/functions-container-action) .
For containerized apps (single- or multi-containers) use the Docker Login action (azure/docker-login) to create a complete workflow to build container images, push to a container registry (Docker Hub or Azure Container Registry), and then deploy the images to an Azure web app, Azure Function for Containers, or to Kubernetes.
Deploy to Kubernetes
We have released multiple actions and to help you connect to a Kubernetes cluster running on-premises or on any cloud (including Azure Kubernetes Service), bake and deploy manifests, substitute artifacts, check rollout status, and handle secrets within the cluster.
Kubectl tool installer(azure/setup-kubectl): Installs a specific version of kubectl on the runner.
Kubernetes set context(azure/k8s-set-context): Used for setting the target Kubernetes cluster context which will be used by other actions or run any kubectl commands.
AKS set context(azure/aks-set-context): Used for setting the target Azure Kubernetes Service cluster context.
Kubernetes create secret(azure/k8s-create-secret): Create a generic secret or docker-registry secret in the Kubernetes cluster.
Kubernetes deploy(azure/k8s-deploy): Use this to deploy manifests to Kubernetes clusters.
Setup Helm(azure/setup-helm): Install a specific version of Helm binary on the runner.
Kubernetes bake(azure/k8s-bake): Use this action to bake manifest file to be used for deployments using Helm 2, kustomize, or Kompose.
To deploy to a cluster on Azure Kubernetes Service (AKS), you could use azure/aks-set-context to communicate with the AKS cluster, and then use azure/k8s-create-secret to create a pull image secret and finally use the azure/k8s-deploy to deploy the manifest files.
If you would like to deploy to an Azure Database for MySQL database using MySQL scripts, use the MySQL action (azure/mysql-action) instead.
Trigger a run in Azure Pipelines
GitHub Actions make it easy to build, test, and deploy your code right from GitHub, but you can also use it to trigger external CI/CD tools and services, including Azure Pipelines. If your workflow requires an Azure Pipelines run for deployment to a specific Azure Pipelines environment, as an example, the Azure Pipelines(azure/pipelines) action will enable you to trigger this run as part of your Actions workflow.
Utility Actions
Finally, we also released an action for variable substitutionMicrosoft/variable-substitution, which enables you to parameterize the values in JSON, XML, or YAML files (including configuration files, manifests, and more) within a GitHub Action workflow.
More coming soon
We will continue improving upon our available set of GitHub Actions, and will release new ones to cover more Azure services.
Please try out the GitHub Actions for Azure and share your feedback via Twitter on @Azure. If you encounter a problem, please open an issue on the GitHub repository for the specific action.
With reserved capacity, you get significant discounts over your on-demand costs by committing to long-term usage of a service. We are pleased to share reserved capacity offerings for the following additional services. With the addition of these services, we now support reservations for 16 services, giving you more options to save and get better cost predictability across more workloads.
Blob Storage (GPv2) and Azure Data Lake Storage (Gen2).
Azure Database for MySQL.
Azure Database for PostgreSQL.
Azure Database for MariaDB.
Azure Data Explorer.
Premium SSD Managed Disks.
Blob Storage (GPv2) and Azure Data Lake Storage (Gen2)
Save up to 38 percent on your Azure data storage costs by pre-purchasing reserved capacity for one or three years. Reserved capacity can be pre-purchased in increments of 100 TB and 1 PB sizes, and is available for hot, cool, and archive storage tiers for all applicable storage redundancies. You can also use the upfront or monthly payment option, depending on your cash flow requirements.
The reservation discount will automatically apply to data stored on Azure Blob (GPv2) and Azure Data Lake Storage (Gen2). Discounts are applied hourly on the total data stored in that hour. Unused reserved capacity doesn’t carry over.
Storage reservations are flexible, which means you can exchange or cancel your reservation should your storage requirements change in the future (limits apply).
Save up to 51 percent on your Azure Database costs for MySQL, PostgreSQL, and MariaDB by pre-purchasing reserved capacity. Reservation discount applies to the compute usage for these products and is available for both general-purpose and memory-optimized deployments. You can choose to pay monthly for the reservations.
As with all reservations, reservation discounts will automatically apply to the matching database deployments, so you don't need to do make any changes to your resources to get reservation discounts. The discount applies hourly on the compute usage. Unused reserved hours don't carry over.
You can exchange your reservations to move from general-purpose to memory-optimized, or vice-versa, any time after purchase. You can also cancel the reservation to receive a prorated amount back (limits apply).
Save up to 30 percent on your Azure Data Explorer Markup costs with reserved capacity. The reservation discount only applies on the markup meter, other charges, including compute and storage, are billed separately. You can also purchase reservations for virtual machines (VM) and storage to save even more on your total cost of ownership for Azure Data Explorer (Kusto) clusters. You can choose to pay monthly for the Azure Data Explorer markup reservations.
After purchase, the reservation discount will automatically apply to the matching cluster. The discount applies hourly on the markup usage. Unused reserved hours don't carry over. As usual, you can exchange or cancel the reservation should your needs change (limits apply).
Save up to 5 percent on your Premium SSD Managed Disk usage with reserved capacity. Discounts are applied hourly on the disks deployed in that hour regardless of whether the disks are attached to a VM. Unused reserved hours don't carry over. Reservation discount does not apply to Premium SSD Unmanaged Disks or Page Blobs consumption.
Disk reservations are flexible, which means you can exchange or cancel your reservation should your storage requirements change in the future (limits apply).
Over the past few years, we’ve seen significant changes in how an application is thought of and developed, especially with the adoption of containers and the move from traditional monolithic applications to microservices applications. This shift also affects how we think about modern application monitoring, now with greater adoption of open source technologies and the introduction of observability concepts.
In the past, vendors owned the application and infrastructure, and as a result, they knew what metrics to monitor. With open source products growing in number, vendors do not own all the metrics, and custom metrics are extremely necessary with current monitoring tools. Unlike the monolith application, which is a single deployment unit with a simple status of healthy or not, modern applications will consist of dozens of different microservices with fractional n-states. This is due to the sophisticated deployment strategies and rollbacks where customers may be running different versions of the same services in production, especially on Kubernetes. Thus, embracing these shifts is essential in monitoring.
Custom metrics and open source technologies help improve the observability of specific components of your application, but you also need to monitor the full stack. Azure Monitor for containers embraces both observability through live data and collecting custom metrics using Prometheus, providing the full stack end-to-end monitoring from nodes to Kubernetes infrastructure to workloads.
Collecting Prometheus metrics and viewing using Grafana dashboards
By instrumenting Prometheus SDK into your workloads, Azure Monitor for containers can scrape the metrics exposed from Prometheus end-points so you can quickly gather failure rates, response per secs, and latency. You can use Prometheus to collect some of the Kubernetes infrastructure metrics that are not provided out of the box by Azure Monitor by configuring the containerized agent.
From Log Analytics, you can easily run a Kusto Query Language (KQL) query and create your custom dashboard in the Azure portal dashboard. For many customers using Grafana to support their dashboard requirements, you can visualize the container and Prometheus metrics in a Grafana dashboard.
Below is an example of a dashboard that provides an end-to-end Azure Kubernetes Service (AKS) cluster overview, node performances, Kubernetes infrastructure, and workloads.
If you would like to monitor or troubleshoot other scenarios, such as list of all workload live sites, or noisy neighbor issues on a worker node, you can always switch to Azure Monitor for container to view the visualizations included from the Grafana dashboard by clicking on Azure Monitor – Container Insights in the top right-hand corner.
Azure Monitor for containers provides the live, real-time data of container logs and Kubernetes event logs to provide observability as seen above. You can see your deployments immediately and observe any anomalies using the live data.
If you are interested in trying Azure Monitor for containers, please check the documentation. Once you have enabled the monitoring, and if you would like to try the Grafana template, please go to the Grafana gallery. This template will light up using the out-of-the-box data collected from Azure Monitor for containers. If you want to add more charts to view other metrics collected, you can do so by checking our documentation.
Prometheus data collection and Grafana are also supported for AKS Engine as well.
For any feedback or suggestions, please reach out to us through Azure Community Support or Stack Overflow.






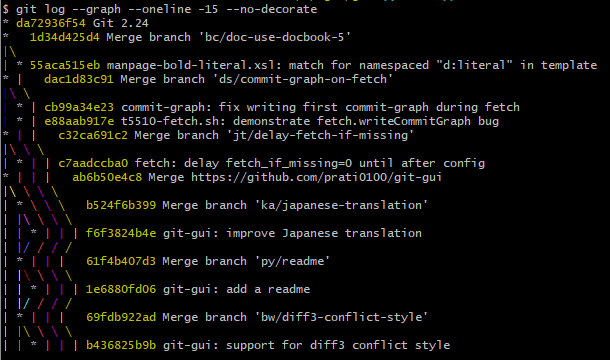
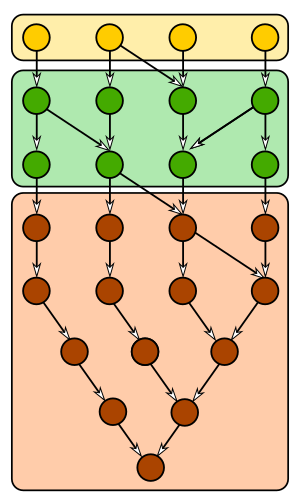
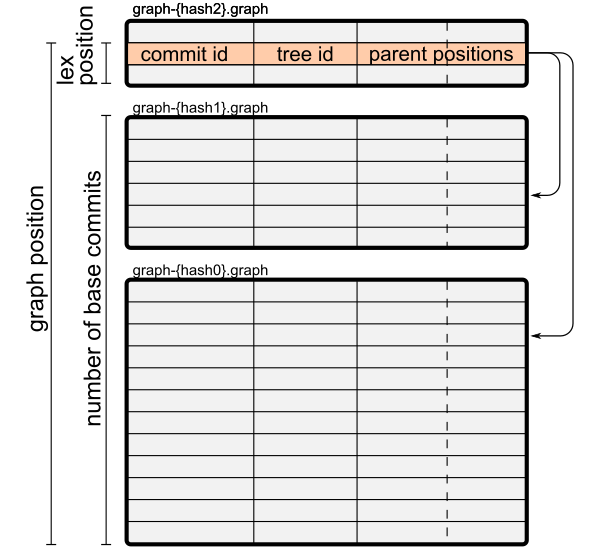











 Figure 2
Figure 2




