Visual Studio’s native support for CMake allows you to target both Windows and Linux from the comfort of a single IDE. Visual Studio 2019 version 16.5 Preview 2 introduces several new features specific to cross-platform development, including:
- File copy optimizations for CMake projects targeting a remote Linux system
- Native WSL support when separating your build system from your remote deploy system
- The ability to easily add, remove, and rename files in CMake projects
- CMake language services
- A command line utility to interact with the Connection Manager
- FIPS 140-2 compliance for remote C++ development
- IntelliSense improvements for both CMake projects and MSBuild-based solutions
File copy optimizations for CMake projects targeting a remote Linux system
Visual Studio automatically copies source files from your local Windows machine to your remote Linux system when building and debugging on Linux. In Visual Studio 2019 version 16.5 this behavior has been optimized. Visual Studio now keeps a “fingerprint file” of the last set of sources copied remotely and optimizes behavior based on the number of files that have changed.
- If no changes are identified, then no copy occurs.
- If only a few files have changed, then sftp is used to copy the files individually.
- If only a few directories have changed, then a non-recursive rsync command is issued to copy those directories.
- Otherwise, a rsync recursive copy is called from the first common parent directory of the changed files.
These improvements were tested against LLVM. A trivial change was made to a source file, which causes the remote source file copy to be called and the executable to be rebuilt when the user starts debugging.
| Debugging LLVM-objdump with no optimizations | Debugging LLVM-objdump with 16.5 optimizations | |
| Time elapsed for remote source file copy | 3 minutes and 24 seconds | 2 seconds |
With no optimizations, a full recursive rsync copy is executed from the CMake root. With these optimizations, Visual Studio detects that a single file has changed and uses sftp to re-copy only the file that has changed.
These optimizations are enabled by default. The following new options can be added to CMakeSettings.json to customize file copy behavior.
“remoteCopyOptimizations” : {
“remoteCopyUseOptmizations”: “RsyncAndSftp”
“rsyncSingleDirectoryCommandArgs”: “-t”
}
Possible values for remoteCopyOptimizations are RsyncAndSftp (default), RsyncOnly, and None (where a full recursive rsync copy is always executed from the CMake root). rsyncSingleDirectoryCommandArgs can be passed to customize rsync behavior when a non-recursive rsync command is issued (step 3 above). The existing properties remoteCopySources, rsyncCommandArgs (which are passed when a recursive rsync command is issued, step 4 above) and rsyncCopySourcesMethod can also be used to customize file copy behavior. Please see Additional settings for CMake Linux projects for more information.
Note that these performance improvements are specific to remote connections. Visual Studio’s native support for WSL can access files stored in the Windows filesystem, which eliminates the need to copy and maintain sources on a remote machine.
Native WSL support with the separation of build and deploy
Visual Studio 2019 version 16.1 introduced the ability to separate your remote build system from your remote deploy system. In Visual Studio 2019 version 16.5 this functionality has been extended to include our native support for WSL. Now, you can build natively on WSL and deploy/debug on a second remote Linux system connected over SSH.
Separation of build and deploy with CMake projects
The Linux system specified in the CMake Settings Editor is used for build. To build natively on WSL, navigate to the CMake Settings Editor (Configuration drop-down > Manage Configurations…) and add a new WSL configuration. You can select either WSL-GCC-Debug or WSL-Clang-Debug depending on which toolset you would like to use.
The remote Linux system specified in launch.vs.json is used for debugging. To debug on a second remote Linux system, add a new remote Linux configuration to launch.vs.json (right-click on the root CMakeLists.txt in the Solution Explorer > Debug and Launch Settings) and select C/C++ Attach for Linux (gdb). Please see launch.vs.json reference for remote Linux projects to learn more about customizing this configuration and properties specific to the separation of build and deploy.
Note that the C/C++ Attach for Linux (gdb) configuration is for debugging on remote Linux systems. If you want to build and debug on the same instance of WSL, add a C/C++ Launch for WSL configuration to launch.vs.json. More information on the entry points to launch.vs.json can be found here.
Separation of build and deploy with MSBuild-based Linux projects
The Linux system specified in the Linux Property Pages is used for build. To build natively on WSL, navigate to Configuration Properties > General and set the Platform Toolset. You can select either GCC for Windows Subsystem for Linux or Clang for Windows Subsystem for Linux depending on which toolset you would like to use. Click “Apply.”
By default, Visual Studio builds and debugs in WSL. To specify a second remote system for debugging, navigate to Configuration Properties > Debugging and set Remote Debug Machine to one of the specified remote connections. You can add a new remote connection via the Connection Manager. You can also specify a path to the directory on the remote system for the project to deploy to via Remote Deploy Directory.
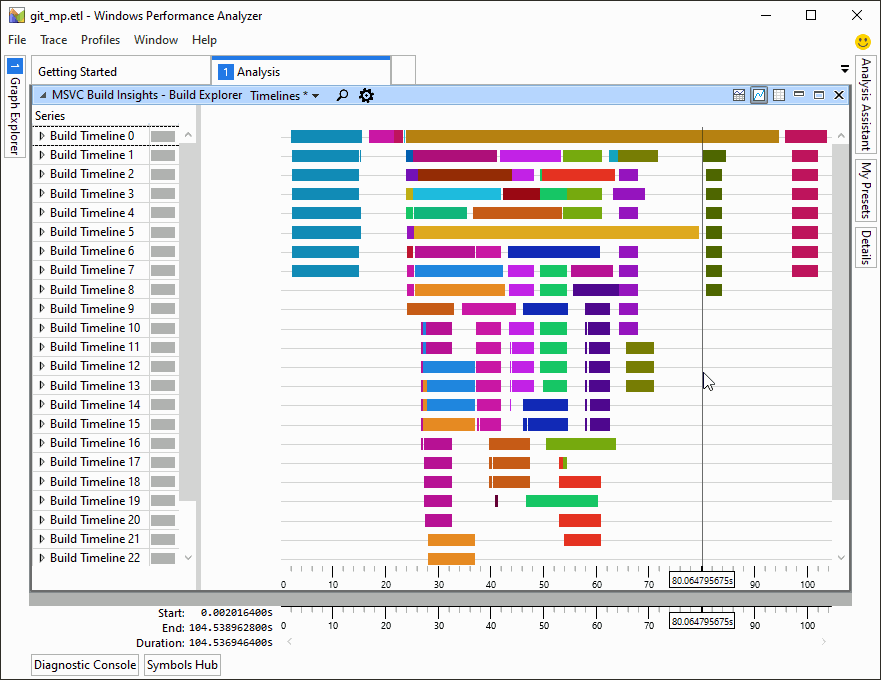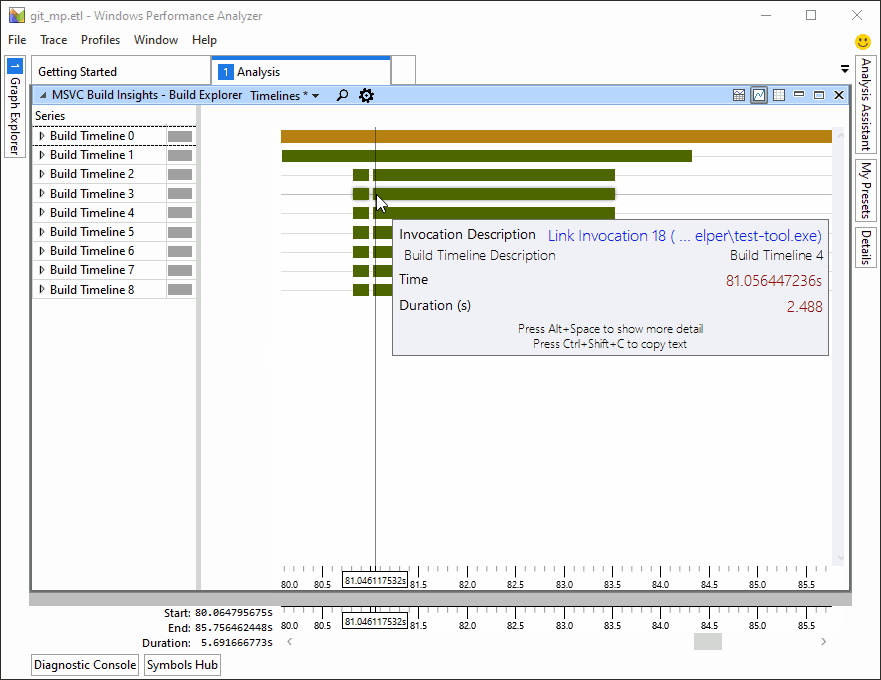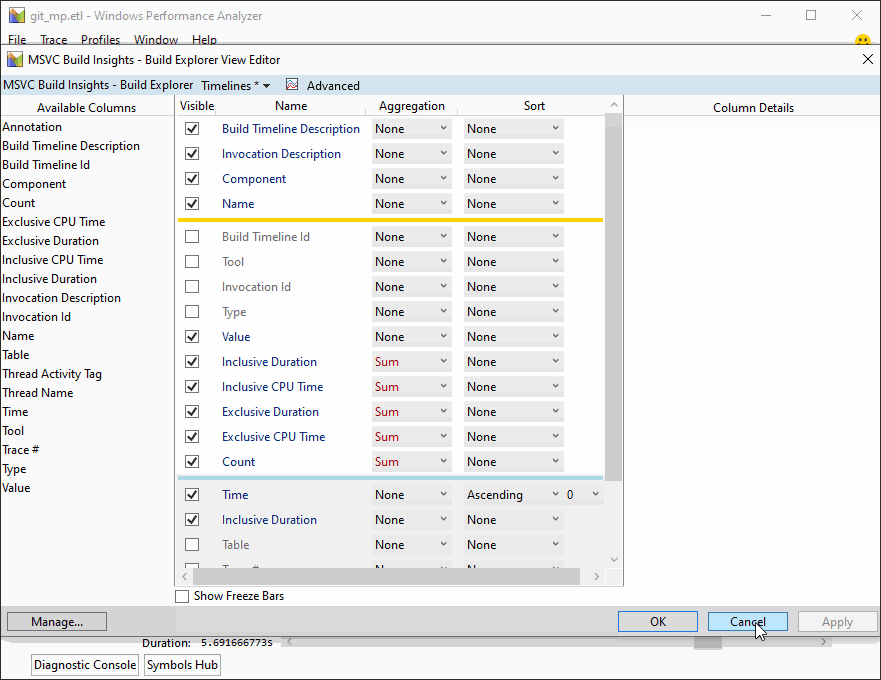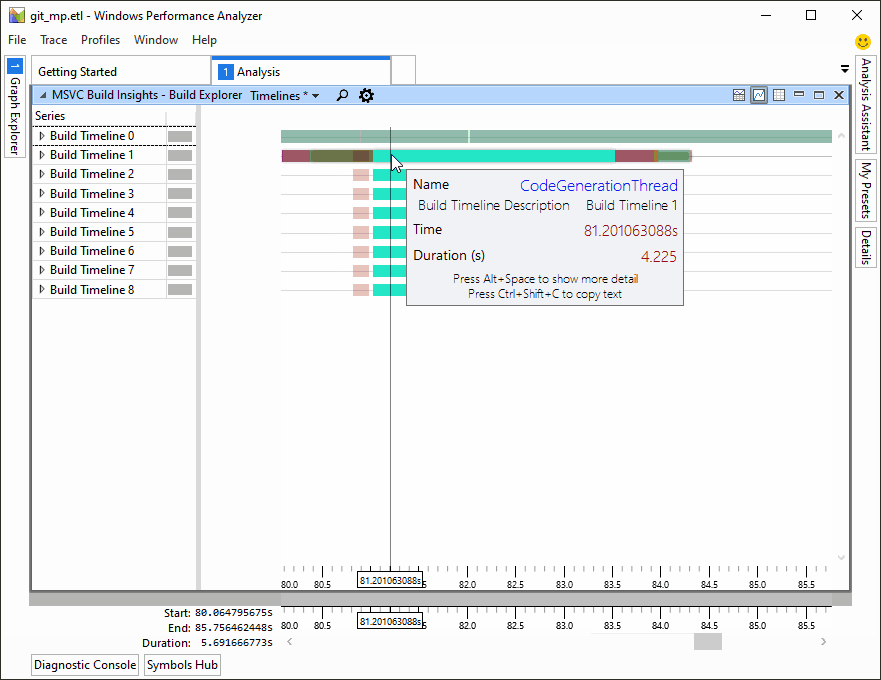
Easily add, remove, and rename files in CMake projects
It’s easier than ever to work with CMake projects in Visual Studio. In the latest preview, you can add, remove, and rename source files and targets in your CMake projects from the IDE without manually editing your CMake scripts. When you add or remove files with the Solution Explorer, Visual Studio will automatically edit your CMake project. You can also add, remove, and rename the project’s targets from the Solution Explorer’s targets view.

In some cases, there may be more than one place where it makes sense to add a source file to a CMake script. When this happens, Visual Studio will ask you where you want to make the change and display a preview of the proposed modifications:

This feature is enabled by default as of Visual Studio 2019 15.5 Preview 2, but it can be turned off in Tools > Options > CMake, “Enable automatic CMake script modification…”
CMake language services
The latest Visual Studio preview also makes it easy to make sense of complex CMake projects. Code navigation features such as Go To Definition and Find All References are now supported for variables, functions, and targets in CMake script files.

These navigation features work across your entire CMake project to offer more productivity than naïve text search across files and folders, and are integrated with other IDE productivity features such as Peek Definition. Stay tuned for more information on both CMake features in standalone blog posts coming soon.
Command line utility to interact with the Connection Manager
In Visual Studio 2019 version 16.5 or later you can use a command line utility to programmatically add and remove remote connections from the connection store. This is useful for tasks such as provisioning a new development machine or setting up Visual Studio in continuous integration. Full documentation on the utility including usage, commands, and options can be found here.
FIPS 140-2 compliance for remote C++ development
Federal Information Processing Standard (FIPS) Publication 140-2 is a U.S. government standard for cryptographic models. Implementations of the standard are validated by NIST. Starting with Visual Studio version 16.5 remote Linux development with C++ is FIPS 140-2 compliant. You can follow our step-by-step instructions to set up a secure, FIPS-compliant connection between Visual Studio and your remote Linux system.
IntelliSense improvements
IntelliSense now displays more readable type names when dealing with the Standard Library. For example, in the Quick Info tooltip std::_vector_iterator<int> becomes_std::vector<int>::iterator.
We’ve also added the ability to toggle whether Enter, Space, and Tab function as commit characters, and to toggle whether Tab is used to Insert Snippet. Whether using a CMake or MSBuild project, you can find these settings under Tools > Options > Text Editor > C/C++ > Advanced > IntelliSense.

Give us your feedback
Download Visual Studio 2019 version 16.5 Preview 2 today and give it a try. We’d love to hear from you to help us prioritize and build the right features for you. We can be reached via the comments below, Developer Community, email (visualcpp@microsoft.com), and Twitter (@VisualC). The best way to file a bug or suggest a feature is via Developer Community.
The post CMake, Linux targeting, and IntelliSense improvements in Visual Studio 2019 version 16.5 Preview 2 appeared first on C++ Team Blog.

 The i2 self-powered heating system.
The i2 self-powered heating system. 
 Grid Logic capacity heatmap for a part of Norwegian DSO BKK Nett’s grid.
Grid Logic capacity heatmap for a part of Norwegian DSO BKK Nett’s grid.













 bridge the gap between pharmaceutical companies and physicians. Designed as a “virtual pharmaceutical representative,” this IoT-enabled device offers real-time, secure communications between the physician and the pharmaceutical company. With this single device, physicians can order a sample, request a visit from a medical science liaison (MSL) or sales rep, or connect with the pharmaceutical company’s inside sales rep (as shown in the graphic below).
bridge the gap between pharmaceutical companies and physicians. Designed as a “virtual pharmaceutical representative,” this IoT-enabled device offers real-time, secure communications between the physician and the pharmaceutical company. With this single device, physicians can order a sample, request a visit from a medical science liaison (MSL) or sales rep, or connect with the pharmaceutical company’s inside sales rep (as shown in the graphic below). Built on our Azure IoT platform, Swittons takes advantage of the latest in cloud, security, telecommunications, and analytics technology. “We strategically selected Azure IoT as the foundation for our Swittons ‘Virtual Rep.’ Microsoft’s vision, investments and the breadth of Azure cloud were the key criteria for selection. Having a reliable IoT platform along with world-class data and security infrastructure in Azure made the choice very easy,” commented Anupam Nandwana, CEO, P360, parent company of Swittons.
Built on our Azure IoT platform, Swittons takes advantage of the latest in cloud, security, telecommunications, and analytics technology. “We strategically selected Azure IoT as the foundation for our Swittons ‘Virtual Rep.’ Microsoft’s vision, investments and the breadth of Azure cloud were the key criteria for selection. Having a reliable IoT platform along with world-class data and security infrastructure in Azure made the choice very easy,” commented Anupam Nandwana, CEO, P360, parent company of Swittons.