Few months ago we announced an experimental release of OData for ASP.NET Core 3.1, and for those who could move forward with their applications without leveraging endpoint routing, the release was considered final, although not ideal.
But for those who have existing APIs or were planning to develop new APIs leveraging endpoint routing, the OData 7.3.0 release didn’t quiet meet their expectations without having to disable endpoint routing.
Understandably this was quiet a trade off between leveraging the capabilities of endpoints routing versus being able to use OData. Therefore in the past couple of months the OData team in coordination with ASP.NET team have worked together to achieve the desired compatibility between OData and Endpoint Routing to work seamlessly and offer the best capabilities of both worlds to our libraries consumers.
Today, we announce that this effort is over! OData release of 7.4.0 now allows using Endpoint Routing, which brings in a whole new spectrum of capabilities to take your APIs to the next level with the least amount of effort possible.
Getting Started
To fully bring this into action, we are going to follow the Entity Data Model (EDM) approach, which we have explored previously by disabling Endpoint Routing, so let’s get started.
We are going to create an ASP.NET Core Application from scratch as follows:
![Image New Web Application]()
Since the API template we are going to select already comes with an endpoint to return a list of weather forecasts, let’s name our project WeatherAPI, with ASP.NET Core 3.1 as a project configuration as follows:
![Image New API]()
Installing OData 7.4.0 (Beta)
Now that we have created a new project, let’s go ahead and install the latest release of OData with version 7.4.0 by either using PowerShell command as follows:
Install-Package Microsoft.AspNetCore.OData -Version 7.4.0-beta
You can also navigate to the Nuget Package Manager as follows:
![Image ODataWithContextBeta]()
Startup Setup
Now that we have the latest version of OData installed, and an existing controller for weather forecasts, let’s go ahead and setup our startup.cs file as follows:
using System.Linq;
using Microsoft.AspNet.OData.Builder;
using Microsoft.AspNet.OData.Extensions;
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Hosting;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
using Microsoft.OData.Edm;
namespace WeatherAPI
{
public class Startup
{
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers();
services.AddOData();
}
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseHttpsRedirection();
app.UseRouting();
app.UseAuthorization();
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
endpoints.Select().Filter().OrderBy().Count().MaxTop(10);
endpoints.MapODataRoute("odata", "odata", GetEdmModel());
});
}
private IEdmModel GetEdmModel()
{
var odataBuilder = new ODataConventionModelBuilder();
odataBuilder.EntitySet<WeatherForecast>("WeatherForecast");
return odataBuilder.GetEdmModel();
}
}
}
As you can see in the code above, we didn’t have to disable EndpointRouting as we used to do in the past in the ConfigureServices method, you will also notice in the Configure method has all OData configurations as usual referencing creating an entity data model with whatever prefix we choose, in our case here we set it to odata but you can change that to virtually anything you want, including api.
Weather Forecast Model
Before you run your API, you will need to do a slight change to the demo WeatherForecast model that comes in with the API template, which is adding a key to it, otherwise OData wouldn’t know how to operate on a keyless model, so we are going to add an Id of type GUID to the model, and this is how the WeatherForecast model would look like:
public class WeatherForecast
{
public Guid Id { get; set; }
public DateTime Date { get; set; }
public int TemperatureC { get; set; }
public int TemperatureF => 32 + (int)(TemperatureC / 0.5556);
public string Summary { get; set; }
}
Weather Forecast Controller
We had to enable OData querying on the weather forecast endpoint while removing all the other unnecessary annotations, this is how our controller looks like:
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AspNet.OData;
using Microsoft.AspNetCore.Mvc;
using Microsoft.Extensions.Logging;
namespace WeatherAPI.Controllers
{
public class WeatherForecastController : ControllerBase
{
private static readonly string[] Summaries = new[]
{
"Freezing", "Bracing", "Chilly", "Cool", "Mild", "Warm", "Balmy", "Hot", "Sweltering", "Scorching"
};
[EnableQuery]
public IEnumerable<WeatherForecast> Get()
{
var rng = new Random();
return Enumerable.Range(1, 5).Select(index => new WeatherForecast
{
Id = Guid.NewGuid(),
Date = DateTime.Now.AddDays(index),
TemperatureC = rng.Next(-20, 55),
Summary = Summaries[rng.Next(Summaries.Length)]
})
.ToArray();
}
}
}
Hit Run
Now that we have everything in place, let’s run our API and hit our OData endpoint with an HTTP GET request as follows:
https://localhost:44344/odata/weatherforecast
The following result should be returned:
{
"@odata.context": "https://localhost:44344/odata/$metadata#WeatherForecast",
"value": [
{
"Id": "66b86d0d-375f-4133-afb4-82b44f7f2e79",
"Date": "2020-03-02T23:07:52.4084956-08:00",
"TemperatureC": 23,
"Summary": "Mild"
},
{
"Id": "d534a764-4fb8-4f49-96c5-8f09987a61d8",
"Date": "2020-03-03T23:07:52.4085408-08:00",
"TemperatureC": 9,
"Summary": "Balmy"
},
{
"Id": "07583c78-b2f5-4119-acdb-50511ac02e8a",
"Date": "2020-03-04T23:07:52.4085416-08:00",
"TemperatureC": -15,
"Summary": "Hot"
},
{
"Id": "05810360-d1fb-4f89-be18-2b8ddc75beff",
"Date": "2020-03-05T23:07:52.4085421-08:00",
"TemperatureC": 9,
"Summary": "Hot"
},
{
"Id": "35b23b1a-4803-4c3e-aebc-ced17807b1e1",
"Date": "2020-03-06T23:07:52.4085426-08:00",
"TemperatureC": 16,
"Summary": "Hot"
}
]
}You can now try the regular operations of $select, $orderby, $filter, $count and $top on your data and examine the functionality yourself.
Non-Edm Approach
If you decide to go the non-Edm route, you will need to install an additional Nuget package to resolve a Json formatting issue as follows:
First of all install Microsoft.AspNetCore.Mvc.NewtonsoftJson package by running the following PowerShell command:
Install-Package Microsoft.AspNetCore.Mvc.NewtonsoftJson -Version 3.1.2
You can also navigate for the package using Nuget Package manager as we did above.
Secondly, you will need to modify your ConfigureService in your Startup.cs file to enable the Json formatting extension method as follows:
using System.Linq;
using Microsoft.AspNet.OData.Extensions;
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Hosting;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
namespace WeatherAPI
{
public class Startup
{
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers().AddNewtonsoftJson();
services.AddOData();
}
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseHttpsRedirection();
app.UseRouting();
app.UseAuthorization();
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
endpoints.EnableDependencyInjection();
endpoints.Select().Filter().OrderBy().Count().MaxTop(10);
});
}
}
}Notice that we added AddNewtonsoftJson() to resolve the formatting issue with $select, we have also removed the MapODataRoute(..) and added EnableDependencyInjection() instead.
With that, we have added back the weather forecast controller [ApiController] and [Route] annotations in addition to [HttpGet] as follows:
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AspNet.OData;
using Microsoft.AspNetCore.Mvc;
namespace WeatherAPI.Controllers
{
[ApiController]
[Route("api/[controller]")]
public class WeatherForecastController : ControllerBase
{
private static readonly string[] Summaries = new[]
{
"Freezing", "Bracing", "Chilly", "Cool", "Mild", "Warm", "Balmy", "Hot", "Sweltering", "Scorching"
};
[HttpGet]
[EnableQuery]
public IEnumerable<WeatherForecast> Get()
{
var rng = new Random();
return Enumerable.Range(1, 5).Select(index => new WeatherForecast
{
Id = Guid.NewGuid(),
Date = DateTime.Now.AddDays(index),
TemperatureC = rng.Next(-20, 55),
Summary = Summaries[rng.Next(Summaries.Length)]
})
.ToArray();
}
}
}
Now, run your API and try all the capabilities of OData with your ASP.NET Core 3.1 API including Endpoint Routing.
Final Notes
- The OData team will continue to address all the issues opened on the public github repo based on their priority.
- We are always open to feedback from the community, and we hope to get the community’s support on some of our public repos to keep OData and it’s client libraries running.
- With this current implementation of OData you can now enable Swagger easily on your API without any issues.
- You can clone the example we used in this article from this repo here to try it for yourself.
- The final release of OData 7.4.0 library should be released within two weeks from the time this article was published.
The post Enabling Endpoint Routing in OData appeared first on OData.
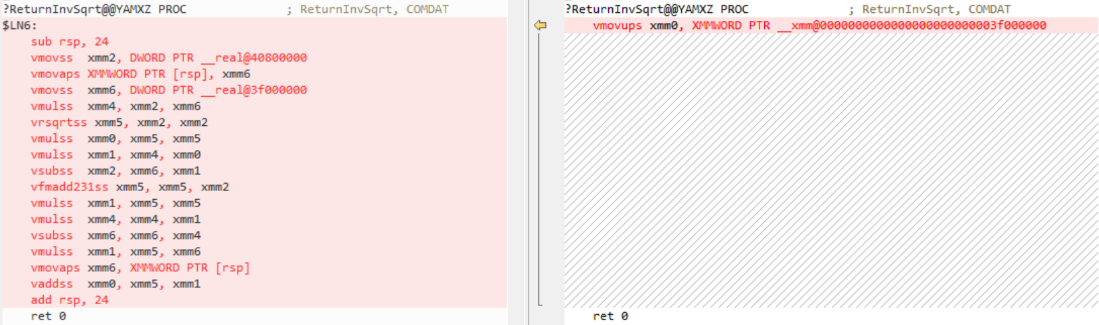
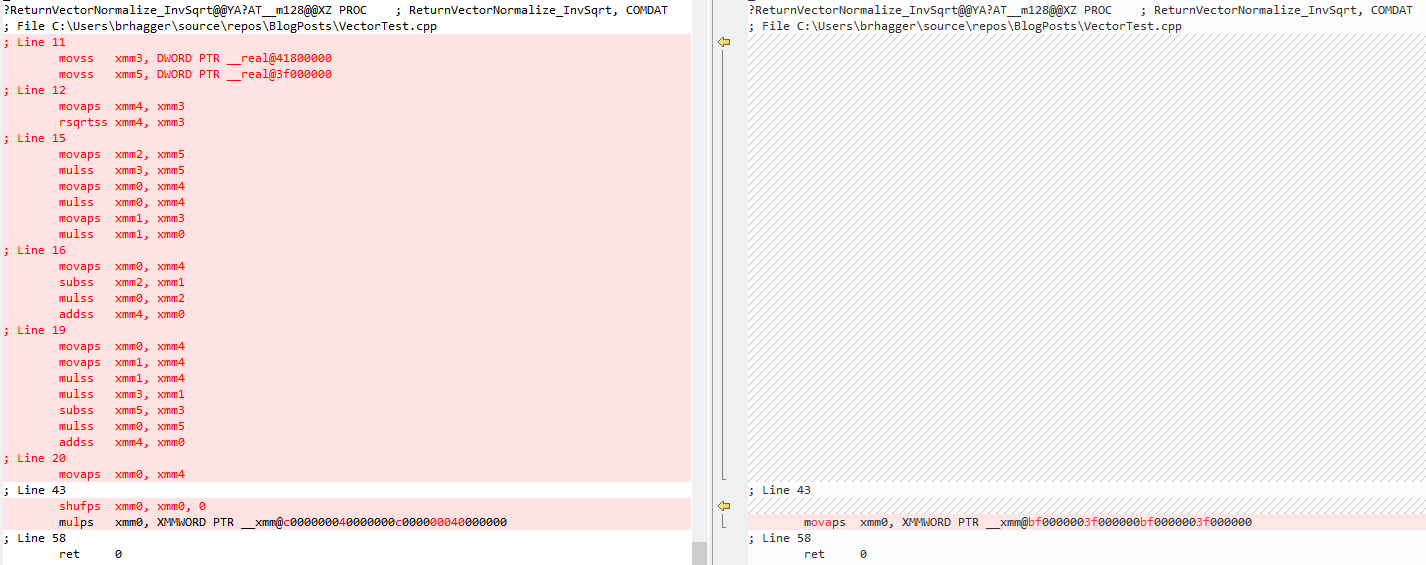





































 A few months back I
A few months back I 



