The subscription service for your life to make the most of your time, connect, and protect the ones you love.
The post Introducing the new Microsoft 365 Personal and Family subscriptions appeared first on Microsoft 365 Blog.
The subscription service for your life to make the most of your time, connect, and protect the ones you love.
The post Introducing the new Microsoft 365 Personal and Family subscriptions appeared first on Microsoft 365 Blog.
We heard your feedback that it can be difficult to configure debugging sessions on remote Linux systems or the Windows Subsystem for Linux (WSL). In Visual Studio 2019 version 16.6 Preview 2 we introduced a new debugging template to simplify debugging with gdb.
cppdbg) will continue to work as expected.
cppgdbwill be used by default whenever you add a new Linux or WSL debug configuration.
We heard your feedback that the old debug configurations were too verbose, too confusing, and not well documented. The new
cppgdbconfiguration has been simplified and looks like this:
{
"type": "cppgdb",
"name": "My custom debug configuration",
"project": "CMakeLists.txt",
"projectTarget": "DemoApp.exe",
"comment": "Learn how to configure remote debugging. See here for more info http://aka.ms/vslinuxdebug",
"debuggerConfiguration": "gdb",
"args": [],
"env": {}
}The new setting debuggerConfiguration indicates which set of debugging default values to use. In Visual Studio 2019 version 16.6 the only valid option is gdb.
There are more optional settings that can be added and configured for your debugging scenario like gdbPath (path to gdb), cwd (path to the working directory where the program is run), and preDebugCommand (a new setting that allows a Linux command to run before starting the debugger). A full list of these settings and their default values are listed in our documentation.
In Visual Studio 2019 version 16.5 or later you can manually configure launch.vs.json to debug CMake projects with gdbserver. In an upcoming release of Visual Studio we will be adding first-class support for gdbserver to the new
cppgdbtemplate. This will allow you to select gdbserver via the debuggerConfiguration setting and easily customize things like the path to gdbserver or the local path to gdb.
There are a few frequently asked questions we receive about debugging on Linux and WSL. A selection of these are called out and answered with examples below.
How do I pass arguments to the program being debugged?
Command-line arguments passed on startup to the program being debugged are configured with the args array. Example:
"args": ["arg1", "arg2"],
How do I set environment variables? Do I need to re-set the environment variables I set in CMakeSettings.json?
In Visual Studio 2019 version 16.5 or later debug targets are automatically launched with the environment specified in CMakeSettings.json. You can reference an environment variable defined in CMakeSettings.json (e.g. for path construction) with the syntax “${env.VARIABLE_NAME}”. You can also unset a variable defined in CMakeSettings.json by setting it to null.
The following example passes a new environment variable (DISPLAY) to the program being debugged and unsets an environment variable (DEBUG_LOGGING_LEVEL) that is specified in CMakeSettings.json.
"env": {
"DISPLAY": "1.0",
"DEBUG_LOGGING_LEVEL": null
},Note: Old Linux/WSL configurations of type cppdbg depend on the “environment” syntax. This alternative syntax is defined in our documentation.
I want to separate the system I am building on from the system I am debugging on. How do I do this?
Your build system (either a WSL installation or a remote system) is defined in CMakeSettings.json. Your remote debug system is defined by the key remoteMachineName in launch.vs.json.
By default, the value of remoteMachineName in launch.vs.json is synchronized with your build system. This setting only needs to be changed when specifying a new debug system. The easiest way to change the value of remoteMachineName in launch.vs.json is to use IntelliSense (ctrl + space) to view a list of all established remote connections.
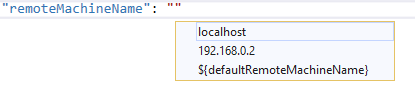
There are several other (optional) deployment settings that can be used to configure the separation of build and debug listed in our documentation.
I want to interact directly with the underlying debugger. Can I do this?
Visual Studio allows you to execute custom gdb commands via the Command Window. To do so,
I’m debugging with gdb or gdbserver and something isn’t working. How can I troubleshoot?
You can enable logging to see what commands we are sending to gdb, what output gdb is returning, and how long each command took.
Options:
Download Visual Studio 2019 version 16.6 Preview 2 today and give it a try. We’d love to hear from you to help us prioritize and build the right features for you. We can be reached via the comments below, Developer Community, email (visualcpp@microsoft.com), and Twitter (@VisualC and @erikasweet_). The best way to file a bug or suggest a feature is via Developer Community.
The post New templates for debugging CMake projects on remote systems and WSL in Visual Studio 2019 appeared first on C++ Team Blog.
The post Security, compliance, and privacy in Microsoft Teams appeared first on Microsoft 365 Blog.
I wanted to describe what I do to diagnose memory perf issues, or rather the common part of various work flows of doing such diagnostics. Diagnosing performance issues can take many forms because there’s no fixed steps you follow. But I’ll try to break it down into basic blocks that get invoked for a variety of diagnostics.
This part is for beginners so if you've been doing memory perf analysis for a while you can safely skip it.
First and foremost, before we talk about the actual diagnostics part, it really pays to know a few high level things that can point you at the right directions.
1) Point-in-time vs histogram
Understanding that memory issues are often not point-in-time is very important. Memory issues usually don’t just suddenly come into the picture – it might take a while for one to accumulate to the point that’s noticeable.
Let’s take a simple example, for a very simple non generational GC that only does blocking GCs that compact, this is still the case. If you are freshly out of a GC, of course the heap is at its smallest point. If you happen to measure at that point, you’ll think “great; my heap is small”. But if you happen to measure right before the next GC, the heap might be much bigger and you will have a different perception. And this is just for a simple GC, imagine what happens what you have a generational GC, or a concurrent GC.
This is why it’s extremely important to understand the GC history to see how GC made the decisions and how the decisions led to the current situation.
Unfortunately many memory tools, or many diagnostics approaches, do not take this into consideration. The way they do memory diagnostics is “let me show you what the heap looks like at the point you happened to ask”. This is often not helpful and sometimes to the point that it’s completely misleading and wasting people’s time to chase a problem that doesn’t exist or have a totally wrong approach how to make progress on the problem. This is not to say tools like these are not helpful at all – they can be helpful when the problem is simple. If you have a dramatic memory leak that’s been going on for a while and you used a tool that shows you the heap at that point (either by taking a process dump and using sos, or by another tool that dumps the heap) it’s probably really obvious what the leak is.
2) Generational GC
By design generational GCs don’t collect the whole heap every time a GC is triggered. They try to do young gen GCs much more often than old gen ones. Old gen GCs are often much more costly. With concurrent old gen GCs, the STW pauses may not be long but GC still needs to spend CPU cycles to do its job.
This also makes looking at the heap much more complicated because if you are fresh out of a gen2 GC, especially a compacting gen2, you obviously have a potentially way smaller heap size than if you were right before a compacting gen2 is triggered.
3) Compacting vs sweeping
Sweeping is not supposed to change the heap size by much. In our implementation we still give up the space at the end of segments so the total heap size can become a bit smaller but as high level you can think of the total heap size as not changing but free spaces get built up in order to accommodate the allocations from a younger gen (or in gen0/LOH case user allocations).
So if you see 2 gen2 GCs, one is compacting and the other is sweeping, it’s expected if the compacting one comes out with a much smaller heap size and the other one with high fragmentation (by design as that’s the free list we built up).
4) Allocation and survival
While many memory tools report allocations, it’s not just allocations that cost. Sure, allocations can trigger GCs, and that’s definitely a cost but when GC is working, the cost is mostly dominated by survivals. Of course you cannot be in a situation that both your allocation rate and survival rate are very high – you’d just run out of memory very quickly.
5) “Mainline GC scenario” vs “not mainline”
If you had a program that just used the stack and created some objects to use, GC has been optimizing that for years and years. Basically “scan stacks to get the roots and handle the objects from there”. This is the mainline GC scenario that many GC papers assume as the only scenario. Of course as a commercial product that has existed for decades and having to accommodate various customer requests, we have a bunch of other things like GC handles and finalizers. The important thing to understand there is while over the years we also optimized for those, we operate based on assumptions that “there aren’t too many of those” which obviously is not true for everyone. So if you do have many of those, it’s worth looking at if you are diagnosing a memory problem. In other words, if you don’t have any memory problem, you don’t need to care; but if you do (eg, high % time in GC), they are good things to suspect.
All this info is expressed in ETW events or the equivalent on Linux – this is why for years we’ve been investing in them and the tooling for analyzing the traces.
Traces to capture to start with
I often ask for 2 traces to start with. The 1st one is to get the accurate GC timing:
perfview /GCCollectOnly /nogui collect
after you are done, press s in the perfview cmd window to stop it
This should be run long enough to capture enough GC activities, eg, if you know problems occur at times, this should cover time that leads up to when problems happen (not only during problematic time).
If you know how long to run it for you can do (this is used much more often actually) –
perfview /GCCollectOnly /nogui /MaxCollectSec:1800 collect
replace 1800 (half an hour) with however many seconds you need.
This collects the informational level of GC events and just enough OS events to decode the process names. This command is very lightweight so it can be on all the time.
Notice I have the /nogui in all the PerfView commandlines I give out. PerfView does have a UI for event collection that allows you to select the events you want to capture. Personally I never use it (after I used it a couple of times when I first started to use PerfView). Some of it is just because I’m much more a commandline person; the other (important) part is because commandlines allow for much more flexibility and are a lot more automation friendly.
After you collect the trace you can open it in PerfView and look at the GCStats view. Some folks tend to just send it to me after they are done collecting but I would really encourage everyone who needs to do memory diagnostics on a regular basis to learn to read this view 'cause it's very useful. It gives us a wealth of information, even though the trace so lightweight. And if this doesn’t get us to the root cause, it definitely points at the direction we should take to make more progress. I described some of this view in this blog entry and its sequels that are linked in the entry. So I’m not going to show more pictures here. You could easily open that view and see for yourself.
Examples of the type of issues that can be easily spotted with this view –
Those are just things you can see at a glance. If you dig a little deeper there are many more things. And we’ll talk about them next time.
The post Work flow of diagnosing memory performance issues – Part 0 appeared first on .NET Blog.
From agriculture to healthcare, IoT unlocks opportunity across every industry, delivering profound returns, such as increased productivity and efficiency, reduced costs, and even new business models. And with a projected 41.6 billion IoT connected devices by 2025, momentum continues to build.
While IoT creates new opportunities, it also brings new cybersecurity challenges that could potentially result in stolen IP, loss of brand trust, downtime, and privacy breaches. In fact, 97 percent of enterprises rightfully call out security as a key concern when adopting IoT. But when organizations have a reliable foundation of security on which they can build from the start, they can realize durable innovation for their business versus having to figure out what IoT device security requires and how to achieve it.
Read on to learn how you can use Azure Sphere—now generally available—to create and accelerate secure IoT solutions for both new devices and existing equipment. As you look to transform your business, discover why IoT security is so important to build in from the start and see how the integration of Azure Sphere has enabled other companies to focus on innovation. For a more in-depth discussion, be sure to watch the Azure Sphere general availability webinar.

It’s important to understand on a high level how Azure Sphere delivers quick and cost-effective device security. Azure Sphere is designed around the seven properties of highly secure devices and builds on decades of Microsoft experience in delivering secure solutions. End-to-end security is baked into the core, spanning the hardware, operating system, and cloud, with ongoing service updates to keep everything current.
While other IoT device platforms must rely on costly manual practices to mitigate missing security properties and protect devices from evolving cybersecurity threats, Azure Sphere delivers defense-in-depth to guard against and respond to threats. Add in ongoing security and OS updates to help ensure security over time, and you have the tools you need to stay on top of the shifting digital landscape.
Azure Sphere removes the complexity of securing IoT devices and provides a secure foundation to build on. This means that IoT adopters spend less time and money focused on security and more time innovating solutions that solve key business problems, delivering a greater return on investment as well as faster time to market.
A great example is Starbucks, who partnered with Microsoft to connect its fleet of coffee machines using the guardian module with Azure Sphere. The guardian module helps businesses quickly securely connect existing equipment without any redesign, saving both time and money.
With IoT-enabled coffee machines, Starbucks collects more than a dozen data points such as type of beans, temperature, and water quality for every shot of espresso. They are also able to perform proactive maintenance on the machines to avoid costly breakdowns and service calls. Finally, they are using the solution to transmit new recipes directly to the machines, eliminating manual processes and reducing costs.
Here at Microsoft, Azure Sphere is also being used by the cloud operations team in their own datacenters. With the aim of providing safe, fast and reliable cloud infrastructure to everyone, everywhere, it was an engineer’s discovery of Azure Sphere that started to make their goal of connecting the critical environment systems—the walls, the roof, the electrical system, and mechanical systems that house the datacenters—a reality.
Using the guardian module with Azure Sphere, they were able to move to a predictive maintenance model and better prevent issues from impacting servers and customers. Ultimately it is allowing them to deliver better outcomes for customers and utilize the datacenter more efficiently. And even better, Azure Sphere is giving them the freedom to innovate, create and explore—all on a secure, cost-effective platform.
Throughout it all, enabling this innovation, is our global ecosystem of Microsoft partners that enable us to advance capabilities and bring Azure Sphere to a broad range of customers and applications.
Together, we can provide a more extensive range of options for businesses—from the single chip Wi-Fi solution from MediaTek that meets more traditional needs to other upcoming solutions from NXP and Qualcomm. NXP will provide an Azure Sphere certified chip that is optimized for performance power, and Qualcomm will offer the first cellular-native Azure Sphere chip.
Register for the Azure Sphere general availability webinar to explore how Azure Sphere works, how businesses are benefiting from it, and how you can use Azure Sphere to create secure, trustworthy IoT devices that enable true business transformation.
At Microsoft, privacy and security are never an afterthought. Here’s how we’re working to earn your trust every day with Microsoft Teams.
The post Our commitment to privacy and security in Microsoft Teams appeared first on Microsoft 365 Blog.
Privacy and security are always top of mind for IT, and today we’d like to outline our approach to privacy and security in Microsoft Teams.
The post For IT professionals: Privacy and security in Microsoft Teams appeared first on Microsoft 365 Blog.
Along with the Announcing .NET 5 preview 1, it’s time to move OData to .NET 5. This blog is intended to describe how easy to move the BookStore sample introduced in ASP.NET Core OData now Available onto .NET 5.
Let’s get started.
.NET 5 SDK is required to build the .NET 5 application. So, Let’s follow up the instructions in Announcing .NET 5 preview 1 to install the .NET 5 SDK.
Meanwhile, I also install the Visual Studio 2019 Preview to edit and compile the .NET 5 project. It’s easy to download Visual Studio 2019 Preview from here. The required VS version supporting .NET 5 is 16.6.
It’s easy to target the BookStore project to .NET 5 when we finish the installation of .NET 5.
Just open the BookStore solution, double click the project, then edit the “BookStore.csproj” contents as below:
In order to compile the project, we have to change some codes in the Startup.cs.
First, in ConfigureServices() method, change its content as below:
Then, in Configure() method, change its content as below:
Be noted, the parameter ‘IHostingEnvironment’ of Configure() should change to use “IWebHostEnvironment’.
That’s all. Now, we can build and run the book store application.
For example:
We can file a GET request as : http://localhost:5001/odata/Books(2)
And the response returns the second book as follows:
The application also supports the advanced OData query options like:
http://localhost:5001/odata/Books?$filter=Price le 50&$expand=Press($select=Name)&$select=ISBN,Location($select=Street)
The response payload should look like:
Thanks for reading. We encourage you to download the latest ASP.NET Core OData package from Nuget.org and start building amazing OData service running on any .NET 5 platforms, such as Windows, MacOS and Linux. Enjoy it!
You can refer to here for the sample project created in this blog. Any questions or concerns, feel free email to saxu@microsoft.com
The post Move OData to .NET 5 appeared first on OData.
Incremental enrichment is a new feature of Azure Cognitive Search that brings a declarative approach to indexing your data. When incremental enrichment is turned on, document enrichment is performed at the least cost, even as your skills continue to evolve. Indexers in Azure Cognitive Search add documents to your search index from a data source. Indexers track updates to the documents in your data sources and update the index with the new or updated documents from the data source.
Incremental enrichment is a new feature that extends change tracking from document changes in the data source to all aspects of the enrichment pipeline. With incremental enrichment, the indexer will drive your documents to eventual consistency with your data source, the current version of your skillset, and the indexer.
Indexers have a few key characteristics:
In the past, editing your skillset by adding, deleting, or updating skills left you with a sub-optimal choice. Either rerun all the skills on the entire corpus, essentially a reset on your indexer, or tolerate version drift where documents in your index are enriched with different versions of your skillset.
With the latest update to the preview release of the API, the indexer state management is being expanded from only the data source and indexer field mappings to also include the skillset, output field mappings knowledge store, and projections.
Incremental enrichment vastly improves the efficiency of your enrichment pipeline. It eliminates the choice of accepting the potentially large cost of re-enriching the entire corpus of documents when a skill is added or updated, or dealing with the version drift where documents created/updated with different versions of the skillset and are very different in shape and/or quality of enrichments.
Indexers now track and respond to changes across your enrichment pipeline by determining which skills have changed and selectively execute only the updated skills and any downstream or dependent skills when invoked. By configuring incremental enrichment, you will be able to ensure that all documents in your index are always processed with the most current version of your enrichment pipeline, all while performing the least amount of work required. Incremental enrichment also gives you the granular controls to deal with scenarios where you want full control over determining how a change is handled.

Incremental indexing is made possible with the addition of an indexer cache to the enrichment pipeline. The indexer caches the results from each skill for every document. When a data source needs to be re-indexed due to a skillset update (new or updated skill), each of the previously enriched documents is read from the cache and only the affected skills, changed and downstream of the changes are re-run. The updated results are written to the cache, the document is updated in the index and optionally, the knowledge store. Physically, the cache is a storage account. All indexes within a search service may share the same storage account for the indexer cache. Each indexer is assigned a unique cache id that is immutable.
Incremental enrichment provides a host of granular controls from ensuring the indexer is performing the highest priority task first to overriding the change detection.
To ensure that that the indexer only performs enrichments you explicitly require, updates to the skillset can optionally set disableCacheReprocessingChangeDetection query string parameter to true. When set, this parameter will ensure that only updates to the skillset are committed and the change is not evaluated for effects on the existing corpus.
Introducing incremental enrichment will result in an update to some existing APIs.
Indexers will now expose a new property:
Cache
StorageAccountConnectionString: The connection string to the storage account that will be used to cache the intermediate results.CacheId: The cacheId is the identifier of the container within the annotationCache storage account that is used as the cache for this indexer. This cache is unique to this indexer and if the indexer is deleted and recreated with the same name, the cacheid will be regenerated. The cacheId cannot be set, it is always generated by the service.EnableReprocessing: Set to true by default, when set to false, documents will continue to be written to the cache, but no existing documents will be reprocessed based on the cache data.Indexers will also support a new querystring parameter:
ignoreResetRequirement set to true allows the commit to go through, without triggering a reset condition.
Skillsets will not support any new operations, but will support new querystring parameter:
disableCacheReprocessingChangeDetection set to true when you want no updates to on existing documents based on the current action.
Datasources will not support any new operations, but will support new querystring parameter:
ignoreResetRequirement set to true allows the commit to go through without triggering a reset condition.
The recommended approach to using incremental enrichment is to configure the cache property on a new indexer or reset an existing indexer and set the cache property. Use the ignoreResetRequirement sparingly as it could lead to unintended inconsistency in your data that will not be detected easily.
Incremental enrichment is a powerful feature that allows you to declaratively ensure that your data from the datasource is always consistent with the data in your search index or knowledge store. As your skills, skillsets, or enrichments evolve the enrichment pipeline will ensure the least possible work is performed to drive your documents to eventual consistency.
Get started with incremental enrichment by adding a cache to an existing indexer or add the cache when defining a new indexer.
The COVID-19 outbreak is the challenge of a lifetime for government officials, public health workers, and healthcare providers. Get a firsthand view of how COVID-19 is impacting healthcare organizations with Dr. Mike Myint.
The post Spotlight on an epidemiologist—care team coordination and patient engagement in times of crisis appeared first on Microsoft 365 Blog.
Azure Security Center's threat protection enables you to detect and prevent threats across a wide variety of services from Infrastructure as a Service (IaaS) layer to Platform as a Service (PaaS) resources in Azure, such as IoT, App Service, and on-premises virtual machines.
At Ignite 2019 we announced new threat protection capabilities to counter sophisticated threats on cloud platforms, including preview for threat protection for Azure Kubernetes Service (AKS) Support in Security Center and preview for vulnerability assessment for Azure Container Registry (ACR) images.
In this blog, we will describe a recent large-scale cryptocurrency mining attack against Kubernetes clusters that was recently discovered by Azure Security Center. This is one of the many examples Azure Security Center can help you protect your Kubernetes clusters from threats.
Crypto mining attacks in containerized environments aren’t new. In Azure Security Center, we regularly detect a wide range of mining activities that run inside containers. Usually, those activities are running inside vulnerable containers, such as web applications, with known vulnerabilities that are exploited.
Recently, Azure Security Center detected a new crypto mining campaign that targets specifically Kubernetes environments. What differs this attack from other crypto mining attacks is its scale: within only two hours a malicious container was deployed on tens of Kubernetes clusters.
The containers ran an image from a public repository: kannix/monero-miner. This image runs XMRig, a very popular open source Monero miner.
The telemetries showed that container was deployed by a Kubernetes Deployment named kube-control.
As can be shown in the Deployment configuration below, the Deployment, in this case, ensures that 10 replicas of the pod would run on each cluster:

In addition, the same actor that deployed the crypto mining containers also enumerated the cluster resources including Kubernetes secrets. This might lead to exposure of connection strings, passwords, and other secrets which might enable lateral movement.
The interesting part is that the identity in this activity is system:serviceaccount:kube-system:kubernetes-dashboard which is the dashboard’s service account.
This fact indicates that the malicious container was deployed by the Kubernetes dashboard. The resources enumeration was also initiated by the dashboard’s service account.
There are three options for how an attacker can take advantage of the Kubernetes dashboard:
The question is which one of the three options above was involved in this attack? To answer this question, we can use a hint that Azure Security Center gives, security alerts on the exposure of the Kubernetes dashboard. Azure Security Center alerts when the Kubernetes dashboard is exposed to the Internet. The fact that this security alert was triggered on some of the attacked clusters implies that the access vector here is an exposed dashboard to the Internet.
A representation of this attack on the Kubernetes attack matrix would look like:

How could this be avoided?
Kubernetes is quickly becoming the new standard for deploying and managing software in the cloud. Few people have extensive experience with Kubernetes and many only focuses on general engineering and administration and overlook the security aspect. Kubernetes environment needs to be configured carefully to be secure, making sure no container focused attack surface doors are not left open is exposed for attackers. Azure Security Center provides:
To learn more about AKS Support in Azure Security Center, please visit the documentation here.
Azure Monitor’s new source map support expands a growing list of tools that empower developers to observe, diagnose, and debug their JavaScript applications.
As organizations rapidly adopt modern JavaScript frontend frameworks such as React, Angular, and Vue, they are left with an observability challenge. Developers frequently minify/uglify/bundle their JavaScript application upon deployment to make their pages more performant and lightweight which obfuscates the telemetry collected from uncaught errors and makes those errors difficult to discern.
Source maps help solve this challenge. However, it’s difficult to associate the captured stack trace with the correct source map. Add in the need to support multiple versions of a page, A/B testing, and safe-deploy flighting, and it’s nearly impossible to quickly troubleshoot and fix production errors.
Azure Monitor’s new source map integration enables users to link an Azure Monitor Application Insights Resource to an Azure Blob Services Container and unminify their call stacks from the Azure Portal with a single click. Configure continuous integration and continuous delivery (CI/CD) pipelines to automatically upload your source maps to Blob storage for a seamless end-to-end experience.

The Microsoft Cloud App Security (MCAS) Team at Microsoft manages a highly scalable service with a React JavaScript frontend and uses Azure Monitor Application Insights for clientside observability.
Over the last five years, they’ve grown in their agility to deploying multiple versions per day. Each deployment results in hundreds of source map files, which are automatically uploaded to Azure Blob container folders according to version and type and stored for 30 days.
Daniel Goltz, Senior Software Engineering Manager, on the MCAS Team explains, “The Source Map Integration is a game-changer for our team. Before it was very hard and sometimes impossible to debug and resolve JavaScript based on the unminified stack trace of exceptions. Now with the integration enabled, we are able to track errors to the exact line that faulted and fix the bug within minutes.”
Here’s an example scenario from a demo application:
Configure source map support once, and all users of the Application Insights Resource benefit. Here are three steps to get started:
Note: Add an Azure File Copy task to your Azure DevOps Build pipeline to upload source map files to Blob each time a new version of your application deploys to ensure relevant source map files are available.

If source map storage is not yet configured or if your source map file is missing from the configured Azure Blob storage container, it’s still possible to manually drag and drop a source map file onto the call stack in the Azure Portal.

Finally, this feature is only possible because our Azure Monitor community spoke out on GitHub. Please keep talking, and we’ll keep listening. Join the conversation by entering an idea on UserVoice, creating a new issue on GitHub, asking a question on StackOverflow, or posting a comment below.
The global health pandemic has impacted every organization on the planet—no matter the size—their employees, and the customers they serve. The emphasis on social distancing and shelter in place orders have disrupted virtually every industry and form of business. The Media & Entertainment (M&E) industry is no exception. Most physical productions have been shut down for the foreseeable future. Remote access to post-production tools and content is theoretically possible, but in practice is fraught with numerous issues, given the historically evolved, fragmented nature of the available toolsets, vendor landscape, and the overall structure of the business
At the same time, more so today than ever before, people are turning to stories, content, and information to connect us with each other. If you need help or assistance with general remote work and collaboration, please visit this blog.
If you’d like to learn more about best practices and solutions for M&E workloads, such as VFX, editorial, and other post-production workflows—which are more sensitive to network latency, require specialized high-performance hardware and software in custom pipelines, and where assets are mostly stored on-premises (sometimes in air-gapped environments)—read on.
First, leveraging existing on-premises hardware can be a quick solution to get your creative teams up and running. This works when you have devices inside the perimeter firewall, tied to specific hardware and network configurations that can be hard to replicate in the cloud. It also enables cloud as a next step rather than a first step, helping you fully leverage existing assets and only pay for cloud as you need it. Solutions such as Teradici Cloud Access Software running on your artists’ machines enables full utilization of desktop computing power, while your networking teams provide a secure tunnel to that machine. No data movement is necessary, and latency impacts between storage and machine are minimized, making this a simple, fast solution to get your creatives working again. For more information, read Teradici’s Work-From-Home Rapid Response Guide and specific guidance for standalone computers with Consumer Grade NVIDIA GPUs.
Customers who need to enable remote artists with cloud workstations, while maintaining data on-premises, can also try out an experimental way to use Avere vFXT for Azure caching policies to further reduce latency. This new approach optimizes creation, deletion, and listing of files on remote NFS shares often impacted by increased latency.
Second, several Azure partners have accelerated work already in progress to provide customers with new remote options, starting with editorial.
Third, while these solutions work well for small to medium projects, teams, and creative workflows, we know major studios, enterprise broadcasters, advertisers, and publishers have unique needs. If you are in this segment and need help enabling creative—or other Media and Entertainment specific workflows for remote work—please reach out to your Microsoft sales, support, or product group contacts so we can help
I know that we all want to get people in this industry back to work, while keeping everyone as healthy and safe as possible!
We’ll keep you updated as more guidance becomes available, but until then thank you for everything everyone is doing as we manage through an unprecedented time, together.
Italy has been one of the hardest-hit countries during the COVID-19 outbreak. These organizations have evolved rapidly to serve students, employees, and customers.
The post Learning from our customers in Italy appeared first on Microsoft 365 Blog.
We’re excited to announce, webmasters will have more tools than ever to control the snippets that preview their site on the Bing results page.
For a long time, the Bing search results page has shown site previews that include text snippets, image or video. These snippets, images or videos preview are to help users gauge if a site is relevant to what they’re looking to find out, or if there’s perhaps a more relevant search result for them to click on.
The webmasters owning these sites have had some control over these text snippets; for example, if they think the information they’re providing might be fragmented or confusing when condensed into a snippet, they may ask search engines to show no snippet at all so users click through to the site and see the information in its full context. Now, with these new features, webmasters will have more control than ever before to determine how their site is represented on the Bing search results page.
Letting Bing knows about your snippet and content preview preferences using robots meta tags.
We are extending our support for robots meta tags in HTML or X-Robots-Tag tag in the HTTP Header to let webmasters tell Bing about their content preview preferences.
Specify the maximum text-length, in characters, of a snippet in search results.
Example :<meta name="robots" content="max-snippet:400" />
<meta name="robots" content="max-image-preview:large" />
<meta name="robots" content="max-video-preview:-1" />
Please note that the NOSNIPPET meta tag is still supported and the options above can be combined with other meta robots tags.
Example by setting
<meta name="robots" content="max-snippet:-1, max-image-preview:large, max-video-preview:-1, noarchive" />
webmasters tell Bing that there is no snippet length limit, a large image preview may be shown, a long video preview may be shown and link to no cache page should be shown.
Over the following weeks, we will start rolling out these new options first for web and news, then for images, videos and our Bing answers results. We will use these options as directive statement, not as hints.
For more information, please read our documentation on meta tags.
Please reach out to Bing webmaster tools support if you face any issues or questions.
Fabrice Canel
Principal Program Manager
Microsoft - Bing
We want to say a big thank you to everyone who contributed to the docs in March of 2020! You are helping make the Visual Studio docs clearer, more complete, and more understandable for everyone. We love that our community takes the time to get involved and share their knowledge.
Here are the awesome folks who contributed pull requests to the docs in March:
In addition to contributing directly to the docs, some community members have left feedback in the form of GitHub issues on our visualstudio-docs repo. Thank you to all of you for the feedback, questions, and doc suggestions.
In March, docs GitHub issues were created by:
If you want to contribute your own content to the docs, just click the Edit button on a topic to start creating a pull request.

After we review and accept your changes, we’ll merge them into the official documentation.
To submit feedback on the docs, go to the bottom of the page and click to submit feedback about the page.

We greatly appreciate your participation in improving the docs! Keep it up. Let’s see who joins the fun in April. 
The post Thank you, Visual Studio docs contributors (March 2020) appeared first on Visual Studio Blog.
Working in a fully distributed, remote team requires sophisticated collaboration technology, which needs to be both supercharged and frictionless. Visual Studio Live Share was built on the bold principle of making remote developer collaboration as powerful and natural as in-person collaboration. We knew that our paradigm: “share your context, not your screen,” was only feasible, if we allowed the power of the modern IDE translate to remote collaboration sessions.
Just then the world changed drastically and everyone was forced to be remote. It wasn’t just professional developers who needed Live Share; there were students, teachers, and interview candidates who needed a real-time collaboration service. So the Live Share team continued to innovate, and further reduced friction by adding an option to join from the browser. This guide will highlight some of the key features of Live Share that help with remote work.
 In our customer development we found that the two most common things developers dislike about being remote are:
In our customer development we found that the two most common things developers dislike about being remote are:
With Live Share, we tackle both these problems, with an entire suite of your favorite IDE features remoted during the session, and in-built communication channels.
The following five tips will help you use Live Share —from your Visual Studio IDE— for your extended remote work, with all the bells and whistles attached.
The easiest way to start a Live Share session is by using the contacts that populate your Live Share viewlet. Once you share your code with someone, Live Share adds that user to your recent contacts list, enabling you to invite them to any future sessions without the hassle of links.
Tip: Live Share has two session types, which set several defaults for your ease of use. You can explicitly choose a read-only session for your guests.
Live Share has a brand-new feature where any guest to a Live Share session can join this session from the browser. This expands your scope of remote collaboration to even those who may not have the Visual Studio or Visual Studio Code installed on their machines. Joining from the browser provides guests of Live Share a fast, reliable and full-fidelity editor in the browser to collaborate with.

Tip: All Live Share sessions can be shared and joined from Visual Studio and Visual Studio Code. With the option to join from the browser, you now have another way to collaborate. The various options for using Live Share are especially useful while conducting technical interviews while remote.
Being a part of the distributed remote team for an extended period can cause communication fatigue. You can try and tackle this by keeping your communication channels context driven. So, for your productive development time, you can stay focused within your IDE even when collaborating. Live Share has built-in audio calling for your sessions. This not only keeps you away from other distractions while developing, it also enhances your collaboration experience when collaborating on features or debugging a tough bug.
Tip: Audio calling is an “insiders” feature in Visual Studio. To ensure you can use it during your Live Share session, make sure both you and your guest have insiders features enabled. Your guests using Visual Studio Code can use audio calling by downloading the Live Share extension pack from the marketplace.

Live Share empowers you to share your full context, not just your screen. This means you get both freedom and flexibility when working with a co-worker on a project. All the guests who join a Live Share session follow their host by default. This means, that they will be navigated to whichever line or file the host is editing. This is particularly helpful during the beginning of a pairing session, when all the collaborators are ramping up on what the host wants to share. After this point, if peers in a Live Share session wish to independently edit different parts of the project or file, they can break follow, by navigating to a different file or writing to a file.
Tip: If you want to draw the attention of your fellow collaborators to where you are in the code, you can click the focus button on the top of the Live Share viewlet. You can have just one of the guests follow you, or vice versa by clicking on their name in the participants list.
Often, the hardest thing about being remote is having to explain a problem which is occurring locally for you. With Live Share the host can not only share their code, but also launch their app during a debug session; guest can view this local app and interact with it. This is particularly useful for desktop and mobile apps.
Tip: You can do full fidelity co-debug sessions with your guests using Live Share. If you are developing a web app, Live Share will also forward your local port to your guests.

Live Share provides a way for users of Visual Studio and Visual Studio Code to collaboratively code, without the awkward fight for control over shared screens, or the in-flexibility of in-person collaboration. We’re all going to be remote for the near future, so let’s make sure our collaboration toolset is top notch.
Make sure you check the Live Share documentation for any other questions you may have about the product. You can also send an email to vsls-feedback@microsoft.com or fishah@microsoft.com for any feedback you may have about Live Share.
The post A guide to remote development with Live Share appeared first on Visual Studio Blog.
In Visual Studio 2019 version 16.5 we have continued to improve the C++ backend with new features, new and improved optimizations, build throughput improvements, and better security. Here is a brief list of improvements for you to review.
Do you want to experience the new improvements of the C++ backend? Please download the latest Visual Studio 2019 and give it a try! Any feedback is welcome. We can be reached via the comments below, Developer Community, email (visualcpp@microsoft.com), and Twitter (@VisualC).
The post MSVC Backend Updates in Visual Studio 2019 Version 16.5 appeared first on C++ Team Blog.
Our users tell us they frequently use a terminal for a variety of tasks – running front-end tasks (e.g. npm, ng, or vue), managing containers, running advanced git commands, scaffolding, automating builds , executing Entity Framework commands, viewing dotnet CLI output, adding NuGet packages, and more. Application switching can slow you down and cause you to lose focus. It’s no surprise that an integrated terminal is one of our top feature requests and we’re really happy to announce this feature is now in preview.
The new terminal is included in the latest preview version of Visual Studio for Mac 8.6. To use it, you’ll need to switch to the Preview channel. Once you’ve updated, you can launch the new terminal in one of several ways:
After you’ve opened it, you’ll see the terminal pad at the bottom of the Visual Studio for Mac window.
Now that you’ve got the terminal set up, let’s look at some of its features.
By default, when the terminal is launched it will:
To help filter through complex terminal output, developers need to be able to search the content of the terminal window. You can use the standard Search > Find… command for this. You’ll notice the Find UI is similar to the search experience in an editor window:
One really nice feature of the integrated terminal is that it utilizes your Mac system terminal. That means that your terminal customizations – zsh, oh-my-zsh, etc. – work the way you’re used to. If you’ve spent some time nerding out on a beautiful terminal, it’ll be right there for you when you open the Visual Studio for Mac Integrated Terminal. Not only that, but your command history works in sync between your system terminal and Visual Studio for Mac. When you open a new terminal pad in Visual Studio for Mac, hit the up arrow to see your previous commands from the system terminal.
Multiple instances of the terminal may be running at any time. You can manage the instances by:
You’ll notice a new font selector for Terminal Contents in the Preferences > Environment > Fonts pane. By default, the font will be the same as Output Pad Contents, using Menlo Regular, size 11. You can set it to any font, independent of your editor font.
The new integrated terminal is now available in Visual Studio 2019 for Mac 8.6 Preview. To start using it, make sure you’ve downloaded and installed Visual Studio 2019 for Mac, then switch to the Preview channel.
If you’re using Windows, Visual Studio has an experimental terminal as well, also in preview.
As always, if you have any feedback on this, or any, version of Visual Studio for Mac, we invite you to leave them in the comments below this post or to reach out to us on Twitter at @VisualStudioMac. If you run into issues while using Visual Studio for Mac, you can use Report a Problem to notify the team. In addition to product issues, we also welcome your feature suggestions on the Visual Studio Developer Community website.
We hope you enjoy using Visual Studio 2019 for Mac 8.6 Preview 1 as much as we enjoyed working on it!
The post Meet Visual Studio for Mac’s New Integrated Terminal! appeared first on Visual Studio Blog.





