Last week at Build, we announced general availability of Azure Dev Spaces. This add-on for Azure Kubernetes Service (AKS) enables your team to develop applications with cloud velocity. Run your service in a live AKS cluster and test it end-to-end, without affecting your teammates. Save maintenance time and money by allowing your entire dev team to share an AKS cluster, rather than requiring separate environments for each developer.
Azure Dev Spaces grew out of conversations that we had with companies that have large microservices-based cloud-native architectures. We learned that many of them built their own internal services that enable their developers to rapidly deploy new code to an isolated environment and test in the context of the entire application. These companies invested significant time and effort in building these capabilities. Azure Dev Spaces allows you to bring the same capabilities to your own team with just a few clicks.
In this post, we will show you how to get started with Azure Dev Spaces:
If you’re a team lead or devops, you’ll learn how to set up your team’s AKS cluster for use with Azure Dev Spaces.
If you’re a developer, you’ll learn how to run a service inside your team’s shared AKS cluster.
You’ll also learn how to troubleshoot a bug using the Dev Spaces extension for VS Code. (An extension for Visual Studio is also available.)
Setting up your AKS cluster
Let’s say that you are running all the services that make up your application in an AKS cluster that serves as your team’s integration testing environment.
You can enable Dev Spaces on the cluster from the Azure portal or the Azure CLI. The screen below shows where to enable Dev Spaces in the Azure portal.
Then, you can configure the namespace where the services are running as a dev space, which enables Dev Spaces functionality.
Now that you’ve set up the cluster and the application properly, let’s see how individual developers on your team can test their code in the context of the full application using Dev Spaces.
Running a service in AKS
Suppose that a new developer named Jane has joined your team. You have a new feature that you want her to create inside an existing microservice called Bikes.
Traditionally, Jane would write the code for the feature on her local development workstation and do some basic validation of the feature by running the Bikes service locally. Hopefully your team has already invested in some automated integration tests that she can run to further validate that she hasn’t broken anything. But since she’s new to the application and its codebase, she might not feel confident checking in her code until she’s seen it working properly in the context of the full application. Automated tests can’t catch everything, and no one wants to break the team’s dev environment, especially on their first day on the team!
This is where Azure Dev Spaces can make Jane’s first check-in experience easy and positive.
Jane can create a child dev space called newfeature. The parent of newfeature is the dev space you configured when you initially set up Dev Spaces for your team, which is running the entire application.
The version of the application that runs in the child dev space has its own URL. This is simply the URL to the team’s version of the application, prefixed with newfeature.s. Azure Dev Spaces intercepts requests that come in with this URL prefix and routes them appropriately. If there is a version of the service running in the newfeature dev space, then Dev Spaces routes the request to that version. Otherwise, Dev Spaces routes the request to the team’s version of the service, running in the root dev space.
End-to-End Testing
Jane can leverage this functionality to quickly test her changes end-to-end, even before she checks in her code. All she needs to do is run her updated version of the Bikes service in the newfeature dev space. Now she can access her version of the application by using the newfeature.s URL. Azure Dev Spaces will automatically handle routing requests between Jane’s updated version of Bikes (running in the newfeature dev space) and the rest of the services that make up the application (running in the parent dev space).
In the example shown below, the site currently shows a generic bicycle icon for each listed bicycle. One of Jane’s teammates has updated the database to include a picture of the actual bicycle. Jane needs to update the Bikes service to pull this picture from the database and send it along to the upstream services:
Troubleshooting a bug using Azure Dev Spaces
What if Jane discovers her changes didn’t work properly? First of all, her broken code is only running in her newfeature dev space. Her teammates’ requests still use the original version of Bikes running in the parent dev space. She can take her time troubleshooting the problem, knowing that she’s not blocking her teammates.
In addition, she can use the Azure Dev Spaces extensions for Visual Studio or Visual Studio Code to debug her code running live in the cloud with a single click. This allows her to quickly zero in on the problem, fix it, and validate her fix. She can even run and debug additional services inside the newfeature dev space, if the problem spans multiple services.
The following video shows debugging a Node.js service through VS Code, but the same capabilities are available for .NET Core and Java, inside Visual Studio or VS Code:
Once Jane has fully tested her new feature using Azure Dev Spaces, she can check in with confidence, knowing that she has validated her code end-to-end.
Ready to get started?
If you’re ready to increase developer productivity while saving maintenance time and money, check out the documentation to get started with Azure Dev Spaces. The team development quickstart walks you through setting up a realistic multi-service application and then debugging one service in an isolated dev space. You can learn how to set up a CI/CD pipeline to deploy your entire application to a Dev Spaces-enabled cluster so that your devs can easily test their individual services in the context of the entire application. And dive into the article on How Dev Spaces Works if you want to learn all about the magic behind Dev Spaces. (Spoiler alert: There’s not a lot of magic, just a lot of standard Kubernetes primitives!)
There’s seeing your build, and then there’s REALLY seeing your build. The difference can be quite dramatic, unveiling a new world of possibilities. As part of a partnership between IncrediBuild and Visual Studio, you can enjoy these possibilities directly within Visual Studio.
We previously discussed IncrediBuild, a software acceleration technology that speeds up your builds, tests, and other development process times. While IncrediBuild’s solution is known mainly for its impressive development acceleration capabilities, there’s another, very interesting capability to take note of: IncrediBuild’s Build Monitor tool. This elegant build visualization tool replaces your old text output with a sleek, intuitive graphic UI, transforming your build into a visual entity you can easily engage with, and helps you spot long durations, errors, warnings, bottlenecks, and dependencies.
Let’s take a look at the standard text output we’re all used to working with:
Now take a look at how a build looks like with IncrediBuild’s Build Monitor tool, seamlessly integrated into the Visual Studio experience (see additional information about invoking IncrediBuild’s Build Monitor from within Visual Studio at the bottom of the post):
Each color represents the build task status, allowing you to immediately identify which build tasks were executed without a problem and which require your attention. The bar width represents the duration of a specific task, and the side navigation bar lays out the specific machine and core on which the task was executed.
However, that’s not all there is to it. This tool also includes:
Customization capabilities – the build top graph is customizable, enabling you to keep track of relevant performance indicators such as CPU usage, tasks ready to be executed, memory usage, I/O, and much more.
Replay – You can replay your build process to examine how it performed and share it with team
Gaps detection – You can improve your build quality by quickly detecting tasks with long durations, errors, warnings, bottlenecks, unneeded dependencies, gaps, and more.
Display types – You can switch between display types:
Progress display – This is the colorful display discussed above
Output display – Allows you to see the entire build’s output text, similar to what would have been generated by Visual Studio. Double-clicking a task from the progress display will jump directly to the task’s textual output.
Projects display – Allows you to distinguish between each project’s/configuration’s standard output, along with a status bar representing the project’s build status.
Summary display -Presents an overview of all the build information, including the total build time.
IncrediBuild’s Build Monitor tool comes hand in hand with IncrediBuild’s main benefit: its ability to highly accelerate C++ builds by enabling you to use the idle CPU cycles of other machines in your network, effectively transforming each local machine or build server into a virtual super computer with dozens of cores. We’ve discussed IncrediBuild’s effect on build times while building on even a single development machine in a previous blog post. However, to realize IncrediBuild’s full potential, and take advantage of its entire acceleration capabilities, it is recommended to deploy it on more machines and cores. Simply connect your colleagues’ IncrediBuild Agents with yours and each of you will be able to seamlessly use the aggregated idle CPU power of all the machines connected together.
Visual Studio 2019 allows you to leverage these capabilities free of charge (for your local machine) and get a real speed boost on your software development.
How to install IncrediBuild from the Visual Studio Installer
Once you have downloaded the Visual Studio 2019 installer, IncrediBuild is presented as an optional component for C++ workloads.
After checking the IncrediBuild checkbox your Visual Studio installation will come with an Incredibuild submenu under the “Extensions” menu.
How to invoke the Build Monitor display (as well as IncrediBuild acceleration capabilities) from within Visual Studio 2019
After installing IncrediBuild within Visual Studio, you’ll have the Build Monitor display available to you upon initiating a build using IncrediBuild.
To initiate a build using IncrediBuild, just navigate to the ‘Extensions’ menu and choose one of the build options (Build Solution /Rebuild Solution/ Clean Solution). If you already initiated a build via IncrediBuild, and want to view the current build on the Build Monitor, simply navigate to the ‘View’ menu and choose ‘IncrediBuild Monitor’.
Talk To Us
We encourage you to download Visual Studio 2019 and try the IncrediBuild functionality. We can be reached via the comments below or via email (visualcpp@microsoft.com). If you encounter other problems with Visual Studio or have other suggestions you can use the Report a Problem tool in Visual Studio or head over to the Visual Studio Developer Community. You can also find us on Twitter (@VisualC).
For many years the ability to run UI tests in CI/CD has provided great value to web developers. This past Microsoft Build 2019 we were excited to announce desktop app developers can now also run UI tests in Azure DevOps! Desktop applications can now run automated UI tests in CI/CD on Azure DevOps using hosted or private agents, and setup is simple with a new Pipeline task.
Why UI tests in CI will help App Developers
Continuous Integration (CI) enables you to run automated tests of your application every time there’s a code change, and typically on servers so you’re not tying up desktop machines for testing. App developers have had the ability to run UI tests using WinAppDriver, and adding these tests to CI is important for a couple key reasons:
UI tests need interactive test machines. If you attempt to move the mouse, type on the keyboard, on a machine while a UI test is running, you will likely invalidate the test. This is because the tests perform automated user interactions in a way that does not differentiate from your physical actions.
CI is the right time to run UI Tests. There’s great value in having UI tests confirm if code changes break the user experience in your application. But equally important to having UI tests, is running them for every code change and pull request so you know exactly which commit broke the behavior. A key tenet of CI is to run every time the code changes.
How do UI tests work?
UI tests are automated tests designed to test an application by interacting with its UI in the same way a normal user would. These tests are different from unit/functional tests which test functional components of the application. A UI test typically involves going through an application in common scenarios just like a user would, verifying a user can accomplish common tasks. UI tests also typically record screenshots and often video of the test so the developer can review how the application appeared at various moments in the test.
What work was done to enable this?
For app developers to run UI tests in CI, the machine running the tests must be in an interactive state. This means the operating system has a logged in user and is listening for user input. You also need a test runner such as WinAppDriver on the test machine. Setting up a private agent in Azure DevOps with this configuration was possible, but it required significant manual configuration. Many customers requested enabling the hosted agent pool with a simple solution. The HostedVS2017 and HostedVS2019 agents are now updated with the following to enable UI tests in CI:
Support for interactive mode
Addition of WinAppDriver which executes the UI test commands
Both agents are included for free in the base Azure Pipelines plan.
In addition to the hosted agent additions there’s now a task in Azure Pipelines for easy addition of UI tests and added test configuration options. A preview of the WinAppDriver task is available today on the DevOps Marketplace. If you’re using the Classical Editor, search for “WinAppDriver” from the Add tasks menu:
For more information on the task, check out the updated CI with Azure Pipelines section on our Wiki.
Live Example: Microsoft Calculator
The recently open-sourced Microsoft Calculator project has UI Tests running in Azure DevOps as part of their CI. These tests are helping the Calculator Team catch PRs that break the user experience.
You can check out their DevOps CI/CD Pipeline fully integrated with the new WinAppDriver Task seen here:
Call to Action
Please take a look at Calculator and evaluate if adding UI tests in CI/CD will help your desktop application projects.
Customers across industries including healthcare, legal, media, and manufacturing are looking for new solutions to solve business challenges with AI, including knowledge mining with Azure Search.
Azure Search enables developers to quickly apply AI across their content to unlock untapped information. Custom or prebuilt cognitive skills like facial recognition, key phrase extraction, and sentiment analysis can be applied to content using the cognitive search capability to extract knowledge that’s then organized within a search index. Let’s take a closer look at how one company, Howden, applies the cognitive search capability to reduce time and risk to their business.
Howden, a global engineering company, focuses on providing quality solutions for air and gas handling. With over a century of engineering experience, Howden creates industrial products that help multiple sectors improve their everyday processes; from mine ventilation and waste water treatment to heating and cooling.
Too many details, not enough time
Every new project requires the creation of a bid proposal. A typical customer bid can span thousands of pages in differing formats such as Word and PDF. The team has to scour through detailed customer requirements to identify key areas of design and specialized components in order to produce accurate bids. If they miss key or critical details, they can bid too low and lose money, or bid too high and lose the customer opportunity. The manual process is time consuming, labor intensive, and creates multiple opportunities for human error. To learn more about knowledge mining with Azure Search and see how Howden built their solution, check out the Microsoft Mechanics show linked below.
For the May security release, we are releasing fixes for vulnerabilities that impact Azure DevOps Server 2019, TFS 2018, TFS 2017, and TFS 2015. Thanks to everyone who has been participating in our Azure DevOps Bounty Program.
We have now added the ability to patch TFS 2015, so customers do not need to install a full release to get the security fixes. As a reminder, all patches are cumulative, so they include all the fixes in previous patches.
CVE-2019-0872: cross site scripting (XSS) vulnerability in Test Plans
CVE-2019-0971: information disclosure vulnerability in the Repos API
CVE-2019-0979: cross site scripting (XSS) vulnerability in the User hub
To verify if you have this update installed, you can check the version of the following file: [INSTALL_DIR]Application TierWeb ServicesbinMicrosoft.TeamFoundation.Server.WebAccess.VersionControl.dll. Azure DevOps Server 2019 is installed to c:Program FilesAzure DevOps Server 2019 by default.
After installing Azure DevOps Server 2019 Patch 2, the version will be 17.143.28826.2.
To verify if you have this update installed, you can check the version of the following file: [TFS_INSTALL_DIR]Application TierWeb ServicesbinMicrosoft.TeamFoundation.WorkItemTracking.Web.dll. TFS 2018 is installed to c:Program FilesMicrosoft Team Foundation Server 2018 by default.
After installing TFS 2018 Update 3.2 Patch 4, the version will be 16.131.28826.3.
To verify if you have this update installed, you can check the version of the following file: [TFS_INSTALL_DIR]Application TierWeb ServicesbinMicrosoft.TeamFoundation.Server.WebAccess.Admin.dll. TFS 2018 is installed to c:Program FilesMicrosoft Team Foundation Server 2018 by default.
After installing TFS 2018 Update 1.2 Patch 4, the version will be 16.122.28826.4.
To verify if you have a patch installed, you can check the version of the following file: [TFS_INSTALL_DIR]Application TierWeb ServicesbinMicrosoft.TeamFoundation.Server.WebAccess.Admin.dll. TFS 2017 is installed to c:Program FilesMicrosoft Team Foundation Server 15.0 by default.
After installing TFS 2017 Update 3.1 Patch 5, the version will be 15.117.28826.0.
To verify if you have a patch installed, you can check the version of the following file: [TFS_INSTALL_DIR]Application TierWeb ServicesbinMicrosoft.TeamFoundation.Framework.Server.dll. TFS 2017 is installed to c:Program FilesMicrosoft Team Foundation Server 14.0 by default.
After installing TFS 2015 Update 4.2 Patch 1, the version will be 14.114.28829.0.
This post is to announce the availability of AzureKusto, the R interface to Azure Data Explorer (internally codenamed “Kusto”), a fast, fully managed data analytics service from Microsoft. It is available from CRAN, or you can install the development version from GitHub via devtools::install_github("cloudyr/AzureKusto").
AzureKusto provides an interface (including DBI compliant methods for connecting to Kusto clusters and submitting Kusto Query Language (KQL) statements, as well as a dbplyr style backend that translates dplyr queries into KQL statements. On the administrator side, it extends the AzureRMR framework to allow for creating clusters and managing database principals.
Connecting to a cluster
To connect to a Data Explorer cluster, call the kusto_database_endpoint() function. Once you are connected, call run_query() to execute queries and command statements.
library(AzureKusto)
## Connect to a Data Explorer cluster with (default) device code authenticationSamples <- kusto_database_endpoint( server="https://help.kusto.windows.net", database="Samples")
res <- run_query(Samples, "StormEvents | summarize EventCount = count() by State | order by State asc")
head(res)
## State EventCount## 1 ALABAMA 1315## 2 ALASKA 257## 3 AMERICAN SAMOA 16## 4 ARIZONA 340## 5 ARKANSAS 1028## 6 ATLANTIC NORTH 188# run_query can also handle command statements, which begin with a '.' characterres <- run_query(Samples, ".show tables | count")
res[[1]]
## Count## 1 5
dplyr Interface
The package also implements a dplyr-style interface for building a query upon a tbl_kusto object and then running it on the remote Kusto database and returning the result as a regular tibble object with collect(). All the standard verbs are supported.
library(dplyr)
StormEvents <- tbl_kusto(Samples, "StormEvents")
q <- StormEvents %>% group_by(State) %>% summarize(EventCount=n()) %>% arrange(State) show_query(q)
## <KQL> database('Samples').['StormEvents']## | summarize ['EventCount'] = count() by ['State']## | order by ['State'] asc collect(q)
## # A tibble: 67 x 2## State EventCount## <chr> <dbl>## 1 ALABAMA 1315## 2 ALASKA 257## 3 AMERICAN SAMOA 16## ...
DBI interface
AzureKusto implements a subset of the DBI specification for interfacing with databases in R.
It should be noted, though, that Data Explorer is quite different to the SQL databases that DBI targets. This affects the behaviour of certain DBI methods and renders other moot.
If you have any questions, comments or other feedback, please feel free to open an issue on the GitHub repo.
And one more thing...
As of Build 2019, Data Explorer can also run R (and Python) scripts in-database. For more information on this feature, currently in public preview, see the Azure blog and the documentation article.
The Quick Info tooltip has received a couple of improvements in Visual Studio 2019 version 16.1 Preview 3.
Quick Info Colorization
While Quick Info was previously all black text, the tooltip now respects the semantic colorization of your editor:
If you’d like to customize your semantic colorization, you can do that by searching “font” in the Visual Studio Search box (Ctrl + Q), or by navigating to Tools > Options > Environment > Fonts and Colors:
Quick Info Search Online
The Quick Info tooltip has a new “Search Online” link that will search for online docs to learn more about the hovered code construct. For red-squiggled code, the link provided by Quick Info will search for the error online. This way you don’t need to retype the message into your browser.
You can customize your Search Provider under Tools > Options > Text Editor > C++ > View.
Talk to Us!
If you have feedback on Quick Info in Visual Studio, we would love to hear from you. We can be reached via the comments below or via email (visualcpp@microsoft.com). If you encounter other problems with Visual Studio or MSVC or have a suggestion, you can use the Report a Problem tool in Visual Studio or head over to Visual Studio Developer Community. You can also find us on Twitter (@VisualC) and (@nickuhlenhuth).
Network security solutions can be delivered as appliances on premises, as network virtual appliances (NVAs) that run in the cloud or as a cloud native offering (known as firewall-as-a-service).
Customers often ask us how Azure Firewall is different from Network Virtual Appliances, whether it can coexist with these solutions, where it excels, what’s missing, and the TCO benefits expected. We answer these questions in this blog post.
Network virtual appliances (NVAs)
Third party networking offerings play a critical role in Azure, allowing you to use brands and solutions you already know, trust and have skills to manage. Most third-party networking offerings are delivered as NVAs today and provide a diverse set of capabilities such as firewalls, WAN optimizers, application delivery controllers, routers, load balancers, proxies, and more. These third party capabilities enable many hybrid solutions and are generally available through the Azure Marketplace. For best practices to consider before deploying a NVA, see Best practices to consider before deploying a network virtual appliance.
Cloud native network security
A cloud native network security service (known as firewall-as-a-service) is highly available by design. It auto scales with usage, and you pay as you use it. Support is included at some level, and it has a published and committed SLA. It fits into DevOps model for deployment and uses cloud native monitoring tools.
What is Azure Firewall?
Azure Firewall is a cloud native network security service. It offers fully stateful network and application level traffic filtering for VNet resources, with built-in high availability and cloud scalability delivered as a service. You can protect your VNets by filtering outbound, inbound, spoke-to-spoke, VPN, and ExpressRoute traffic. Connectivity policy enforcement is supported across multiple VNets and Azure subscriptions. You can use Azure Monitor to centrally log all events. You can archive the logs to a storage account, stream events to your Event Hub, or send them to Log Analytics or your security information and event management (SIEM) product of your choice.
Is Azure Firewall a good fit for your organization security architecture?
Organizations have diverse security needs. In certain cases, even the same organization may have different security requirements for different environments. As mentioned above, third party offerings play a critical role in Azure. Today, most next-generation firewalls are offered as Network Virtual Appliances (NVA) and they provide a richer next-generation firewall feature set which is a must-have for specific environments/organizations. In the future, we intend to enable chaining scenarios to allow you to use Azure Firewall for specific traffic types, with an option to send all or some traffic to a third party offering for further inspection. This third-party offering can be either a NVA or a cloud native solution.
Many Azure customers find the Azure Firewall feature set is a good fit and it provides some key advantages as a cloud native managed service:
DevOps integration – easily deployed using Azure Portal, Templates, PowerShell, CLI, or REST.
Built in HA with cloud scale.
Zero maintenance service model - no updates or upgrades.
Azure Firewall pricing includes a fixed hourly cost ($1.25/firewall/hour) and a variable per GB processed cost to support auto scaling. Based on our observation, most customers save 30 percent – 50 percent in comparison to an NVA deployment model. We are announcing a price reduction, effective May 1, 2019, for the firewall per GB cost to $0.016/GB (-46.6 percent) to ensure that high throughput customers maintain cost effectiveness. There is no change to the fixed hourly cost. For the most up-to-date pricing information, please go to the Azure Firewall pricing page.
The following table provides a conceptual TCO view for a NVA with full HA (active/active) deployment:
Cost
Azure Firewall
NVAs
Compute
$1.25/firewall/hour
$0.016/GB processed
(30%-50% cost saving)
Two plus VMs to meet peek requirements
Licensing
Per NVA vendor billing model
Standard Public Load Balancer
First five rules: $0.025/hour
Additional rules: $0.01/rule/hour
$0.005 per GB processed
Standard Internal Load Balancer
First five rules: $0.025/hour
Additional rules: $0.01/rule/hour
$0.005 per GB processed
At Microsoft Build 2019 we announced exciting new capabilities, including the introduction of real-time operational analytics using new built in support for Apache Spark and a new Jupyter notebook experience for all Azure Cosmos DB APIs. We believe these capabilities will help our customers easily build globally distributed apps at Cosmos scale.
Here are additional enhancements to the developer experience, announced at Microsoft Build:
Powering Kubernetes with etcd API
Etcd is at the heart of the Kubernetes cluster - it’s where all of the state is! We are happy to announce a preview for wire-protocol compatible etcd API to enable self-managed Kubernetes developers to focus more on their apps, rather than managing etcd clusters. With the wire-protocol compatible Azure Cosmos DB API for etcd, Kubernetes developers will automatically get highly scalable, globally distributed, and highly available Kubernetes clusters. This enables developers to scale Kubernetes coordination and state management data on a fully managed service with 99.999-percent high availability and elastic scalability backed by Azure Cosmos DB SLAs. This helps significantly lower total cost of ownership (TCO) and remove the hassle and complexity of managing etcd clusters.
The multi-model capabilities of Azure Cosmos DB’s database engine are foundational and bring important benefits to our customers, such as leveraging multiple data models in the same apps, streamlining development by focusing on the single service, reducing TCO by not having multiple database engines to manage, and getting the benefits of the comprehensive SLAs offered by Azure Cosmos DB.
Over the past two years, we have been steadily revamping our database engine’s type system and the storage encodings for both Azure Cosmos DB database log and index. The database engine’s type system is fully extensible and is now a complete superset of the native type systems of Apache Cassandra, MongoDB, Apache Gremlin, and SQL. The new encoding scheme for the database log is highly optimized for storage and parsing, and is capable of efficiently translating popular formats like Parquet, protobuf, JSON, BSON, and other encodings. The newly revamped index layout provides:
Significant performance boost to query execution cost, especially for the aggregate queries
New SQL query capabilities:
Support for OFFSET/LIMIT and DISTINCT keywords
Composite indexes for multi-column sorting
Correlated subqueries including EXISTS and ARRAY expressions
The type system and storage encodings have provided benefits to a plethora of Gremlin, MongoDB, and Cassandra (CQL) features. We are now near full compatibility with Cassandra CQL v4, and are bringing native change feed capabilities as an extension command in CQL. Customers can build efficient, event sourcing patterns on top of Cassandra tables in Azure Cosmos DB. We are also announcing several Gremlin API enhancements, including the support of Execution Profile function for performance evaluation and String comparison functions aligned with the Apache TinkerPop specification.
Added support for Azure Cosmos DB direct HTTPS and TCP transport protocols, increasing performance and availability
All new query improvements of V3 SDKs
Java V3 SDK is fully open-sourced, and we welcome your contributions. We will make Java V3 SDK generally available shortly.
Change feed processor for Java
One of the most popular features in Azure Cosmos DB, change feed allows customers to programmatically observe changes to their data in Cosmos containers. It is used in many application patterns, including reactive programming, analytics, event store, and serverless. We’re excited to announce change feed processor library for Java, allowing you to build distributed microservices architectures on top of change feed, and dynamically scale them using one of the most popular programming languages.
General availability of the cross-platform Table .NET Standard SDK
The 1.0.1 GA version of the cross-platform Table .NET Standard SDK has just come out. It is a single unified cross-platform SDK for both Azure Cosmos DB Table API and Azure Storage Table Service. Our customers can now operate against the Table service, either as a Cosmos Table, or Azure Storage Table using .NET Framework app on Windows, or .NET Core app on multiple platforms. We’ve improved the development experience by removing unnecessary binary dependencies while retaining the improvements when invoking Table API via the REST protocols, such as using modern HttpClient, DelegatingHandler based extensibility, and modern asynchronous patterns. It can also be used by the cross-platform Azure PowerShell to continue to power the Table API cmdlets.
More cosmic developer goodness
ARM support for databases, containers, and other resources in Azure Resource Manager
Azure Cosmos DB now provides support for Databases, Containers and Offers in Azure Resource Manager. Users can now provision databases and containers, and set throughput using Azure Resource Manager templates or PowerShell. This support is available across all APIs including SQL (Core), MongoDB, Cassandra, Gremlin, and Table. This capability also allows customers to create custom RBAC roles to create, delete, or modify the settings on databases and containers in Azure Cosmos DB. To learn more and to get started, see Azure Cosmos DB Azure Resource Manager templates.
Azure Cosmos DB custom roles and policies
Azure Cosmos DB provides support for custom roles and policies. Today, we announce the general availability of an Azure Cosmos DB Operator role. This role provides the ability to manage Azure Resource Manager resources for Azure Cosmos DB without providing data access. This role is intended for scenarios where customers need the ability to grant access to Azure Active Directory Service Principals to manage deployment operations for Azure Cosmos DB, including the account, databases, and containers. To learn more, visit our documentation on Azure Cosmos DB custom roles and policies support.
Upgrade single-region writes Cosmos accounts to multi-region writes
One of the most frequent customer asks has been the ability to upgrade existing Cosmos accounts configured with a single writable region (single-master) to multiple writable regions (multi-master). We are happy to announce that starting today, you will be able to make your existing accounts writable from all regions. You can do so using the Azure portal or Azure CLI. The upgrade is completely seamless and is performed without any downtime. To learn more about how to perform this upgrade, visit our documentation.
Automatic upgrade of fixed containers to unlimited containers
All existing fixed Azure Cosmos containers (collections, tables, graphs) in the Azure Cosmos DB service are now automatically upgraded to enjoy unlimited scale and storage. Please refer to this documentation for in depth overview of how to scale your existing fixed containers to unlimited containers.
Azure Cosmos Explorer now with Azure AD support
Enjoy a flexible Cosmos Explorer experience to work with data within the Azure portal, as part of the Azure Cosmos DB emulator and Azure Storage Explorer. We’ve also made it available “full-screen”, for when developers do not have access to the Azure portal or need a full screen experience. Today, we are adding support for Azure Active Directory to https://cosmos.azure.com, so that developers can authenticate directly with their Azure credentials, and take advantage of the full screen experience.
Azure portal and tools enhancements
To help customers correctly provision capacity for apps and optimize costs on Azure Cosmos DB, we have added built in cost recommendations to Azure portal and Azure Advisor, along with updates to the Azure pricing calculator.
We look forward to seeing what you will build with Azure Cosmos DB!
For the latest Azure Cosmos DB news and features, stay up-to-date by following us on Twitter #CosmosDB, @AzureCosmosDB.
Azure Cosmos DB
Azure Cosmos DB is Microsoft's globally distributed, multi-model database service for mission-critical workloads. Azure Cosmos DB provides turnkey global distribution with unlimited endpoint scalability, elastic scaling of throughput at multiple granularities (e.g., database/key-space as well as, tables/collections/graphs), storage worldwide, single-digit millisecond read and write latencies at the 99th percentile, five well-defined consistency models, and guaranteed high availability, all backed by the industry-leading comprehensive SLAs.
Today, we are releasing the May 2019 Cumulative Update, Security and Quality Rollup, and Security Only Update.
Security
CVE-2019-0820 – Denial of Service Vulnerability
A denial of service vulnerability exists when .NET Framework and .NET Core improperly process RegEx strings. An attacker who successfully exploited this vulnerability could cause a denial of service against a .NET application. A remote unauthenticated attacker could exploit this vulnerability by issuing specially crafted requests to a .NET Framework (or .NET core) application. The update addresses the vulnerability by correcting how .NET Framework and .NET Core applications handle RegEx string processing.
A denial of service vulnerability exists when .NET Framework or .NET Core improperly handle web requests. An attacker who successfully exploited this vulnerability could cause a denial of service against a .NET Framework or .NET Core web application. The vulnerability can be exploited remotely, without authentication. A remote unauthenticated attacker could exploit this vulnerability by issuing specially crafted requests to the .NET Framework or .NET Core application. The update addresses the vulnerability by correcting how .NET Framework or .NET Core web applications handles web requests.
A denial of service vulnerability exists when .NET Framework or .NET Core improperly handle web requests. An attacker who successfully exploited this vulnerability could cause a denial of service against a .NET Framework or .NET Core web application. The vulnerability can be exploited remotely, without authentication. A remote unauthenticated attacker could exploit this vulnerability by issuing specially crafted requests to the .NET Framework or .NET Core application. The update addresses the vulnerability by correcting how .NET Framework or .NET Core web applications handles web requests.
A denial of service vulnerability exists when .NET Framework improperly handles objects in heap memory. An attacker who successfully exploited this vulnerability could cause a denial of service against a .NET application. To exploit this vulnerability, an attacker would have to log on to an affected system and run a specially crafted application. The security update addresses the vulnerability by correcting how .NET Framework handle objects in heap memory.
The Cumulative Update and Security and Quality Rollup are available via Windows Update, Windows Server Update Services, Microsoft Update Catalog, and Docker. The Security Only Update is available via Windows Server Update Services and Microsoft Update Catalog.
Microsoft Update Catalog
You can get the update via the Microsoft Update Catalog. For Windows 10, NET Framework 4.8 updates are available via Windows Update, Windows Server Update Services, Microsoft Update Catalog. Updates for other versions of .NET Framework are part of the Windows 10 Monthly Cumulative Update.
The following table is for Windows 10 and Windows Server 2016+ versions.
Azure Pipelines, our hosted CI/CD solution, has been offering developers the ability to build and test applications using Microsoft-hosted macOS and Xcode agents, including apps for iOS and watchOS.
Earlier this year, we were excited to share with you that the Hosted macOS agents were going to be upgraded to OS X 10.14 (Mojave). At the time of that announcement we said that we were plannig to drop support for High Sierra and Xcode versions below 9.4.1. Having spoken with a number of teams about their customers adoption of the latest macOS updates, we have decided to keep the High Sierra image available and maintained. This not only helps teams who need older versions of Xcode for their builds, but it also allows you to build with the latest bits on Mojave and then run automated tests with High Sierra as well.
Picking the right macOS Version
Based on your build needs, you can choose to use High Sierra or Mojave build agents. If your build requires an Xcode version prior to 9.4.1, choose High Sierra. On the other hand, builds using Xcode 10.2 and higher will only build on Mojave agents. You can always see the full list of tools installed in each image in our GitHub repository. After identifying which macOS version is right for you, you can select the version via the classic UI editor or by specifying the image in your YAML file.
If you had previously selected Hosted macOS in the Agent Pool dropdown in the UI editor, your builds are already running on Mojave. To switch back to High Sierra or target High Sierra for new pipelines, select Hosted macOS High Sierra in the Agent Pool dropdown.
For pipelines using YAML, simply specify the macOS version using the snippets below:
jobs:
- job: macOS
pool:
vmImage: 'macOS-10.14'
steps:
- script: echo hello from macOS Mojave
- job: macOS
pool:
vmImage: 'macOS-10.13'
steps:
- script: echo hello from macOS High Sierra
- job: macOS
pool:
vmImage: 'macOS-latest'
steps:
- script: echo hello from the latest version of macOS available
For additional information on our Hosted Agents, please refer to our documentation.
Next Steps for Hosted macOS Agents
We are looking forward to announcements to come from Apple’s Worldwide Developers Conference in June. We will continue to provide support for the latest macOS and Xcode versions to enable you to develop great experiences targeted to Apple’s ecosystem, including macOS, iOS, and watchOS. In addition to keeping our macOS build agents up-to-date, we will continue to look into and update other tools that are added to the agents. Open up an issue in our GitHub repositoryfor any tools you would like to see added or any issues you run into.
Reach out to us @AzureDevOps, or directly to me @nilli_minaj, for any questions or feedback. Happy building!
Today, we are releasing the .NET Core May 2019 Update. These updates contain security and reliability fixes. See the individual release notes for details on updated packages.
NOTE: If you are a Visual Studio user, there are MSBuild version requirements so use only the .NET Core SDK supported for each Visual Studio version. Information needed to make this choice will be seen on the download page. If you use other development environments, we recommend using the latest SDK release.
Microsoft is releasing this security advisory to provide information about a vulnerability in .NET Core 1.0, 1.1, 2.1 and 2.2. This advisory also provides guidance on what developers can do to update their applications to remove this vulnerability.
A denial of service vulnerability exists when .NET Core improperly processes RegEx strings. An attacker who successfully exploited this vulnerability could cause a denial of service against a .NET application.
A remote unauthenticated attacker could exploit this vulnerability by issuing specially crafted requests to a .NET Core application.
The update addresses the vulnerability by correcting how .NET Core applications handle RegEx string processing.
Microsoft is releasing this security advisory to provide information about a vulnerability in .NET Core and ASP.NET Core 1.0, 1.1, 2.1 and 2.2. This advisory also provides guidance on what developers can do to update their applications to remove this vulnerability.
A denial of service vulnerability exists when .NET Core and ASP.NET Core improperly handle web requests. An attacker who successfully exploited this vulnerability could cause a denial of service against a .NET Core and ASP.NET Core application. The vulnerability can be exploited remotely, without authentication.
A remote unauthenticated attacker could exploit this vulnerability by issuing specially crafted requests to a .NET Core application.
The update addresses the vulnerability by correcting how .NET Core and ASP.NET Core web applications handle web requests.
Microsoft is releasing this security advisory to provide information about a vulnerability in .NET Core and ASP.NET Core 1.0, 1.1, 2.1 and 2.2. This advisory also provides guidance on what developers can do to update their applications to remove this vulnerability.
A denial of service vulnerability exists when .NET Core and ASP.NET Core improperly handle web requests. An attacker who successfully exploited this vulnerability could cause a denial of service against a .NET Core and ASP.NET Core application. The vulnerability can be exploited remotely, without authentication.
A remote unauthenticated attacker could exploit this vulnerability by issuing specially crafted requests to a .NET Core application.
The update addresses the vulnerability by correcting how .NET Core and ASP.NET Core web applications handle web requests.
Microsoft is releasing this security advisory to provide information about a vulnerability in ASP.NET Core 2.1 and 2.2. This advisory also provides guidance on what developers can do to update their applications to remove this vulnerability.
Microsoft is aware of a denial of service vulnerability exists when ASP.NET Core improperly handles web requests. An attacker who successfully exploited this vulnerability could cause a denial of service against an ASP.NET Core web application. The vulnerability can be exploited remotely, without authentication.
A remote unauthenticated attacker could exploit this vulnerability by issuing specially crafted requests to the ASP.NET Core application.
The update addresses the vulnerability by correcting how the ASP.NET Core web application handles web requests.
Getting the Update
The latest .NET Core updates are available on the .NET Core download page. This update is also included in the Visual Studio 15.0.22 (.NET Core 1.0 and 1.1) and 15.9.9 (.NET Core 1.0, 1.1 and 2.1) updates, which is also releasing today. Choose Check for Updates in the Help menu.
See the .NET Core release notes ( 1.0.16 | 1.1.13 | 2.1.11 | 2.2.5 ) for details on the release including issues fixed and affected packages.
Docker Images
.NET Docker images have been updated for today’s release. The following repos have been updated.
Today, we released a new Windows 10 Preview Build of the SDK to be used in conjunction with Windows 10 Insider Preview (Build 18894 or greater). The Preview SDK Build 18894 contains bug fixes and under development changes to the API surface area.
This build works in conjunction with previously released SDKs and Visual Studio 2017 and 2019. You can install this SDK and still also continue to submit your apps that target Windows 10 build 1903 or earlier to the Microsoft Store.
The Windows SDK will now formally only be supported by Visual Studio 2017 and greater. You can download the Visual Studio 2019 here.
Now detects the Unicode byte order mark (BOM) in .mc files. If the .mc file starts with a UTF-8 BOM, it will be read as a UTF-8 file. Otherwise, if it starts with a UTF-16LE BOM, it will be read as a UTF-16LE file. If the -u parameter was specified, it will be read as a UTF-16LE file. Otherwise, it will be read using the current code page (CP_ACP).
Now avoids one-definition-rule (ODR) problems in MC-generated C/C++ ETW helpers caused by conflicting configuration macros (e.g. when two .cpp files with conflicting definitions of MCGEN_EVENTWRITETRANSFER are linked into the same binary, the MC-generated ETW helpers will now respect the definition of MCGEN_EVENTWRITETRANSFER in each .cpp file instead of arbitrarily picking one or the other).
Windows Trace Preprocessor (tracewpp.exe)
Now supports Unicode input (.ini, .tpl, and source code) files. Input files starting with a UTF-8 or UTF-16 byte order mark (BOM) will be read as Unicode. Input files that do not start with a BOM will be read using the current code page (CP_ACP). For backwards-compatibility, if the -UnicodeIgnore command-line parameter is specified, files starting with a UTF-16 BOM will be treated as empty.
Now supports Unicode output (.tmh) files. By default, output files will be encoded using the current code page (CP_ACP). Use command-line parameters -cp:UTF-8 or -cp:UTF-16 to generate Unicode output files.
Behavior change: tracewpp now converts all input text to Unicode, performs processing in Unicode, and converts output text to the specified output encoding. Earlier versions of tracewpp avoided Unicode conversions and performed text processing assuming a single-byte character set. This may lead to behavior changes in cases where the input files do not conform to the current code page. In cases where this is a problem, consider converting the input files to UTF-8 (with BOM) and/or using the -cp:UTF-8 command-line parameter to avoid encoding ambiguity.
TraceLoggingProvider.h
Now avoids one-definition-rule (ODR) problems caused by conflicting configuration macros (e.g. when two .cpp files with conflicting definitions of TLG_EVENT_WRITE_TRANSFER are linked into the same binary, the TraceLoggingProvider.h helpers will now respect the definition of TLG_EVENT_WRITE_TRANSFER in each .cpp file instead of arbitrarily picking one or the other).
In C++ code, the TraceLoggingWrite macro has been updated to enable better code sharing between similar events using variadic templates.
Breaking Changes
Removal of IRPROPS.LIB
In this release irprops.lib has been removed from the Windows SDK. Apps that were linking against irprops.lib can switch to bthprops.lib as a drop-in replacement.
namespace Windows.Foundation.Metadata {
public sealed class AttributeNameAttribute : Attribute
public sealed class FastAbiAttribute : Attribute
public sealed class NoExceptionAttribute : Attribute
}
namespace Windows.Graphics.Capture {
public sealed class GraphicsCaptureSession : IClosable {
bool IsCursorCaptureEnabled { get; set; }
}
}
namespace Windows.Management.Deployment {
public enum DeploymentOptions : uint {
AttachPackage = (uint)4194304,
}
}
namespace Windows.Networking.BackgroundTransfer {
public sealed class DownloadOperation : IBackgroundTransferOperation, IBackgroundTransferOperationPriority {
void RemoveRequestHeader(string headerName);
void SetRequestHeader(string headerName, string headerValue);
}
public sealed class UploadOperation : IBackgroundTransferOperation, IBackgroundTransferOperationPriority {
void RemoveRequestHeader(string headerName);
void SetRequestHeader(string headerName, string headerValue);
}
}
namespace Windows.UI.Composition.Particles {
public sealed class ParticleAttractor : CompositionObject
public sealed class ParticleAttractorCollection : CompositionObject, IIterable<ParticleAttractor>, IVector<ParticleAttractor>
public class ParticleBaseBehavior : CompositionObject
public sealed class ParticleBehaviors : CompositionObject
public sealed class ParticleColorBehavior : ParticleBaseBehavior
public struct ParticleColorBinding
public sealed class ParticleColorBindingCollection : CompositionObject, IIterable<IKeyValuePair<float, ParticleColorBinding>>, IMap<float, ParticleColorBinding>
public enum ParticleEmitFrom
public sealed class ParticleEmitterVisual : ContainerVisual
public sealed class ParticleGenerator : CompositionObject
public enum ParticleInputSource
public enum ParticleReferenceFrame
public sealed class ParticleScalarBehavior : ParticleBaseBehavior
public struct ParticleScalarBinding
public sealed class ParticleScalarBindingCollection : CompositionObject, IIterable<IKeyValuePair<float, ParticleScalarBinding>>, IMap<float, ParticleScalarBinding>
public enum ParticleSortMode
public sealed class ParticleVector2Behavior : ParticleBaseBehavior
public struct ParticleVector2Binding
public sealed class ParticleVector2BindingCollection : CompositionObject, IIterable<IKeyValuePair<float, ParticleVector2Binding>>, IMap<float, ParticleVector2Binding>
public sealed class ParticleVector3Behavior : ParticleBaseBehavior
public struct ParticleVector3Binding
public sealed class ParticleVector3BindingCollection : CompositionObject, IIterable<IKeyValuePair<float, ParticleVector3Binding>>, IMap<float, ParticleVector3Binding>
public sealed class ParticleVector4Behavior : ParticleBaseBehavior
public struct ParticleVector4Binding
public sealed class ParticleVector4BindingCollection : CompositionObject, IIterable<IKeyValuePair<float, ParticleVector4Binding>>, IMap<float, ParticleVector4Binding>
}
namespace Windows.UI.ViewManagement {
public enum ApplicationViewMode {
Spanning = 2,
}
}
namespace Windows.UI.WindowManagement {
public enum AppWindowPresentationKind {
Spanning = 4,
}
public sealed class SpanningPresentationConfiguration : AppWindowPresentationConfiguration
}
A big impediment to software evolution has been the fact that you couldn’t add new members to a public interface. You would break existing implementers of the interface; after all they would have no implementation for the new member!
Default implementations help with that. An interface member can now be specified with a code body, and if an implementing class or struct does not provide an implementation of that member, no error occurs. Instead, the default implementation is used.
An existing class, maybe in a different code base with different owners, implements ILogger:
class ConsoleLogger : ILogger
{
public void Log(LogLevel level, string message) { ... }
}
Now we want to add another overload of the Log method to the interface. We can do that without breaking the existing implementation by providing a default implementation – a method body:
The ConsoleLogger still satisfies the contract provided by the interface: if it is converted to the interface and the new Log method is called it will work just fine: the interface’s default implementation is just called:
public static void LogException(ConsoleLogger logger, Exception ex)
{
ILogger ilogger = logger; // Converting to interface
ilogger.Log(ex); // Calling new Log overload
}
Of course an implementing class that does know about the new member is free to implement it in its own way. In that case, the default implementation is just ignored.
If you find yourself learning C# and .NET and come upon the "Run your first C# Program" documentation you may have noticed a "Try the code in your browser" button that lets you work through your first app entirely online, with no local installation! You're running C# and .NET in the browser! It's a great way to learn that is familiar to folks who learn JavaScript.
The language team at Microsoft wants to bring that easy on-ramp to everyone who wants to learn .NET.
The .NET Foundation has published a lot of free .NET presentations and workshops that you can use today to teach open source .NET to your friends, colleagues, or students. However these do encourage you to install a number of prerequisites and we believe that there might be an easier on-ramp to learning .NET.
Here's the experience. Once you have the .NET SDK - Pick the one that says you want to "Build Apps." Just get the "try" tool! Try it!
Open a terminal/command prompt and type dotnet tool install --global dotnet-try
Now you can either navigate to an empty folder and type
dotnet try demo
or, even better, do this!
ACTION: Clone the samples repo with
git clone https://github.com/dotnet/try -b samples
then run
"dotnet try"
and that's it!
NOTE: Make sure you get the samples branch until we have more samples!
C:UsersscottDesktop> git clone https://github.com/dotnet/try -b samples
Cloning into 'try'...
C:UsersscottDesktop> cd .trySamples
C:UsersscottDesktoptrySamples [samples ≡]> dotnet try
Hosting environment: Production
Content root path: C:UsersscottDesktoptrySamples
Now listening on: http://localhost:5000
Now listening on: https://localhost:5001
Your browser will pop up and you're inside a local interactive workshop! Notice the URL? You're browsing your *.md files and the code inside is runnable. It's all local to you! You can put this on a USB key and learn offline or in disconnected scenarios which is great for folks in developing countries. Take workshops home and remix! Run an entire workshop in the browser and the setup instructions for the room is basically "get this repository" and type "dotnet try!"
This is not just a gentle on-ramp that teaches .NET without yet installing Visual Studio, but it also is a toolkit for you to light up your own Markdown.
Just add a code fence - you may already be doing this! Note the named --region there? It's not actually running the visible code in the Markdown...it's not enough! It's compiling your app and capturing the result of the named region in your source! You could even make an entire .NET interactive online book.
### Methods
A **method** is a block of code that implements some action. `ToUpper()` is a method you can invoke on a string, like the *name* variable. It will return the same string, converted to uppercase.
``` cs --region methods --source-file .myappProgram.cs --project .myappmyapp.csproj
var name = "Friends";
Console.WriteLine($"Hello {name.ToUpper()}!");
```
And my app's code might look like:
using System;
namespace HelloWorld
{
class Program
{
static void Main(string[] args)
{
#region methods
var name = "Friends"
Console.WriteLine($"Hello {name.ToUpper()}!");
#endregion
}
}
}
Make sense?
NOTE: Closing code fences ``` must be on a newline.
Hey you! YOU have some markdown or just a readme.md in your project! Can you light it up and make a workshop for folks to TRY your project?
Here I've typed "dotnet try verify" to validate my markdown and ensure my samples compile. Dotnet Try is both a runner and a creator's toolkit.
Today "dotnet try" uses .NET Core 2.1 but if you have .NET Core 3 installed you can explore the more complex C# samples here with even more interesting and sophisticated presentations. You'll note in the markdown the --session argument for the code fence allows for interesting scenarios where more than one editor runs in the context of one operation!
I'd love to see YOU create workshops with Try .NET. It's early days and this is an Alpha release but we think it's got a lot of promise. Try installing it and running it now and later head over to https://github.com/dotnet/try to file issues if you find something or have an idea.
Go install "dotnet try" locally now, and remember this is actively being developed so you can update it easily and often like this!
dotnet tool update -g dotnet-try
There's lots of ideas planned, as well as the ability to publish your local workshop as an online one with Blazor and WASM. Here's a live example.
Watch for an much more in-depth post from Maria from my team on Thursday on the .NET blog!
Sponsor: Suffering from a lack of clarity around software bugs? Give your customers the experience they deserve and expect with error monitoring from Raygun.com. Installs in minutes, try it today!
This month is packed with updates on the Azure portal, including enhancements to the user experience, resource configuration, management tools and more.
Sign in to the Azure portal now and see for yourself everything that’s new. Download the Azure mobile app to stay connected to your Azure resources anytime, anywhere.
Here’s the list of May updates to the Azure portal:
We have heard your feedback that despite being a single page application, the portal should behave like a normal web site in as many cases as possible. With this month's release you can open many more of the portal's links in a new tab using standard browser mechanisms such as right click or CtrlShift + Left click. The improvement is most visible in the pages that list resources. You'll find that the links in the NAME, RESOURCE GROUP, and SUBSCRIPTION columns all support this behavior. A normal click will still result in an in place navigation.
Azure Virtual Machine Scale Sets (VMSS) let you create and manage a group load balanced VMs. The number of VM instances can automatically increase or decrease in response to demand or a defined schedule. Scale sets provide high availability to your applications, and allow you to centrally manage, configure, and update a large number of VMs.
You can now manage and access additional diagnostic tools for your VMSS instances via the portal:
Boot diagnostics: access console output and screenshot support for Azure Virtual Machines.
Serial console: this serial connection connects to the COM1 serial port of the virtual machine, providing access independent of the virtual machine's network or operating system state.
Resource health: resource health informs you about the current and past health of your resources, including times your resources were unavailable in the past because of Azure service problems.
Serial console
To try out these tools, take the following steps:
Navigate to an existing Virtual Machine Scale Set instance.
In the left navigation menu, you'll find the Boot Diagnostics tab in the Support + troubleshooting section. Ensure that Boot diagnostics is enabled for the scale set (you'll need to create or select a storage account to hold the diagnostic logs).
If your scale set is set to automatic or rolling upgrade mode, each instance will be updated to receive the latest scale set model. If your scale set is set to manual upgrade mode, you will have to manually update instances from the VMSS > Instances blade.
Once each instance has received the latest model, boot diagnostics and serial console will be available for you.
Virtual machine resource name: this is the Azure identifier for the virtual machine resource. It is the name you use to reference the virtual machine in any Azure automation. It cannot be changed.
Computer hostname: the runtime computer name of the in-guest operating system. The computer name can be changed at will.
If you create a VM using the Azure portal, for simplicity we use the same name for both the virtual machine resource name, and the computer hostname. You could always log into the VM and change the hostname; however, the portal only showed the virtual machine resource name. With this change, the portal now exposes both the virtual machine name, and the computer hostname in the VM overview blade. We also added more detailed operation system version info. These properties are visible for running virtual machines that have a healthy running VMAgent installed.
The Azure Container Instances creation experience in portal has been completely redone, moving it to the new create style with convenient tabs and a simplified flow. Specific improvements to adding environment variables and specifying container sizes (including support for GPU cores) were also included.
ACI now uses the same create pattern as other services
To try out the new create experience:
Go to the "+ Create a resource" button in the top-left of the portal
Choose the "Containers" category, and then choose "Container Instances".
From an Azure Kubernetes Service cluster in the portal you can now add integrations with other Azure services including Dev Spaces, deployment center from Azure DevOps, and Policies. With the enhanced debugging capabilities offered by Dev Spaces, the robust deployment pipeline offered through the deployment center, and the increased control over containers offered by policies, setting up powerful tools for managing and maintaining Kubernetes clusters in Azure is now even easier.
New integrations now available
To try out the new integrations:
Go to the overview for any Azure Kubernetes Service cluster
Look for the following new menu items on the left:
Multiple node pools for Azure Kubernetes Service are now shown in the Azure portal for any clusters in the preview. New node pools can be added to the cluster and existing node pools can be removed, allowing for clusters with mixed VM sizes and even mixed operating systems. Find more details on the new multiple node pool functionality.
Node pools blade
Add a node pool
To try out multiple node pools:
If you are not already participating, please visit the multiple node pools preview to learn more about multiple node pools.
If you already have a cluster with multiple node pools, look for the new 'Node pools (preview)' option in the left menu for your cluster in the portal.
Azure has numerous data transfer offerings catering to different capabilities in order help users transfer data to a storage account. The new Data Transfer feature presents the recommended solutions depending on the available network bandwidth in your environment, the size of the data you intend to transfer, and the frequency at which you transfer. For each solution, a description, estimated time to transfer and best use case is shown.
Data Transfer
To try out Azure Storage Data Transfer:
Select a Storage Account
Click on the "Data transfer" ToC menu item on the left-hand side
Select an item in the drop down for 3 different fields:
Estimate data size for transfer
Approximate available network bandwidth
Transfer frequency
For more in-depth information, check out the documentation.
The Azure Quickstart Center is a new experience to help you create and deploy your first cloud projects with confidence. We launched it as a preview at Microsoft Build 2018 and are now proud to announce it is generally available.
Users can now move a VM from one group to another, and by doing that, the application control policy applied to it will change according to the settings of that group. Up to now, after a VM was configured within a specific group, it could not be reassigned. VMs can now also be moved from a configured group to a non-configured group, which will result in removing any application control policy that was previously applied to the VM. For more information, see Adaptive application controls in Azure Security Center.
Advanced Threat Protection (ATP) for Azure Storage provides an additional layer of security intelligence that detects unusual and potentially harmful attempts to access or exploit storage accounts. This layer of protection allows you to protect and address concerns about potential threats to your storage accounts as they occur, without needing to be an expert in security. To learn more, see Advanced Threat Protection for Azure Storage or read about the ATP for Storage price in Azure Security Center pricing page.
Azure Security Center now identifies virtual machine scale sets and provides recommendations for scale sets. For more information, see virtual machine scale sets.
One of the biggest attack surfaces for workloads running in the public cloud are connections to and from the public Internet. Our customers find it hard to know which Network Security Group (NSG) rules should be in place to make sure that Azure workloads are only available to required source ranges. With this feature, Security Center learns the network traffic and connectivity patterns of Azure workloads and provides NSG rule recommendations, for internet facing virtual machines. This helps our customer better configure their network access policies and limit their exposure to attacks.
The Regulatory Compliance Dashboard helps Security Center you streamline your compliance process, by providing insights into your compliance posture for a set of supported standards and regulations.
The compliance dashboard surfaces security assessments and recommendations as you align to specific compliance requirements, based on continuous assessments of your Azure and hybrid workload. The dashboard also provides actionable information for how to act on recommendations and reduce risk factors in your environment, to improve your overall compliance posture. The dashboard is now generally available for Security Center Standard tier customers. For more information, see Improve your regulatory compliance.
Azure Site Recovery has enhanced the health monitoring of your workloads on VMware or physical servers by introducing various health signals on the replication component, Process Server. Notifications are raised on multiple parameters of Process Server: free space utilization, memory usage, CPU utilization, and achieved throughput.
The new enhancement on Process Server alerts for VMware and physical workloads also helps in new protections with Azure Site Recovery. These alerts also help with load balancing of Process Servers. The signals are powerful as the scale of the workloads grows. This guidance ensures that the apt number of virtual machines are connected to a Process Server, and that related issues can be avoided.
New alerts
To try out the new alerts:
Start the enable replication workflow for a Physical or a VMware machine.
At the time of source selection, choose the Process Server from the dropdown list.
The health of the Process Server is displayed against each Process Server. Warning health status deters the user’s choice by raising warning, while critical health completely blocks the PS selection.
Non-Azure group targeting for Azure update management is now available in public preview. This feature supports dynamic targeting of patch deployments to non-Azure machines based on Log Analytics saved searches.
This feature enables dynamic resolution of the target machines for an update deployment based on saved searches. After the deployment is created, any new machines added to update management that meet the search criteria will be automatically picked up and patched in the next deployment run without requiring the user to modify the update deployment itself.
The Microsoft Intune team has been hard at work on updates as well. You can find the full list of updates to Intune on the What's new in Microsoft Intune page, including changes that affect your experience using Intune.
Azure portal “how to” video series
Have you checked out our Azure portal “how to” video series yet? The videos highlight specific aspects of the portal so you can be more efficient and productive while deploying your cloud workloads from the portal. Recent videos include a demonstration of how to create a storage account and upload a blob and how to create an Azure Kubernetes Service cluster in the portal. Keep checking our playlist on YouTube for a new video each week.
Next steps
The Azure portal’s large team of engineers always wants to hear from you, so please keep providing us with your feedback in the comments section below or on Twitter @AzurePortal.
In previous posts I’ve talked about performance improvements that our team contributed to the Git community. At Microsoft, we’ve been pushing Git to its limits with the largest and busiest Git repositories on the planet, improving core Git as we go and sending these improvements back upstream. With Git 2.21.0 and later you can take advantage of a new sparse pack algorithm that we developed to dramatically improve the git push operation on large repos. For example, the Windows team saw a 7.7x performance boost once they enabled this new feature. In this post I want to explain the new sparse pack algorithm and why it improves performance.
If you want to try it yourself, the new algorithm is available in Git and Git for Windows versions 2.21.0 and later. We also shipped this algorithm in VFS for Git 1.0.19052.1 and later. If you want to skip the details and enable this on your machine, run the following config command:
git config --global pack.useSparse true
This enables the new “sparse” algorithm when constructing a pack in the underlying git pack-objects command during a push.
Let’s dig into the difference between the old and new algorithms. To follow the full details, you may want to brush up on some Git fundamentals, such as the basic Git objects: commit, tree, and blob.
What does git push do?
When you run git push from your client machine, Git shows something like this:
$ git push origin topic Enumerating objects: 3670, done. Counting objects: 100% (2369/2369), done. Delta compression using up to 8 threads Compressing objects: 100% (546/546), done. Writing objects: 100% (1378/1378), 468.06 KiB | 7.67 MiB/s, done. Total 1378 (delta 1109), reused 1096 (delta 832) remote: Resolving deltas: 100% (1109/1109), completed with 312 local objects. To https://server.info/fake.git * [new branch] topic -> topic
That’s a lot of data to process. Today, I want to focus on the “Enumerating Objects” phase. Specifically, there is a computation that happens before any progress is output at all, and it can be very slow in a large repo.
In the Windows repo, “Enumerating objects” was taking up to 87% of the time to push even small changes. Instead of walking at least three million objects, we are now walking fewer than one thousand in most cases.
What does “Enumerating objects” mean?
When you create a new repo, the first push collects all objects and sends them in a single pack-file to the remote. This is essentially the same operation as a git clone, but in reverse. In the same way that later git fetch operations are usually faster than your first git clone, later pushes should be faster than your first push.
To save time, Git constructs a pack-file that contains the commit you are trying to push, as well as all commits, trees, and blobs (collectively, objects) that the server will need to understand that commit. It finds a set of commits, trees, and blobs such that every reachable object is either in the set or known to be on the server.
The old algorithm first walks and marks the objects that are known to be on the server, then walks the new objects, stopping at the marked objects. The new algorithm walks these objects at the same time.
To understand how it does that, let’s explore the frontiers of Git.
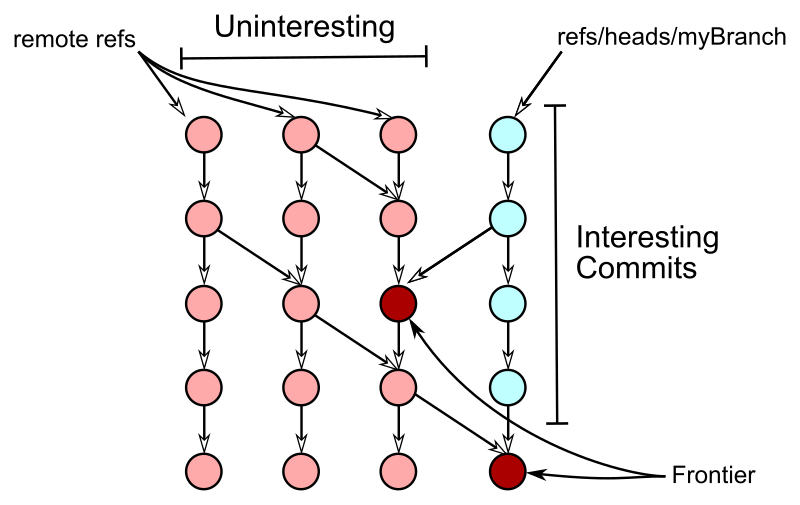
The Commit Frontier
When deciding which objects to send in a push, Git first determines a small, important set of commits called the frontier. Starting at the set of remote references and at the branch we are trying to push, Git walks the commit history until finding a set of commits that are reachable from both. Commits reachable from the remote refs are marked as uninteresting while the other commits are marked as interesting.
The commit frontier
The uninteresting commits that are direct parents of interesting commits form the frontier. This frontier set is likely very small when pushing a single branch from a developer. This could grow if your branch contains many merge commits formed from git pull commands.
Since this frontier is much smaller than the full set of uninteresting commits, Git will ignore the rest of the uninteresting commits and focus on the frontier for the remainder of the command.
An important feature of the new algorithm is that we walk the uninteresting and interesting commits at the same time. At each step, we use the commit date as a heuristic for deciding which commit to explore next. This helps identify the frontier without walking the entire commit history, which is usually much larger than the full explored set.
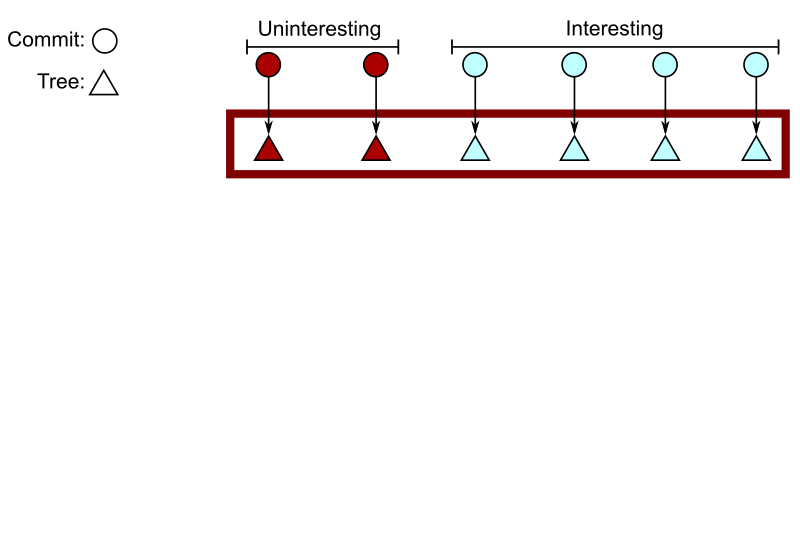
The rest of the algorithm walks trees to find which trees and blobs are important to include in the push.
Old Algorithm
To determine which trees and blobs are interesting, the old algorithm first determined all uninteresting trees and blobs.
Starting at every uninteresting commit in the frontier, recursively walk from its root tree and mark all reachable trees and blobs as uninteresting. This walk skips trees that were already marked as uninteresting to avoid revisiting potentially large portions of the graph. Since Git objects form a Merkle tree, portions of the working directory that do not change between commits are stored as the same trees and blobs, with the same object hash. In the figure below, this is represented by a smaller set of trees walked from the second uninteresting commit. The “already uninteresting” connections are marked by arcs into the larger uninteresting set.
The old algorithm for walking trees during a push
After all uninteresting trees and blobs are marked, walk starting at the root trees of the interesting commits. All trees and blobs that are not already marked as uninteresting are marked interesting.
The issue with this algorithm is clear: if your repo has thousands of paths and you only changed a few files, then the uninteresting set is much larger than the interesting set. In large repos, there could easily be hundreds of thousands of paths. In the Windows OS repo, there are more than three million paths.
To fix the performance, we need to make this process more like the commit frontier calculation: we need to walk interesting and uninteresting trees at the same time to avoid walking too many uninteresting objects!
New Algorithm
The new algorithm uses paths as our heuristic to help find the “tree frontier” between the interesting and uninteresting objects. To illustrate this, let’s consider a very simple example.
Imagine we have a large codebase whose folder structure starts with folders A1 and A2. In each of those folders is a pair of folders B1 and B2, and so on along the Latin alphabet. Imagine that we have interesting content in each of these folders.
As you are doing your work, you create a topic branch containing one commit, and that commit adds a new file at A2/B2/C2/MyFile.txt. You want to push this change, and thinking about the simple diff between your commit and its parent you need to send one commit, four trees, and one blob. Here is a figure describing the diff:
A simple example for a single commit
As you walk down your change, you can ignore all of the trees along paths A1, A2/B1, A2/B2/C1, A2/B2/C2/D1, and A2/B2/C2/D2 since you don’t change any objects in those paths.
The old algorithm is recursive: it takes a tree and runs the algorithm on all subtrees. This doesn’t help us in the example above, as we will need to walk all 226 paths (approximately 67 million paths). This is an extreme example, but it demonstrates the inefficiency.
The new algorithm uses the paths to reduce the scope of the tree walk. It is also recursive, but it takes a set of trees. As we start the algorithm, the set of trees contains the root trees for the uninteresting and the interesting commits.
As we examine trees in the set, we mark all blobs in an uninteresting tree as uninteresting.
It is more complicated to handle the subtrees. We create a collection of tree sets, each associated with a path name. When we examine a tree, we read each subtree as a (path, tree) pair. We place the subtree in the set corresponding to that path. If the original tree is uninteresting, we mark the subtree as uninteresting.
After we create the collection of tree sets, we recursively explore each set. The trick is that we do not need to explore a set that contains only uninteresting trees or only interesting trees.
This process is visualized in the figure below.
The new tree walk recursively explores paths containing interesting and uninteresting trees
In this specific example our root trees contain three paths that point to trees: A, B, and C. None of the interesting trees change any files in A, so all of those trees are uninteresting and we can stop exploring. The uninteresting trees do not contain the path C (this must be a new path introduced by the interesting commits) so we can stop exploring that path. The trees at the path B are both uninteresting and interesting, so we recursively explore that set.
Inside the trees at B, we have subtrees with names F and G. Both sets have interesting and uninteresting paths, so we recurse into each set. This continues into B/F and B/G. The B/F set will not recurse into B/F/M or B/F/N and the B/G set will not recurse into B/G/X but not B/G/Y.
Keep in mind that in each set of trees, we are marking blobs as uninteresting, too. They are just not depicted in the figure.
If you want a more interactive description of this algorithm, John Briggs talked about this algorithm as part of his talk at Git Merge 2019. You can watch the whole video below, or jump to his description of the push algorithm.
When you use this algorithm as a developer doing normal topic work, this algorithm successfully focuses the tree walk to paths that you actually changed. In most cases, that set is much smaller than the set of paths in your working directory, which is how git push can get so much faster.






























 If you find yourself learning C# and .NET and come upon the "
If you find yourself learning C# and .NET and come upon the "