This spring Gratian Lup described in his blog post the improvements for C++ game development in Visual Studio 2019. From Visual Studio 2019 version 16.0 to Visual Studio 2019 version 16.2 we’ve made some more improvements. On the Infiltrator Demo we’ve got 2–3% performance wins for the most CPU-intensive parts of the game.
Throughput
A huge throughput improvement was done in the linker! Check our recent blogpost on Improved Linker Fundamentals in Visual Studio 2019.
New Optimizations
A comprehensive list of new and improved C++ compiler optimizations can be found in a recent blogpost on MSVC Backend Updates in Visual Studio 2019 version 16.2. I’ll talk in a bit more detail about some of them.
All samples below are compiled for x64 with these switches: /arch:AVX2 /O2 /fp:fast /c /Fa.
Vectorizing tiny perfect reduction loops on AVX
This is a common pattern for making sure that two vectors didn’t diverge too much:
#include <xmmintrin.h>
#include <DirectXMath.h>
uint32_t TestVectorsEqual(float* Vec0, float* Vec1, float Tolerance = 1e7f)
{
float sum = 0.f;
for (int32_t Component = 0; Component < 4; Component++)
{
float Diff = Vec0[Component] - Vec1[Component];
sum += (Diff >= 0.0f) ? Diff : -Diff;
}
return (sum <= Tolerance) ? 1 : 0;
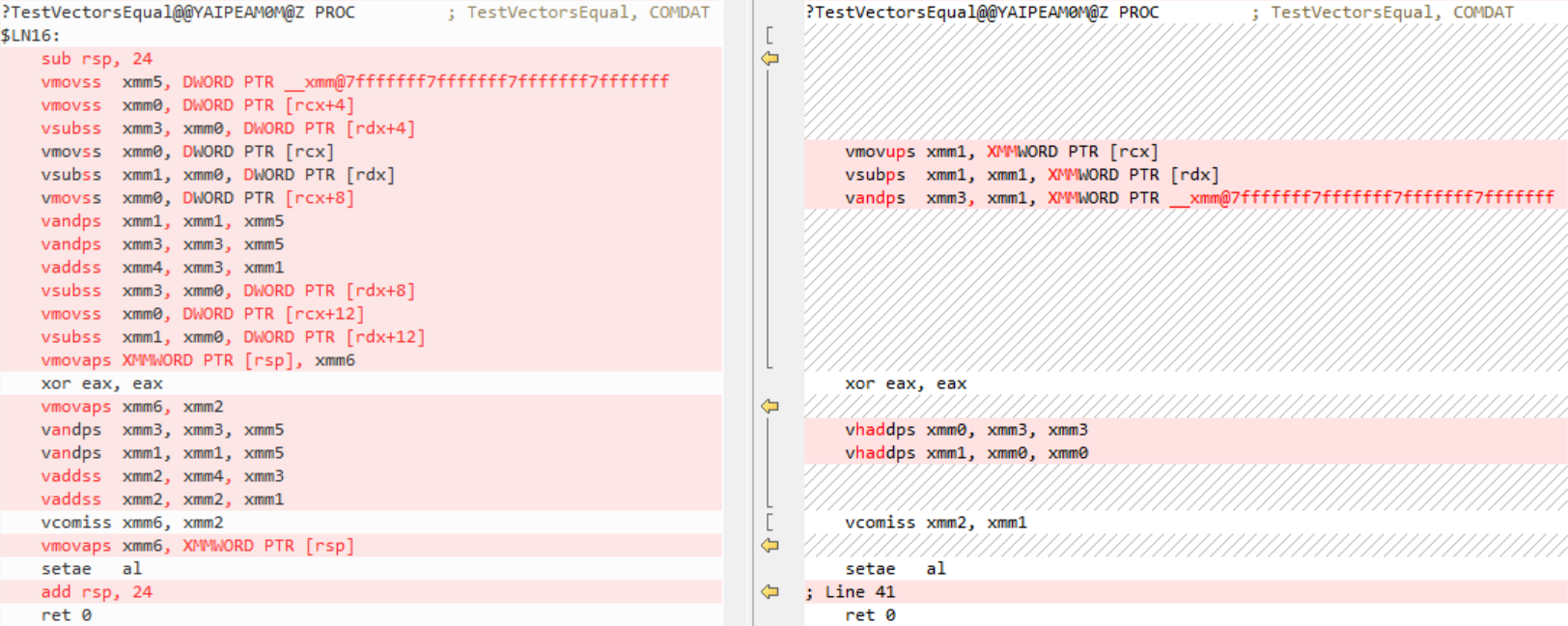
}For version 16.2 we tweaked the vectorization heuristics for the AVX architecture to better utilize the hardware capabilities. The disassembly is for x64, AVX2, old code on the left, new on the right:
![Comparison of old code versus the much-improved new code]()
Visual Studio 2019 version 16.0 recognized the loop as a reduction loop, didn’t vectorize it, but unrolled it completely. Version 16.2 also recognized the loop as a reduction loop, vectorized it (due to the heuristics change), and used horizontal add instructions to get the sum. As a result the code is much shorter and faster now.
Recognition of intrinsics working on a single vector element
The compiler now does a better job at optimizing vector intrinsics working on the lowest single element (those with ss/sd suffix).
A good example for the improved code is the inverse square root. This function is taken from the Unreal Engine math library (with comments removed for brevity). It’s used all over the games based on Unreal Engine for rendering objects:
#include <xmmintrin.h>
#include <DirectXMath.h>
float InvSqrt(float F)
{
const __m128 fOneHalf = _mm_set_ss(0.5f);
__m128 Y0, X0, X1, X2, FOver2;
float temp;
Y0 = _mm_set_ss(F);
X0 = _mm_rsqrt_ss(Y0);
FOver2 = _mm_mul_ss(Y0, fOneHalf);
X1 = _mm_mul_ss(X0, X0);
X1 = _mm_sub_ss(fOneHalf, _mm_mul_ss(FOver2, X1));
X1 = _mm_add_ss(X0, _mm_mul_ss(X0, X1));
X2 = _mm_mul_ss(X1, X1);
X2 = _mm_sub_ss(fOneHalf, _mm_mul_ss(FOver2, X2));
X2 = _mm_add_ss(X1, _mm_mul_ss(X1, X2));
_mm_store_ss(&temp, X2);
return temp;
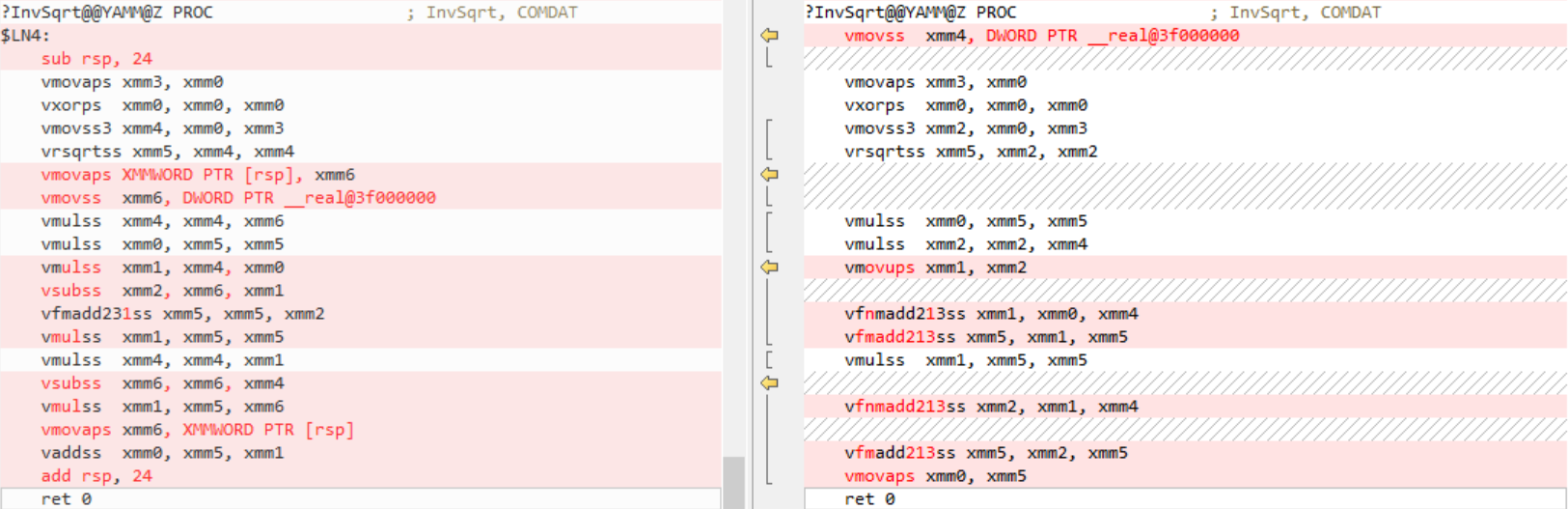
}Again, x64, AVX2, old code on the left, new on the right:
![Comparison of old code versus the much-improved new code]()
Visual Studio 2019 version 16.0 generated code for all intrinsics one by one. Version 16.2 now understands the meaning of the intrinsics better and is able to combine multiply/add intrinsics into FMA instructions. There are still improvements to be made in this area and some are targeted for version 16.3/16.4.
Even now, if given a const argument, this code will be completely constant-folded:
float ReturnInvSqrt()
{
return InvSqrt(4.0);
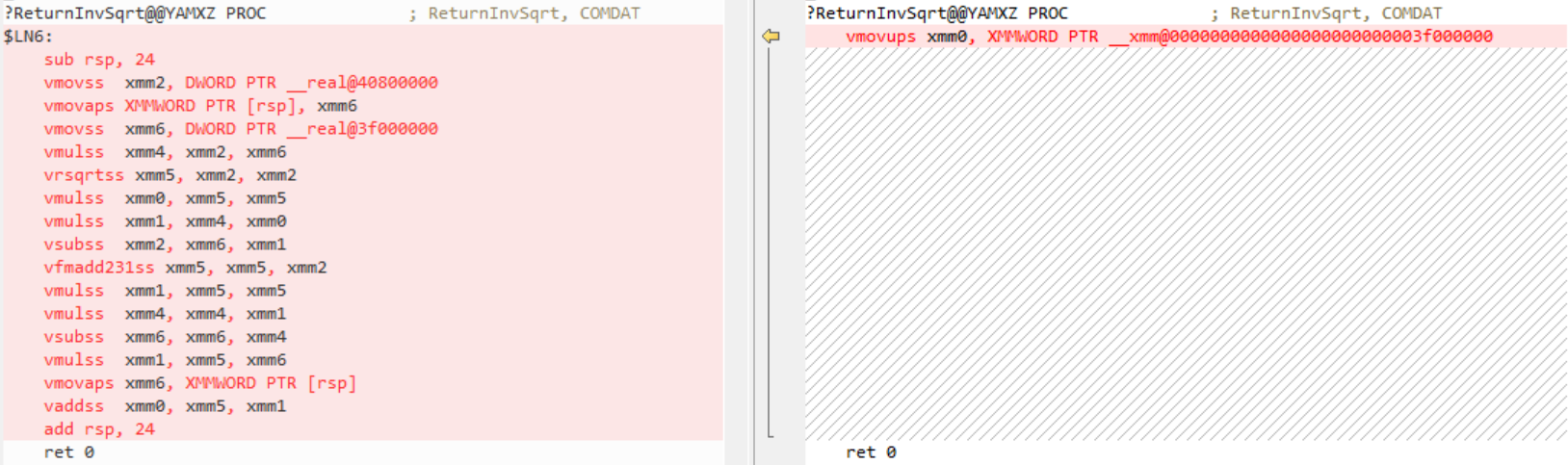
}![Comparison of old code versus the much-improved new code]()
Again, Visual Studio 2019 version 16.0 here generated code for all intrinsics, one by one. Version 16.2 was able to calculate the value at compile time. (This is done with /fp:fast switch only).
More FMA patterns
The compiler now generates FMA in more cases:
(fma a, b, (c * d)) + x -> fma a, b, (fma c, d, x)
x + (fma a, b, (c * d)) -> fma a, b, (fma c, d, x)
(a+1) * b -> fma a, b, b
(a+ (-1)) * b -> fma a, b, (-b)
(a – 1) * b -> fma a, b, (-b)
(a – (-1)) * b -> fma a, b, b
(1 – a) * b -> fma (-a), b, b
(-1 – a) * b -> fma (-a), b, -b
It also does more FMA simplifications:
fma a, c1, (a * c2) -> fmul a * (c1+c2)
fma (a * c1), c2, b -> fma a, c1*c2, b
fma a, 1, b -> a + b
fma a, -1, b -> (-a) + b -> b – a
fma -a, c, b -> fma a, -c, b
fma a, c, a -> a * (c+1)
fma a, c, (-a) -> a * (c-1)
Previously FMA generation worked only with local vectors. It was improved to work on globals too.
Here is an example of the optimization at work:
#include <xmmintrin.h>
__m128 Sample(__m128 A, __m128 B)
{
const __m128 fMinusOne = _mm_set_ps1(-1.0f);
__m128 X;
X = _mm_sub_ps(A, fMinusOne);
X = _mm_mul_ps(X, B);
return X;
}Old code on the left, new on the right:
![Comparison of old code versus the much-improved new code]()
FMA is shorter and faster, and the constant is completely gone and will not occupy space.
Another sample:
#include <xmmintrin.h>
__m128 Sample2(__m128 A, __m128 B)
{
__m128 C1 = _mm_set_ps(3.0, 3.0, 2.0, 1.0);
__m128 C2 = _mm_set_ps(4.0, 4.0, 3.0, 2.0);
__m128 X = _mm_mul_ps(A, C1);
X = _mm_fmadd_ps(X, C2, B);
return X;
}Old code on the left, new on the right:
![Comparison of old code versus the much-improved new code]()
Version 16.2 is doing this simplification:
fma (a * c1), c2, b -> fma a, c1*c2, b
Constants are now extracted and multiplied at compile time.
Memset and initialization
Memset code generation was improved by calling the faster CRT version where appropriate instead of expanding its definition inline. Loops that store a constant value that is formed of the same byte (e.g. 0xABABABAB) now also use the CRT version of memset. Compared with naïve code generation, calling memset is at least 2x faster on SSE2, and even faster on AVX2.
Inlining
We’ve done more tweaks to the inlining heuristics. They were modified to do more aggressive inlining of small functions containing control flow.
Improvements in Unreal Engine – Infiltrator Demo
The new optimizations pay off.
We ran the Infiltrator Demo again (see the blogpost about C++ game development in Visual Studio 2019 for a description of the demo and testing methodology). Short reminder: Infiltrator Demo is based on Unreal Engine and is a nice approximation of a real game. Game performance is measured here by frame time: the smaller, the better (opposite metric would be frames per second). Testing was done similarly to the previous test run, the only difference is the new hardware: this time we ran it on AMD Zen 2 newest processor.
Test PC configuration:
- AMD64 Ryzen 5 3600 6-Core Processor, 3.6 Ghz, 6 Cores, 12 Logical processors
- Radeon RX 550 GPU
- 16 GB RAM
- Windows 10 1903
Results
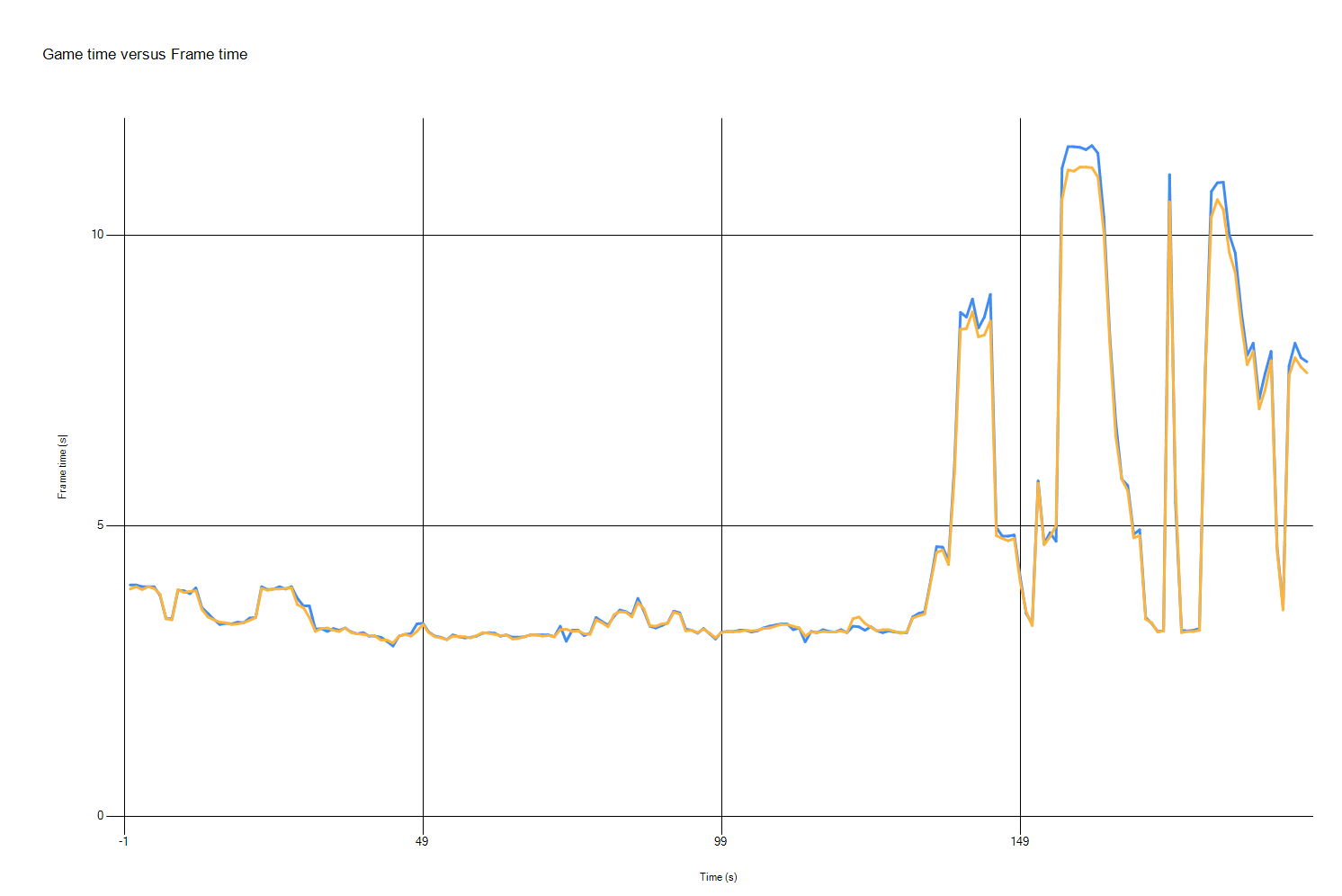
This time we measured only /arch:AVX2 configuration. As previously, the lower the better.
![Graph showing the 2-3% improvements on performance spikes]()
The blue line is the demo compiled with Visual Studio 2019, the yellow line – compiled with Visual Studio 2019 version 16.2. X axis – time, Y axis – frame time.
Frame times are mostly the same between the two runs, but in the parts of the demo where frame times are the highest (and thus the frame rate is lowest) with Visual Studio 2019 version 16.2 we’ve got an improvement of 2–3%.
We’d love for you to download Visual Studio 2019 and give it a try. As always, we welcome your feedback. We can be reached via the comments below or via email (visualcpp@microsoft.com). If you encounter problems with Visual Studio or MSVC, or have a suggestion for us, please let us know through Help > Send Feedback > Report A Problem / Provide a Suggestion in the product, or via Developer Community. You can also find us on Twitter (@VisualC).
The post Game performance improvements in Visual Studio 2019 version 16.2 appeared first on C++ Team Blog.





 DO start with including a
DO start with including a 













 I love everything about
I love everything about 










