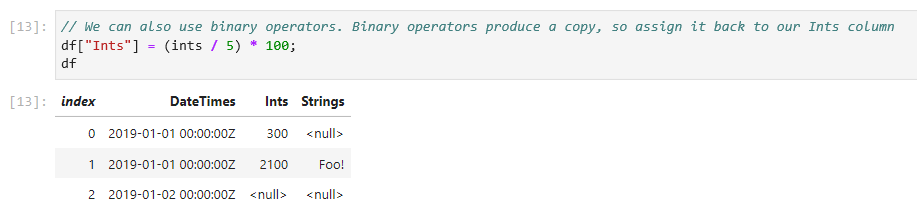
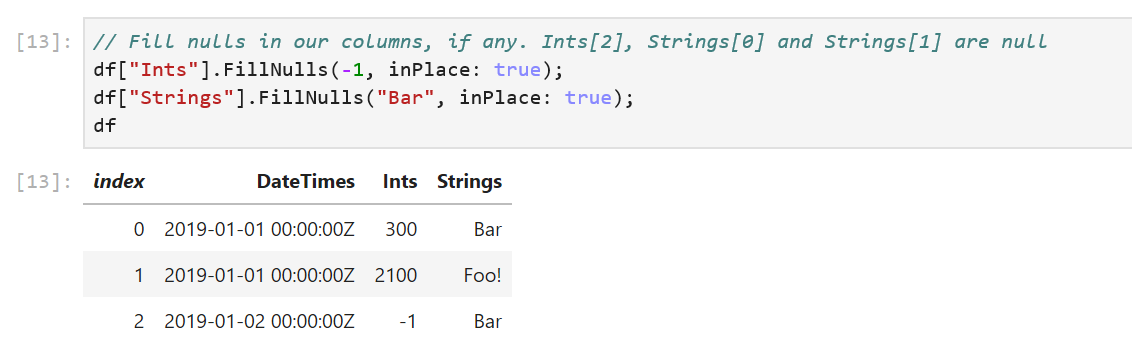
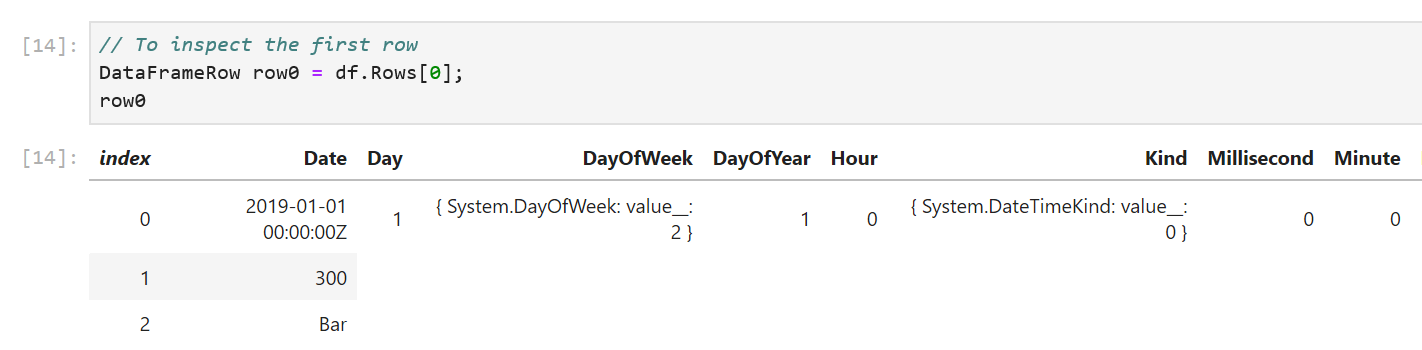
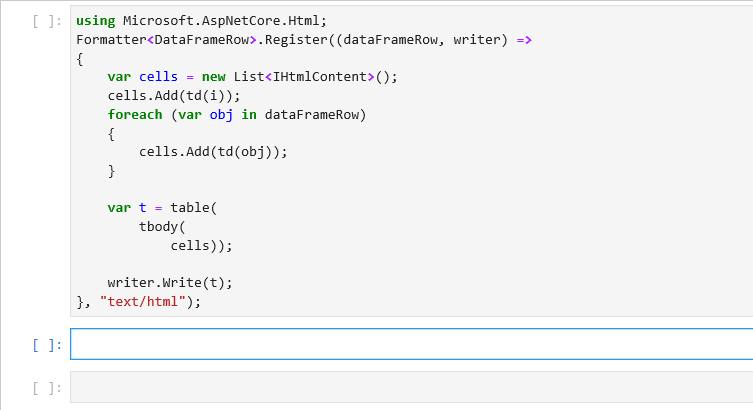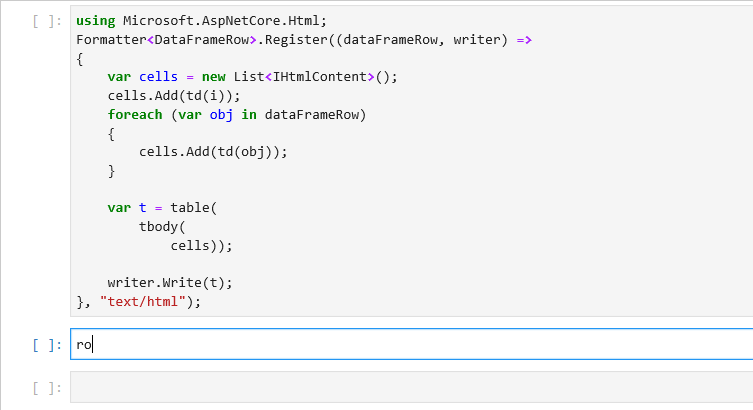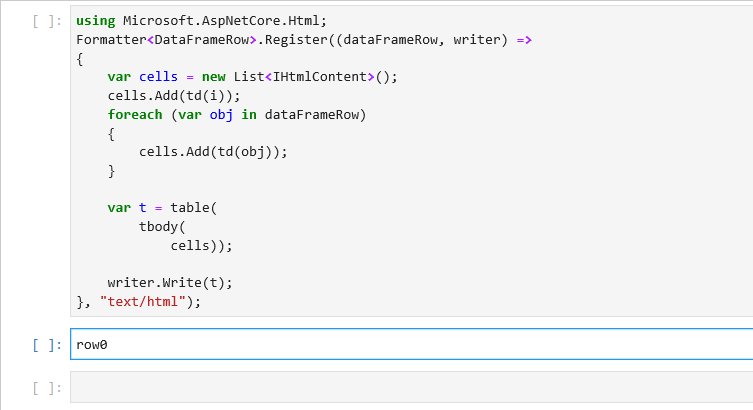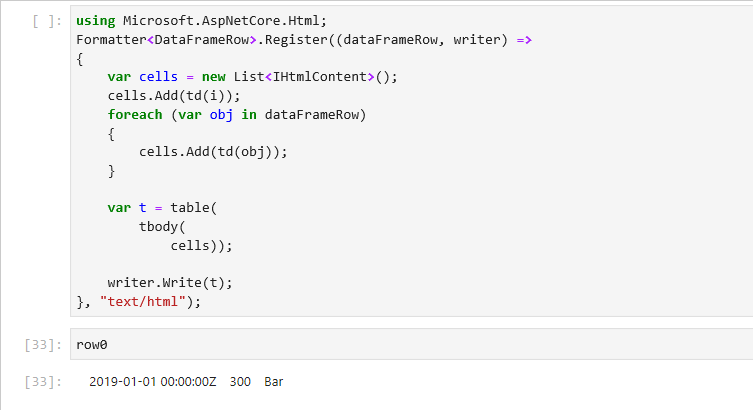
.NET added async/await to the languages and libraries over seven years ago. In that time, it’s caught on like wildfire, not only across the .NET ecosystem, but also being replicated in a myriad of other languages and frameworks. It’s also seen a ton of improvements in .NET, in terms of additional language constructs that utilize asynchrony, APIs offering async support, and fundamental improvements in the infrastructure that makes async/await tick (in particular performance and diagnostic-enabling improvements in .NET Core).
However, one aspect of async/await that continues to draw questions is ConfigureAwait. In this post, I hope to answer many of them. I intend for this post to be both readable from start to finish as well as being a list of Frequently Asked Questions (FAQ) that can be used as future reference.
To really understand ConfigureAwait, we need to start a bit earlier…
What is a SynchronizationContext?
The System.Threading.SynchronizationContext docs state that it “Provides the basic functionality for propagating a synchronization context in various synchronization models.” Not an entirely obvious description.
For the 99.9% use case, SynchronizationContext is just a type that provides a virtual Post method, which takes a delegate to be executed asynchronously (there are a variety of other virtual members on SynchronizationContext, but they’re much less used and are irrelevant for this discussion). The base type’s Post literally just calls ThreadPool.QueueUserWorkItem to asynchronously invoke the supplied delegate. However, derived types override Post to enable that delegate to be executed in the most appropriate place and at the most appropriate time.
For example, Windows Forms has a SynchronizationContext-derived type that overrides Post to do the equivalent of Control.BeginInvoke; that means any calls to its Post method will cause the delegate to be invoked at some later point on the thread associated with that relevant Control, aka “the UI thread”. Windows Forms relies on Win32 message handling and has a “message loop” running on the UI thread, which simply sits waiting for new messages to arrive to process. Those messages could be for mouse movements and clicks, for keyboard typing, for system events, for delegates being available to invoke, etc. So, given a SynchronizationContext instance for the UI thread of a Windows Forms application, to get a delegate to execute on that UI thread, one simply needs to pass it to Post.
The same goes for Windows Presentation Foundation (WPF). It has its own SynchronizationContext-derived type with a Post override that similarly “marshals” a delegate to the UI thread (via Dispatcher.BeginInvoke), in this case managed by a WPF Dispatcher rather than a Windows Forms Control.
And for Windows RunTime (WinRT). It has its own SynchronizationContext-derived type with a Post override that also queues the delegate to the UI thread via its CoreDispatcher.
This goes beyond just “run this delegate on the UI thread”. Anyone can implement a SynchronizationContext with a Post that does anything. For example, I may not care what thread a delegate runs on, but I want to make sure that any delegates Post‘d to my SynchronizationContext are executed with some limited degree of concurrency. I can achieve that with a custom SynchronizationContext like this:
internal sealed class MaxConcurrencySynchronizationContext : SynchronizationContext
{
private readonly SemaphoreSlim _semaphore;
public MaxConcurrencySynchronizationContext(int maxConcurrencyLevel) =>
_semaphore = new SemaphoreSlim(maxConcurrencyLevel);
public override void Post(SendOrPostCallback d, object state) =>
_semaphore.WaitAsync().ContinueWith(delegate
{
try { d(state); } finally { _semaphore.Release(); }
}, default, TaskContinuationOptions.None, TaskScheduler.Default);
public override void Send(SendOrPostCallback d, object state)
{
_semaphore.Wait();
try { d(state); } finally { _semaphore.Release(); }
}
}
In fact, the unit testing framework xunit provides a SynchronizationContext very similar to this, which it uses to limit the amount of code associated with tests that can be run concurrently.
The benefit of all of this is the same as with any abstraction: it provides a single API that can be used to queue a delegate for handling however the creator of the implementation desires, without needing to know the details of that implementation. So, if I’m writing a library, and I want to go off and do some work, and then queue a delegate back to the original location’s “context”, I just need to grab their SynchronizationContext, hold on to it, and then when I’m done with my work, call Post on that context to hand off the delegate I want invoked. I don’t need to know that for Windows Forms I should grab a Control and use its BeginInvoke, or for WPF I should grab a Dispatcher and uses its BeginInvoke, or for xunit I should somehow acquire its context and queue to it; I simply need to grab the current SynchronizationContext and use that later on. To achieve that, SynchronizationContext provides a Current property, such that to achieve the aforementioned objective I might write code like this:
public void DoWork(Action worker, Action completion)
{
SynchronizationContext sc = SynchronizationContext.Current;
ThreadPool.QueueUserWorkItem(_ =>
{
try { worker(); }
finally { sc.Post(_ => completion(), null); }
});
}
A framework that wants to expose a custom context from Current uses the SynchronizationContext.SetSynchronizationContext method.
What is a TaskScheduler?
SynchronizationContext is a general abstraction for a “scheduler”. Individual frameworks sometimes have their own abstractions for a scheduler, and System.Threading.Tasks is no exception. When Tasks are backed by a delegate such that they can be queued and executed, they’re associated with a System.Threading.Tasks.TaskScheduler. Just as SynchronizationContext provides a virtual Post method to queue a delegate’s invocation (with the implementation later invoking the delegate via typical delegate invocation mechanisms), TaskScheduler provides an abstract QueueTask method (with the implementation later invoking that Task via the ExecuteTask method).
The default scheduler as returned by TaskScheduler.Default is the thread pool, but it’s possible to derive from TaskScheduler and override the relevant methods to achieve arbitrary behaviors for when and where a Task is invoked. For example, the core libraries include the System.Threading.Tasks.ConcurrentExclusiveSchedulerPair type. An instance of this class exposes two TaskScheduler properties, one called ExclusiveScheduler and one called ConcurrentScheduler. Tasks scheduled to the ConcurrentScheduler may run concurrently, but subject to a limit supplied to ConcurrentExclusiveSchedulerPair when it was constructed (similar to the MaxConcurrencySynchronizationContext shown earlier), and no ConcurrentScheduler Tasks will run when a Task scheduled to ExclusiveScheduler is running, with only one exclusive Task allowed to run at a time… in this way, it behaves very much like a reader/writer-lock.
Like SynchronizationContext, TaskScheduler also has a Current property, which returns the “current” TaskScheduler. Unlike SynchronizationContext, however, there’s no method for setting the current scheduler. Instead, the current scheduler is the one associated with the currently running Task, and a scheduler is provided to the system as part of starting a Task. So, for example, this program will output “True”, as the lambda used with StartNew is executed on the ConcurrentExclusiveSchedulerPair‘s ExclusiveScheduler and will see TaskScheduler.Current set to that scheduler.
Interestingly, TaskScheduler provides a static FromCurrentSynchronizationContext method, which creates a new TaskScheduler that queues Tasks to run on whatever SynchronizationContext.Current returned, using its Post method for queueing tasks.
How do SynchronizationContext and TaskScheduler relate to await?
Consider writing a UI app with a Button. Upon clicking the Button, we want to download some text from a web site and set it as the Button‘s Content. The Button should only be accessed from the UI thread that owns it, so when we’ve successfully downloaded the new date and time text and want to store it back into the Button‘s Content, we need to do so from the thread that owns the control. If we don’t, we get an exception like:
System.InvalidOperationException: 'The calling thread cannot access this object because a different thread owns it.'
If we were writing this out manually, we could use SynchronizationContext as shown earlier to marshal the setting of the Content back to the original context, such as via a TaskScheduler:
private static readonly HttpClient s_httpClient = new HttpClient();
private void downloadBtn_Click(object sender, RoutedEventArgs e)
{
s_httpClient.GetStringAsync("http://example.com/currenttime").ContinueWith(downloadTask =>
{
downloadBtn.Content = downloadTask.Result;
}, TaskScheduler.FromCurrentSynchronizationContext());
}
or using SynchronizationContext directly:
private static readonly HttpClient s_httpClient = new HttpClient();
private void downloadBtn_Click(object sender, RoutedEventArgs e)
{
SynchronizationContext sc = SynchronizationContext.Current;
s_httpClient.GetStringAsync("http://example.com/currenttime").ContinueWith(downloadTask =>
{
sc.Post(delegate
{
downloadBtn.Content = downloadTask.Result;
}, null);
});
}
Both of these approaches, though, explicitly uses callbacks. We would instead like to write the code naturally with async/await:
private static readonly HttpClient s_httpClient = new HttpClient();
private async void downloadBtn_Click(object sender, RoutedEventArgs e)
{
string text = await s_httpClient.GetStringAsync("http://example.com/currenttime");
downloadBtn.Content = text;
}
This “just works”, successfully setting Content on the UI thread, because just as with the manually implemented version above, awaiting a Task pays attention by default to SynchronizationContext.Current, as well as to TaskScheduler.Current. When you await anything in C#, the compiler transforms the code to ask (via calling GetAwaiter) the “awaitable” (in this case, the Task) for an “awaiter” (in this case, a TaskAwaiter<string>). That awaiter is responsible for hooking up the callback (often referred to as the “continuation”) that will call back into the state machine when the awaited object completes, and it does so using whatever context/scheduler it captured at the time the callback was registered. While not exactly the code used (there are additional optimizations and tweaks employed), it’s something like this:
object scheduler = SynchronizationContext.Current;
if (scheduler is null && TaskScheduler.Current != TaskScheduler.Default)
{
scheduler = TaskScheduler.Current;
}
In other words, it first checks whether there’s a SynchronizationContext set, and if there isn’t, whether there’s a non-default TaskScheduler in play. If it finds one, when the callback is ready to be invoked, it’ll use the captured scheduler; otherwise, it’ll generally just execute the callback on as part of the operation completing the awaited task.
What does ConfigureAwait(false) do?
The ConfigureAwait method isn’t special: it’s not recognized in any special way by the compiler or by the runtime. It is simply a method that returns a struct (a ConfiguredTaskAwaitable) that wraps the original task it was called on as well as the specified Boolean value. Remember that await can be used with any type that exposes the right pattern. By returning a different type, it means that when the compiler accesses the instances GetAwaiter method (part of the pattern), it’s doing so off of the type returned from ConfigureAwait rather than off of the task directly, and that provides a hook to change the behavior of how the await behaves via this custom awaiter.
Specifically, awaiting the type returned from ConfigureAwait(continueOnCapturedContext: false) instead of awaiting the Task directly ends up impacting the logic shown earlier for how the target context/scheduler is captured. It effectively makes the previously shown logic more like this:
object scheduler = null;
if (continueOnCapturedContext)
{
scheduler = SynchronizationContext.Current;
if (scheduler is null && TaskScheduler.Current != TaskScheduler.Default)
{
scheduler = TaskScheduler.Current;
}
}
In other words, by specifying false, even if there is a current context or scheduler to call back to, it pretends as if there isn’t.
Why would I want to use ConfigureAwait(false)?
ConfigureAwait(continueOnCapturedContext: false) is used to avoid forcing the callback to be invoked on the original context or scheduler. This has a few benefits:
Improving performance. There is a cost to queueing the callback rather than just invoking it, both because there’s extra work (and typically extra allocation) involved, but also because it means certain optimizations we’d otherwise like to employ in the runtime can’t be used (we can do more optimization when we know exactly how the callback will be invoked, but if it’s handed off to an arbitrary implementation of an abstraction, we can sometimes be limited). For very hot paths, even the extra costs of checking for the current SynchronizationContext and the current TaskScheduler (both of which involve accessing thread statics) can add measurable overhead. If the code after an await doesn’t actually require running in the original context, using ConfigureAwait(false) can avoid all these costs: it won’t need to queue unnecessarily, it can utilize all the optimizations it can muster, and it can avoid the unnecessary thread static accesses.
Avoiding deadlocks. Consider a library method that uses await on the result of some network download. You invoke this method and synchronously block waiting for it to complete, such as by using .Wait() or .Result or .GetAwaiter().GetResult() off of the returned Task object. Now consider what happens if your invocation of it happens when the current SynchronizationContext is one that limits the number of operations that can be running on it to 1, whether explicitly via something like the MaxConcurrencySynchronizationContext shown earlier, or implicitly by this being a context that only has one thread that can be used, e.g. a UI thread. So you invoke the method on that one thread and then block it waiting for the operation to complete. The operation kicks off the network download and awaits it. Since by default awaiting a Task will capture the current SynchronizationContext, it does so, and when the network download completes, it queues back to the SynchronizationContext the callback that will invoke the remainder of the operation. But the only thread that can process the queued callback is currently blocked by your code blocking waiting on the operation to complete. And that operation won’t complete until the callback is processed. Deadlock! This can apply even when the context doesn’t limit the concurrency to just 1, but when the resources are limited in any fashion. Imagine the same situation, except using the MaxConcurrencySynchronizationContext with a limit of 4. And instead of making just one call to the operation, we queue to that context 4 invocations, each of which makes the call and blocks waiting for it to complete. We’ve now still blocked all of the resources while waiting for the async methods to complete, and the only thing that will allow those async methods to complete is if their callbacks can be processed by this context that’s already entirely consumed. Again, deadlock! If instead the library method had used ConfigureAwait(false), it would not queue the callback back to the original context, avoiding the deadlock scenarios.
Why would I want to use ConfigureAwait(true)?
You wouldn’t. ConfigureAwait(true) does nothing meaningful. When comparing await task with await task.ConfigureAwait(true), they’re functionally identical. If you see ConfigureAwait(true) in production code, you can delete it.
The ConfigureAwait method accepts a Boolean because there are some niche situations in which you want to pass in a variable to control the configuration. But the 99% use case is with a hardcoded false argument value, ConfigureAwait(false).
When should I use ConfigureAwait(false)?
It depends: are you implementing application-level code or general-purpose library code?
When writing applications, you generally want the default behavior (which is why it is the default behavior). If an app model / environment (e.g. Windows Forms, WPF, ASP.NET Core, etc.) publishes a custom SynchronizationContext, there’s almost certainly a really good reason it does: it’s providing a way for code that cares about synchronization context to interact with the app model / environment appropriately. So if you’re writing an event handler in a Windows Forms app, writing a unit test in xunit, writing code in an ASP.NET MVC controller, whether or not the app model did in fact publish a SynchronizationContext, you want to use that SynchronizationContext if it exists. And that means the default / ConfigureAwait(true). You make simple use of await, and the right things happen with regards to callbacks/continuations being posted back to the original context if one existed. This leads to the general guidance of: if you’re writing app-level code, do not use ConfigureAwait(false). If you think back to the Click event handler code example earlier in this post:
private static readonly HttpClient s_httpClient = new HttpClient();
private async void downloadBtn_Click(object sender, RoutedEventArgs e)
{
string text = await s_httpClient.GetStringAsync("http://example.com/currenttime");
downloadBtn.Content = text;
}
the setting of downloadBtn.Content = text needs to be done back in the original context. If the code had violated this guideline and instead used ConfigureAwait(false) when it shouldn’t have:
private static readonly HttpClient s_httpClient = new HttpClient();
private async void downloadBtn_Click(object sender, RoutedEventArgs e)
{
string text = await s_httpClient.GetStringAsync("http://example.com/currenttime").ConfigureAwait(false); // bug
downloadBtn.Content = text;
}
bad behavior will result. The same would go for code in a classic ASP.NET app reliant on HttpContext.Current; using ConfigureAwait(false) and then trying to use HttpContext.Current is likely going to result in problems.
In contrast, general-purpose libraries are “general purpose” in part because they don’t care about the environment in which they’re used. You can use them from a web app or from a client app or from a test, it doesn’t matter, as the library code is agnostic to the app model it might be used in. Being agnostic then also means that it’s not going to be doing anything that needs to interact with the app model in a particular way, e.g. it won’t be accessing UI controls, because a general-purpose library knows nothing about UI controls. Since we then don’t need to be running the code in any particular environment, we can avoid forcing continuations/callbacks back to the original context, and we do that by using ConfigureAwait(false) and gaining both the performance and reliability benefits it brings. This leads to the general guidance of: if you’re writing general-purpose library code, use ConfigureAwait(false). This is why, for example, you’ll see every (or almost every) await in the .NET Core runtime libraries using ConfigureAwait(false) on every await; with a few exceptions, in cases where it doesn’t it’s very likely a bug to be fixed. For example, this PR fixed a missing ConfigureAwait(false) call in HttpClient.
As with all guidance, of course, there can be exceptions, places where it doesn’t make sense. For example, one of the larger exemptions (or at least categories that requires thought) in general-purpose libraries is when those libraries have APIs that take delegates to be invoked. In such cases, the caller of the library is passing potentially app-level code to be invoked by the library, which then effectively renders those “general purpose” assumptions of the library moot. Consider, for example, an asynchronous version of LINQ’s Where method, e.g. public static async IAsyncEnumerable<T> WhereAsync(this IAsyncEnumerable<T> source, Func<T, bool> predicate). Does predicate here need to be invoked back on the original SynchronizationContext of the caller? That’s up to the implementation of WhereAsync to decide, and it’s a reason it may choose not to use ConfigureAwait(false).
Even with these special cases, the general guidance stands and is a very good starting point: use ConfigureAwait(false) if you’re writing general-purpose library / app-model-agnostic code, and otherwise don’t.
Does ConfigureAwait(false) guarantee the callback won’t be run in the original context?
No. It guarantees it won’t be queued back to the original context… but that doesn’t mean the code after an await task.ConfigureAwait(false) won’t still run in the original context. That’s because awaits on already-completed awaitables just keep running past the await synchronously rather than forcing anything to be queued back. So, if you await a task that’s already completed by the time it’s awaited, regardless of whether you used ConfigureAwait(false), the code immediately after this will continue to execute on the current thread in whatever context is still current.
Is it ok to use ConfigureAwait(false) only on the first await in my method and not on the rest?
In general, no. See the previous FAQ. If the await task.ConfigureAwait(false) involves a task that’s already completed by the time it’s awaited (which is actually incredibly common), then the ConfigureAwait(false) will be meaningless, as the thread continues to execute code in the method after this and still in the same context that was there previously.
One notable exception to this is if you know that the first await will always complete asynchronously and the thing being awaited will invoke its callback in an environment free of a custom SynchronizationContext or a TaskScheduler. For example, CryptoStream in the .NET runtime libraries wants to ensure that its potentially computationally-intensive code doesn’t run as part of the caller’s synchronous invocation, so it uses a custom awaiter to ensure that everything after the first await runs on a thread pool thread. However, even in that case you’ll notice that the next await still uses ConfigureAwait(false); technically that’s not necessary, but it makes code review a lot easier, as otherwise every time this code is looked at it doesn’t require an analysis to understand why ConfigureAwait(false) was left off.
Can I use Task.Run to avoid using ConfigureAwait(false)?
Yes. If you write:
Task.Run(async delegate
{
await SomethingAsync(); // won't see the original context
});
then a ConfigureAwait(false) on that SomethingAsync() call will be a nop, because the delegate passed to Task.Run is going to be executed on a thread pool thread, with no user code higher on the stack, such that SynchronizationContext.Current will return null. Further, Task.Run implicitly uses TaskScheduler.Default, which means querying TaskScheduler.Current inside of the delegate will also return Default. That means the await will exhibit the same behavior regardless of whether ConfigureAwait(false) was used. It also doesn’t make any guarantees about what code inside of this lambda might do. If you have the code:
Task.Run(async delegate
{
SynchronizationContext.SetSynchronizationContext(new SomeCoolSyncCtx());
await SomethingAsync(); // will target SomeCoolSyncCtx
});
then the code inside SomethingAsync will in fact see SynchronizationContext.Current as that SomeCoolSyncCtx instance, and both this await and any non-configured awaits inside SomethingAsync will post back to it. So to use this approach, you need to understand what all of the code you’re queueing may or may not do and whether its actions could thwart yours.
This approach also comes at the expense of needing to create/queue an additional task object. That may or may not matter to your app or library depending on your performance sensitivity.
Also keep in mind that such tricks may cause more problems than they’re worth and have other unintended consequences. For example, static analysis tools (e.g. Roslyn analyzers) have been written to flag awaits that don’t use ConfigureAwait(false), such as CA2007. If you enable such an analyzer but then employ a trick like this just to avoid using ConfigureAwait, there’s a good chance the analyzer will flag it, and actually cause more work for you. So maybe you then disable the analyzer because of its noisiness, and now you end up missing other places in the codebase where you actually should have been using ConfigureAwait(false).
Can I use SynchronizationContext.SetSynchronizationContext to avoid using ConfigureAwait(false)?
No. Well, maybe. It depends on the involved code.
Some developers write code like this:
Task t;
SynchronizationContext old = SynchronizationContext.Current;
SynchronizationContext.SetSynchronizationContext(null);
try
{
t = CallCodeThatUsesAwaitAsync(); // awaits in here won't see the original context
}
finally { SynchronizationContext.SetSynchronizationContext(old); }
await t; // will still target the original context
in hopes that it’ll make the code inside CallCodeThatUsesAwaitAsync see the current context as null. And it will. However, the above will do nothing to affect what the await sees for TaskScheduler.Current, so if this code is running on some custom TaskScheduler, awaits inside CallCodeThatUsesAwaitAsync (and that don’t use ConfigureAwait(false)) will still see and queue back to that custom TaskScheduler.
All of the same caveats also apply as in the previous Task.Run-related FAQ: there are perf implications of such a workaround, and the code inside the try could also thwart these attempts by setting a different context (or invoking code with a non-default TaskScheduler).
With such a pattern, you also need to be careful about a slight variation:
SynchronizationContext old = SynchronizationContext.Current;
SynchronizationContext.SetSynchronizationContext(null);
try
{
await t;
}
finally { SynchronizationContext.SetSynchronizationContext(old); }
See the problem? It’s a bit hard to see but also potentially very impactful. There’s no guarantee that the await will end up invoking the callback/continuation on the original thread, which means the resetting of the SynchronizationContext back to the original may not actually happen on the original thread, which could lead subsequent work items on that thread to see the wrong context (to counteract this, well-written app models that set a custom context generally add code to manually reset it before invoking any further user code). And even if it does happen to run on the same thread, it may be a while before it does, such that the context won’t be appropriately restored for a while. And if it runs on a different thread, it could end up setting the wrong context onto that thread. And so on. Very far from ideal.
I’m using GetAwaiter().GetResult(). Do I need to use ConfigureAwait(false)?
No. ConfigureAwait only affects the callbacks. Specifically, the awaiter pattern requires awaiters to expose an IsCompleted property, a GetResult method, and an OnCompleted method (optionally with an UnsafeOnCompleted method). ConfigureAwait only affects the behavior of {Unsafe}OnCompleted, so if you’re just directly calling to the awaiter’s GetResult() method, whether you’re doing it on the TaskAwaiter or the ConfiguredTaskAwaitable.ConfiguredTaskAwaiter makes zero behavior difference. So, if you see task.ConfigureAwait(false).GetAwaiter().GetResult() in code, you can replace it with task.GetAwaiter().GetResult() (and also consider whether you really want to be blocking like that).
I know I’m running in an environment that will never have a custom SynchronizationContext or custom TaskScheduler. Can I skip using ConfigureAwait(false)?
Maybe. It depends on how sure you are of the “never” part. As mentioned in previous FAQs, just because the app model you’re working in doesn’t set a custom SynchronizationContext and doesn’t invoke your code on a custom TaskScheduler doesn’t mean that some other user or library code doesn’t. So you need to be sure that’s not the case, or at least recognize the risk if it may be.
I’ve heard ConfigureAwait(false) is no longer necessary in .NET Core. True?
False. It’s needed when running on .NET Core for exactly the same reasons it’s needed when running on .NET Framework. Nothing’s changed in that regard.
What has changed, however, is whether certain environments publish their own SynchronizationContext. In particular, whereas the classic ASP.NET on .NET Framework has its own SynchronizationContext, in contrast ASP.NET Core does not. That means that code running in an ASP.NET Core app by default won’t see a custom SynchronizationContext, which lessens the need for ConfigureAwait(false) running in such an environment.
It doesn’t mean, however, that there will never be a custom SynchronizationContext or TaskScheduler present. If some user code (or other library code your app is using) sets a custom context and calls your code, or invokes your code in a Task scheduled to a custom TaskScheduler, then even in ASP.NET Core your awaits may see a non-default context or scheduler that would lead you to want to use ConfigureAwait(false). Of course, in such situations, if you avoid synchronously blocking (which you should avoid doing in web apps regardless) and if you don’t mind the small performance overheads in such limited occurrences, you can probably get away without using ConfigureAwait(false).
Can I use ConfigureAwait when ‘await foreach’ing an IAsyncEnumerable?
Yes. See this MSDN Magazine article for an example.
await foreach binds to a pattern, and so while it can be used to enumerate an IAsyncEnumerable<T>, it can also be used to enumerate something that exposes the right API surface area. The .NET runtime libraries include a ConfigureAwait extension method on IAsyncEnumerable<T> that returns a custom type that wraps the IAsyncEnumerable<T> and a Boolean and exposes the right pattern. When the compiler generates calls to the enumerator’s MoveNextAsync and DisposeAsync methods, those calls are to the returned configured enumerator struct type, and it in turns performs the awaits in the desired configured way.
Can I use ConfigureAwait when ‘await using’ an IAsyncDisposable?
Yes, though with a minor complication.
As with IAsyncEnumerable<T> described in the previous FAQ, the .NET runtime libraries expose a ConfigureAwait extension method on IAsyncDisposable, and await using will happily work with this as it implements the appropriate pattern (namely exposing an appropriate DisposeAsync method):
await using (var c = new MyAsyncDisposableClass().ConfigureAwait(false))
{
...
}
The problem here is that the type of c is now not MyAsyncDisposableClass but rather a System.Runtime.CompilerServices.ConfiguredAsyncDisposable, which is the type returned from that ConfigureAwait extension method on IAsyncDisposable.
To get around that, you need to write one extra line:
var c = new MyAsyncDisposableClass();
await using (c.ConfigureAwait(false))
{
...
}
Now the type of c is again the desired MyAsyncDisposableClass. This also has the effect of increasing the scope of c; if that’s impactful, you can wrap the whole thing in braces.
I used ConfigureAwait(false), but my AsyncLocal still flowed to code after the await. Is that a bug?
No, that is expected. AsyncLocal<T> data flows as part of ExecutionContext, which is separate from SynchronizationContext. Unless you’ve explicitly disabled ExecutionContext flow with ExecutionContext.SuppressFlow(), ExecutionContext (and thus AsyncLocal<T> data) will always flow across awaits, regardless of whether ConfigureAwait is used to avoid capturing the original SynchronizationContext. For more information, see this blog post.
Could the language help me avoid needing to use ConfigureAwait(false) explicitly in my library?
Library developers sometimes express their frustration with needing to use ConfigureAwait(false) and ask for less invasive alternatives.
Currently there aren’t any, at least not built into the language / compiler / runtime. There are however numerous proposals for what such a solution might look like, e.g. https://github.com/dotnet/csharplang/issues/645, https://github.com/dotnet/csharplang/issues/2542, https://github.com/dotnet/csharplang/issues/2649, and https://github.com/dotnet/csharplang/issues/2746.
If this is important to you, or if you feel like you have new and interesting ideas here, I encourage you to contribute your thoughts to those or new discussions.
The post ConfigureAwait FAQ appeared first on .NET Blog.